Offizielle Version des Apache Kylin Analytical Data Warehouse v4.0.3
4.0.3
Apache Kylin: Ein Abfragetool in Sekundenschnelle für extrem große Datenmengen
Downcodes-Editor
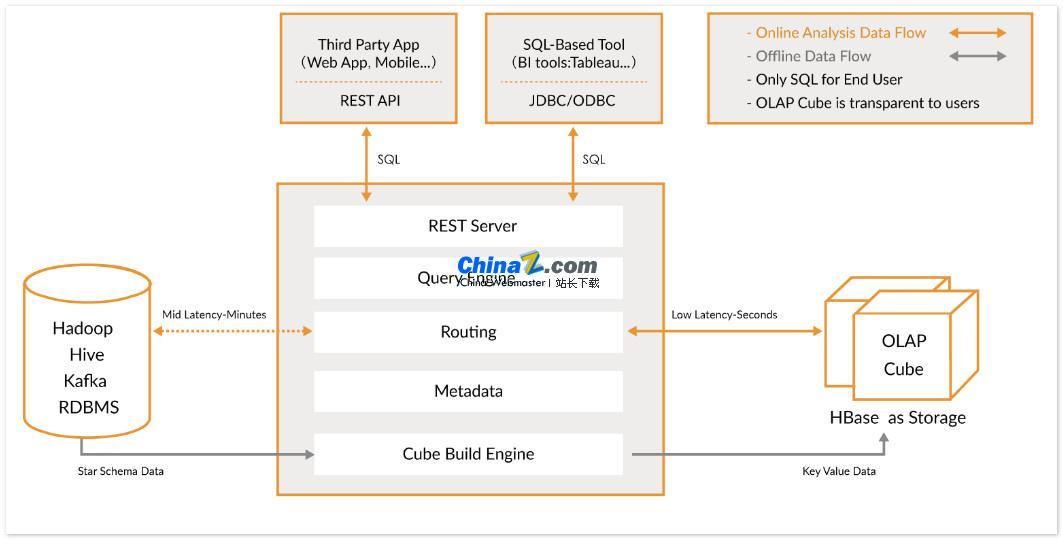
Apache Kylin ist ein verteiltes analytisches Open-Source-Data-Warehouse, das zusätzlich zu Hadoop/Spark eine SQL-Abfrageschnittstelle und Funktionen für die mehrdimensionale Analyse (OLAP) bietet und extrem große Datenmengen effizient verarbeiten kann. Ursprünglich von eBay entwickelt und zur Open-Source-Community beigetragen, erledigt es Abfragen zu riesigen Datenmengen in Sekundenbruchteilen.
Kylins drei große Schritte
Mit Kylin können Benutzer in nur drei Schritten Abfragen in Sekundenschnelle für sehr große Datensätze implementieren:
1. Definieren Sie ein Stern- oder Schneeflockenmodell für Ihren Datensatz: Zunächst müssen Sie ein Stern- oder Schneeflockenmodell definieren, um Ihren Datensatz zu beschreiben. Dies wird Kylin helfen, die Beziehung zwischen Daten zu verstehen und dadurch die Abfrageleistung zu optimieren.
2. Build Cube: Build Cube für die definierte Datentabelle ist die Einheit für Kylin, um Daten vorab zu berechnen und zu speichern, was die Abfragegeschwindigkeit erheblich verbessern kann.
3. Standard-SQL-Abfrage verwenden: Verwenden Sie die Standard-SQL-Syntax, um Cube über ODBC, JDBC oder RESTFUL API abzufragen. Kylin kann Abfrageergebnisse in Sekundenschnelle zurückgeben.
Kylins Integrationsfähigkeiten
Kylin lässt sich in eine Vielzahl von Datenvisualisierungstools wie Tableau, Power BI usw. integrieren. Benutzer können diese BI-Tools verwenden, um Hadoop-Daten zu analysieren und Datenerkenntnisse visuell darzustellen.
Zusammenfassen
Apache Kylin ist ein leistungsstarkes Tool, das Benutzern dabei helfen kann, Abfragen für extrem große Datenmengen in Sekundenbruchteilen durchzuführen. Aufgrund seiner Benutzerfreundlichkeit, Skalierbarkeit und Effizienz eignet es sich ideal für die Durchführung umfangreicher Datenanalysen.