Apache ShardingSphere verteiltes Datenbank-Mittelschicht-Ökosystem v5.5.0
5.5.0
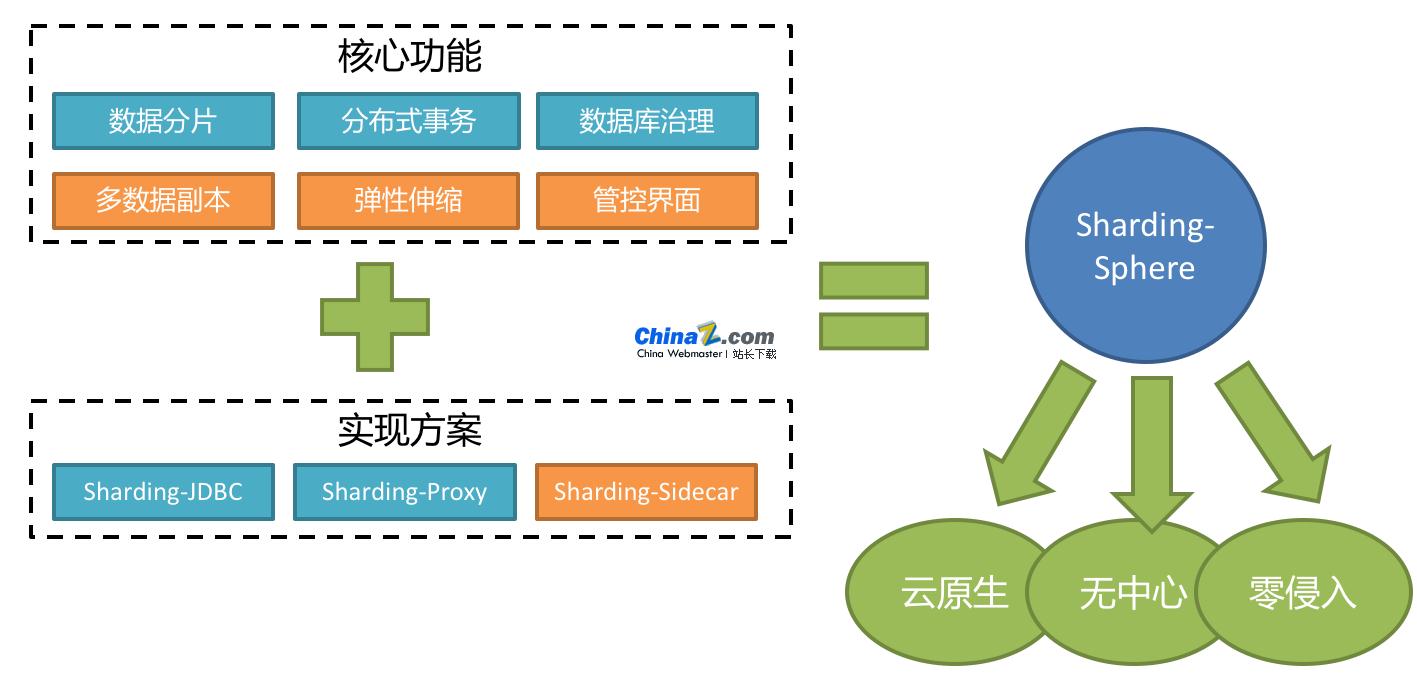
Apache ShardingSphere ist ein Ökosystem, das aus einer Reihe verteilter Open-Source-Datenbank-Middleware-Lösungen besteht. Es besteht aus JDBC, Proxy und Sidecar (in Planung), drei Produkten, die unabhängig voneinander sind, aber zusammen bereitgestellt und verwendet werden können. Sie alle bieten standardisiertes Daten-Sharding, verteilte Transaktionen und Datenbankverwaltungsfunktionen und können auf verschiedene Anwendungsszenarien wie Java-Isomorphismus, heterogene Sprachen, Cloud-nativ usw. angewendet werden.
Apache ShardingSphere ist als relationale Datenbank-Middleware positioniert und zielt darauf ab, die Rechen- und Speicherkapazitäten relationaler Datenbanken in verteilten Szenarien vollständig und sinnvoll zu nutzen, anstatt eine neue relationale Datenbank zu implementieren. Es fängt die Essenz der Dinge ein, indem es sich auf das Unveränderliche konzentriert. Relationale Datenbanken nehmen auch heute noch einen riesigen Markt ein und sind der Eckpfeiler des Kerngeschäfts jedes Unternehmens. Sie werden in Zukunft nur schwer zu erschüttern sein. Derzeit konzentrieren wir uns eher auf Inkremente, die auf der ursprünglichen Grundlage basieren, als auf Subversion.
Apache ShardingSphere 5.x begann sich auf eine steckbare Architektur zu konzentrieren, und die Funktionskomponenten des Projekts können auf steckbare Weise flexibel erweitert werden. Derzeit sind Funktionen wie Daten-Sharding, Lese-Schreib-Trennung, mehrere Datenkopien, Datenverschlüsselung und Stresstests für Schattendatenbanken sowie die Unterstützung von SQL und Protokollen wie MySQL, PostgreSQL, SQLServer und Oracle integriert Projekt über Plug-Ins. Entwickler können ihr eigenes, einzigartiges System genau wie mit Bausteinen anpassen. Apache ShardingSphere stellt derzeit Dutzende von SPIs als Systemerweiterungspunkte bereit, und es kommen noch weitere hinzu.
ShardingSphere-JDBC
Als leichtes Java-Framework positioniert, bietet es zusätzliche Dienste in der JDBC-Schicht von Java. Es nutzt den Client, um eine direkte Verbindung zur Datenbank herzustellen und stellt Dienste in Form von JAR-Paketen ohne zusätzliche Bereitstellung und Abhängigkeiten bereit. Es kann als erweiterte Version des JDBC-Treibers verstanden werden und ist vollständig kompatibel mit JDBC und verschiedenen ORM-Frameworks.
Anwendbar auf jedes JDBC-basierte ORM-Framework, z. B. JPA, Hibernate, Mybatis, Spring JDBC-Vorlage oder direkte Verwendung von JDBC.
Unterstützt alle Datenbankverbindungspools von Drittanbietern, z. B. DBCP, C3P0, BoneCP, Druid, HikariCP usw.
Unterstützt jede Datenbank, die die JDBC-Spezifikation implementiert. Derzeit werden MySQL, Oracle, SQLServer, PostgreSQL und jede Datenbank unterstützt, die dem SQL92-Standard folgt.
ShardingSphere-Proxy
Als transparenter Datenbankagent positioniert, stellt er einen Server bereit, der das Datenbank-Binärprotokoll kapselt, um heterogene Sprachen zu unterstützen. Derzeit werden MySQL und PostgreSQL bereitgestellt. Es kann jeden Zugriffsclient verwenden, der mit dem MySQL/PostgreSQL-Protokoll kompatibel ist (z. B. MySQL Command Client, MySQL Workbench, Navicat usw.), was es für Datenbankadministratoren benutzerfreundlicher macht.
Es ist für die Anwendung völlig transparent und kann direkt als MySQL/PostgreSQL-Server verwendet werden.
Anwendbar auf jeden Client, der mit dem MySQL/PostgreSQL-Protokoll kompatibel ist.
ShardingSphere-Sidecar (TODO)
Als Cloud-nativer Datenbank-Proxy für Kubernetes positioniert, leitet er den gesamten Zugriff auf die Datenbank in Form von Sidecar weiter. Eine zentrumslose Zero-Intrusion-Lösung bietet eine Eingriffsschicht, die mit der Datenbank interagiert, nämlich Database Mesh, auch bekannt als Database Grid.
Der Schwerpunkt von Database Mesh liegt auf der organischen Verbindung verteilter Datenzugriffsanwendungen und Datenbanken. Der Schwerpunkt liegt mehr auf der Interaktion und der effektiven Sortierung der Interaktionen zwischen chaotischen Anwendungen und Datenbanken. Mithilfe von Database Mesh bilden Anwendungen und Datenbanken, die auf die Datenbank zugreifen, letztendlich ein riesiges Grid-System. Anwendungen und Datenbanken müssen nur im Grid-System registriert werden. Sie sind allesamt Objekte, die von der Meshing-Ebene verwaltet werden.
Hybridarchitektur
ShardingSphere-JDBC verwendet eine dezentrale Architektur und eignet sich für leistungsstarke, leichtgewichtige OLTP-Anwendungen, die in Java entwickelt wurden. ShardingSphere-Proxy bietet Unterstützung für statische Eingaben und heterogene Sprachen und eignet sich für OLAP-Anwendungen sowie für die Verwaltung und den Betrieb von Sharding-Datenbanken.
Apache ShardingSphere ist ein Ökosystem, das aus mehreren Zugangsterminals besteht. Durch die Kombination von ShardingSphere-JDBC und ShardingSphere-Proxy und die Verwendung desselben Registrierungszentrums zur einheitlichen Konfiguration von Sharding-Strategien können für verschiedene Szenarien geeignete Anwendungssysteme flexibel erstellt werden, sodass Architekten das beste System freier an die aktuelle Geschäftsarchitektur anpassen können.
1. Datenfragmentierung
Unterbibliothek und Untertisch
Lese- und Schreibtrennung
Anpassung der Sharding-Strategie
Nicht zentralisierter verteilter Primärschlüssel
2. Verteilte Transaktionen
Standardisierte Transaktionsschnittstelle
XA stark konsistente Transaktionen
Flexible Angelegenheiten
3. Datenbankverwaltung
Verteilte Governance
Elastische Skalierung
Beobachtbarkeit (verteiltes Tracing, Metriken)
Datenverschlüsselung und -entschlüsselung
Schattendrucktest