effizienter Sprachdetektor
3.0.0
Der effiziente Sprachdetektor ( Nito-ELD oder ELD ) ist eine schnelle und genaue Software zur Erkennung natürlicher Sprache, die zu 100 % in PHP geschrieben ist, mit einer Geschwindigkeit, die mit schnellen C++-kompilierten Detektoren vergleichbar ist, und einer Genauigkeit, die im Bereich der bisher besten Detektoren liegt.
Es gibt keine Abhängigkeiten, die Installation ist einfach, es wird lediglich PHP mit der MB- Erweiterung benötigt.
ELD ist auch (veraltete Versionen) in Javascript und Python verfügbar.
Installation
Wie zu verwenden
Benchmarks
Datenbanken
Testen
Sprachen
Änderungen von ELD v2 zu v3:
„detekt()->Sprache“ gibt jetzt die Zeichenfolge
'und'für unbestimmt stattNULLzurückDatenbanken sind nicht kompatibel und größer, mittel v2 ≈ klein v3
Die Funktion „dynamicLangSubset()“ wurde entfernt
Die Funktion cleanText() heißt jetzt enableTextCleanup()
$ Composer benötigt nitotm/efficient-Language-Detector
--prefer-dist lässt tests/ , misc/ & benchmark/ weg oder verwendet --prefer-source um alles einzuschließen
Installieren Sie nitotm/efficient-language-detector:dev-main um die letzten instabilen Änderungen auszuprobieren
Alternativ kann das Herunterladen/Klonen der Dateien problemlos funktionieren.
(Nur kleine DB-Installation im Aufbau)
Es wird empfohlen, OPcache zu verwenden, insbesondere für größere Datenbanken, um die Ladezeiten zu verkürzen.
Wir müssen opcache.interned_strings_buffer und opcache.memory_consumption für jede Datenbank hoch genug einstellen
Empfohlener Wert in Klammern. Weitere Informationen finden Sie in den Datenbanken.
| php.ini-Einstellung | Klein | Medium | Groß | Extragroß |
|---|---|---|---|---|
memory_limit | >= 128 | >= 340 | >= 1060 | >= 2200 |
opcache.interned... | >= 8 (16) | >= 16 (32) | >= 60 (70) | >= 116 (128) |
opcache.memory | >= 64 (128) | >= 128 (230) | >= 360 (450) | >= 750 (820) |
detect() erwartet eine UTF-8-Zeichenfolge und gibt ein Objekt mit einer language zurück, die einen ISO 639-1- Code (oder ein anderes ausgewähltes Format) oder 'und' für eine unbestimmte Sprache enthält.
// require_once 'manual_loader.php'; ELD ohne Autoloader laden. Update path.use NitotmEld{LanguageDetector, EldDataFile, EldFormat};// LanguageDetector(databaseFile: ?string, outputFormat: ?string)$eld = new LanguageDetector(EldDataFile::SMALL, EldFormat::ISO639_1);// Datenbankdateien: ' klein“, „mittel“, „groß“, „extragroß“. Speicherbedarf prüfen // Formate: 'ISO639_1', 'ISO639_2T', 'ISO639_1_BCP47', 'ISO639_2T_BCP47' und 'FULL_TEXT' // Konstanten sind nicht obligatorisch, LanguageDetector('small', 'ISO639_1'); wird auch funktionieren$eld->detect('Hola, cómo te llamas?');// object( language => string, scores() => array, isReliable() => bool )// ( language => 'es', scores() => ['es' => 0.25, 'nl' => 0.05], isReliable() => true )$eld->detect('Hola, cómo te llamas?') ->Sprache;// 'es' Durch einmaliges Aufrufen von langSubset() wird die Teilmenge festgelegt. Der erste Aufruf dauert länger, da eine neue Datenbank erstellt wird. Wenn Sie die Datenbankdatei speichern (Standard), wird sie das nächste Mal geladen, wenn wir dieselbe Teilmenge erstellen.
Um eine Teilmenge ohne zusätzlichen Aufwand zu verwenden, besteht die richtige Vorgehensweise darin, den Detektor mit der von langSubset() gespeicherten und zurückgegebenen Datei zu instanziieren. Überprüfen Sie unten die verfügbaren Sprachen.
// Es akzeptiert immer ISO 639-1-Codes sowie das ausgewählte Ausgabeformat, falls unterschiedlich.// langSubset(sprachen: [], save: true, encode: true); Gibt den Dateinamen der Teilmenge zurück, wenn er gespeichert wird => ?array, error => ?string, file => ?string )// ( success => true, language => ['en', 'es'...], error => NULL, file => ' small_6_mfss...' )// um die Teilmenge zu entfernen$eld->langSubset();// Der beste und schnellste Weg, eine Teilmenge zu verwenden, besteht darin, sie wie eine Standarddatenbank zu laden$eld_subset = new NitotmEldLanguageDetector('small_6_mfss5z1t' );// wenn enableTextCleanup(True), discover() entfernt URLs, .com-Domänen, E-Mails, alphanumerische Zeichen...// Nicht empfohlen, da URLs und Domänen Hinweise auf eine Sprache enthalten, was die Genauigkeit verbessern könnte$eld->enableTextCleanup(true ); // Standard ist false// Bei Bedarf können wir Informationen zur ELD-Instanz abrufen: Sprachen, Datenbanktyp usw.$eld->info();
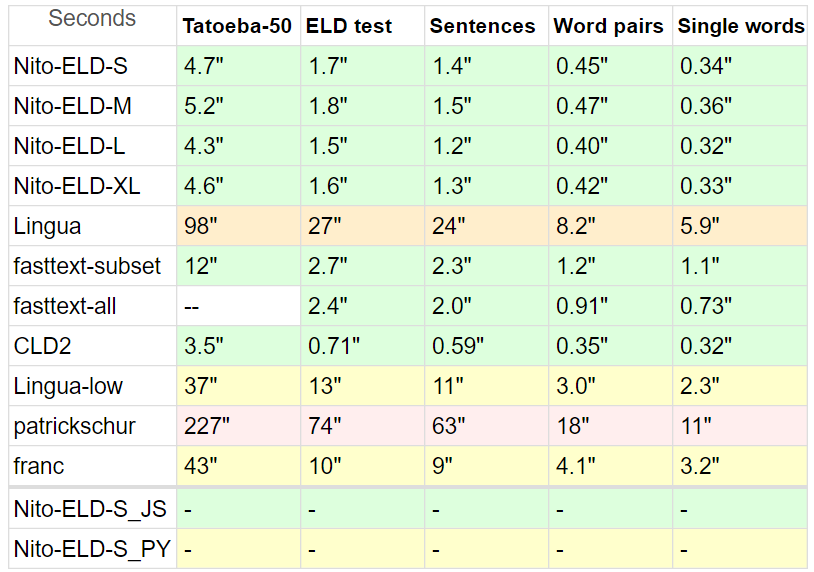
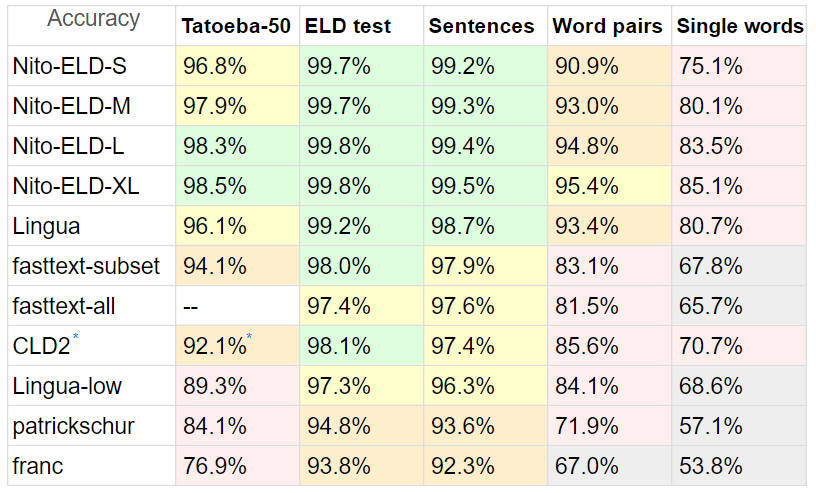
Ich habe ELD mit einer anderen Art von Detektoren verglichen, da es in PHP nicht viele davon gibt.
| URL | Version | Sprache |
|---|---|---|
| https://github.com/nitotm/efficient-lingual-detector/ | 3.0.0 | PHP |
| https://github.com/pemistahl/lingua-py | 2.0.2 | Python |
| https://github.com/facebookresearch/fastText | 0.9.2 | C++ |
| https://github.com/CLD2Owners/cld2 | 21. August 2015 | C++ |
| https://github.com/patrickschur/lingual-detection | 5.3.0 | PHP |
| https://github.com/wooorm/franc | 7.2.0 | Javascript |
Benchmarks:
Tatoeba : 20 MB , kurze Sätze von Tatoeba, 50 von allen Teilnehmern unterstützte Sprachen, jeweils bis zu 10.000 Zeilen.
Für Tatoeba habe ich alle Detektoren auf die Teilmenge von 50 Sprachen beschränkt, um den Vergleich so fair wie möglich zu gestalten.
Außerdem ist Tatoeba nicht Teil des ELD- Trainingsdatensatzes (und auch nicht des Tunings), sondern für Fasttext
ELD-Test : 10 MB , Sätze aus den 60 von ELD unterstützten Sprachen, jeweils 1000 Zeilen. Aus den 60 GB ELD-Trainingsdaten extrahiert.
Sätze : 8 MB , Sätze aus dem Lingua- Benchmark, abzüglich nicht unterstützter Sprachen und Yoruba, die fehlerhafte Zeichen hatten.
Wortpaare 1,5 MB und einzelne Wörter 870 KB , ebenfalls aus Lingua, dieselben 53 Sprachen.


Lingua beteiligt sich mit 54 Sprachen, Franc mit 58, Patrickschur mit 54.
Fasttext verfügt nicht über eine integrierte Teilmengenoption. Um die Genauigkeit und das Geschwindigkeitspotenzial zu zeigen, habe ich zwei Benchmarks erstellt, wobei fasttext-all bei keinem Test durch eine Teilmenge eingeschränkt wurde
* Dem CLD2 von Google fehlt auch die Teilmengenoption, und es ist selbst mit der Option bestEffort = True schwierig, eine Teilmenge zu erstellen, da sie normalerweise nur eine Sprache zurückgibt, sodass sie einen vergleichsweisen Nachteil hat.
Die Zeit ist normalisiert: (Gesamtzeilen * Zeit) / verarbeitete Zeilen
| Klein | Medium | Groß | Extragroß | |
|---|---|---|---|---|
| Vorteile | Geringster Speicher | Ausgeglichen | Am schnellsten | Am genauesten |
| Nachteile | Am wenigsten genau | Am langsamsten (aber schnell) | Hoher Speicher | Höchster Speicher |
| Dateigröße | 3 MB | 10 MB | 32 MB | 71 MB |
| Speichernutzung | 76 MB | 280 MB | 977 MB | 2083 MB |
| Speichernutzung im Cache | 0,4 MB + OP | 0,4 MB + OP | 0,4 MB + OP | 0,4 MB + OP |
| OPcache hat Speicher verwendet | 21 MB | 69 MB | 244 MB | 539 MB |
| OPcache wird intern verwendet | 4 MB | 10 MB | 45 MB | 98 MB |
| Ladezeit Nicht zwischengespeichert | 0,14 Sek | 0,5 Sek | 1,5 Sek | 3,4 Sek |
| Ladezeit im Cache | 0,0002 Sek | 0,0002 Sek | 0,0002 Sek | 0,0002 Sek |
| Einstellungen (empfohlen) | ||||
memory_limit | >= 128 | >= 340 | >= 1060 | >= 2200 |
opcache.interned... * | >= 8 (16) | >= 16 (32) | >= 60 (70) | >= 116 (128) |
opcache.memory | >= 64 (128) | >= 128 (230) | >= 360 (450) | >= 750 (820) |
* Ich empfehle, mehr als genug interned_strings_buffer zu verwenden, da ein Pufferüberlauffehler die Serverantwort verzögern kann.
Um alle Datenbanken nutzen zu können, sollte opcache.interned_strings_buffer mindestens 160 MB (170 MB) groß sein.
Beachten Sie bei der Auswahl der Speichermenge opcache.memory_consumption opcache.interned_strings_buffer enthält.
Wenn der OPcache-Speicher 230 MB beträgt, interne_strings 32 MB groß sind und die mittlere Datenbank 69 MB zwischengespeichert ist, haben wir insgesamt (230 -32 -69) = 129 MB OPcache für alles andere.
Wenn Sie zusätzlich zur Hauptdatenbank eine Teilmenge der Sprachen oder mehrere Teilmengen verwenden möchten, erhöhen Sie opcache.memory entsprechend, wenn Sie möchten, dass sie sofort geladen werden. Um alle Standarddatenbanken bequem zwischenzuspeichern, sollten Sie die Größe auf 1200 MB festlegen.
Die Standardinstallation von Composer enthält diese Dateien möglicherweise nicht. Verwenden Sie --prefer-source um sie einzubinden.
Für eine Entwicklungsumgebung mit Composer „autoload-dev“ (nur Root) werden die Tests wie folgt ausgeführt
new NitotmEldTestsTestsAutoload();
Alternativ können Sie die Tests auch mit der folgenden Datei ausführen:
$ PHP Efficient-Language-Detector/Tests/Tests.php # Pfad aktualisieren
Um die Genauigkeitsbenchmarks auszuführen, führen Sie die Datei benchmark/bench.php aus.
Dies sind die ISO 639-1-Codes , die die 60 Sprachen umfassen. Plus 'und' für unbestimmt
Es ist das Standard-ELD-Sprachformat. outputFormat: 'ISO639_1'
am, ar, az, be, bg, bn, ca, cs, da, de, el, en, es, et, eu, fa, fi, fr, gu, he, hi, hr, hu, hy, is, it, ja, ka, kn, ko, ku, lo, lt, lv, ml, mr, ms, nl, no, or, pa, pl, pt, ro, ru, sk, sl, sq, sr, sv, ta, te, th, tl, tr, uk, ur, vi, yo, zh
Dies sind die 60 unterstützten Sprachen für Nito-ELD . outputFormat: 'FULL_TEXT'
Amharisch, Arabisch, Aserbaidschanisch (Latein), Weißrussisch, Bulgarisch, Bengali, Katalanisch, Tschechisch, Dänisch, Deutsch, Griechisch, Englisch, Spanisch, Estnisch, Baskisch, Persisch, Finnisch, Französisch, Gujarati, Hebräisch, Hindi, Kroatisch, Ungarisch, Armenisch , Isländisch, Italienisch, Japanisch, Georgisch, Kannada, Koreanisch, Kurdisch (Arabisch), Laotisch, Litauisch, Lettisch, Malayalam, Marathi, Malaiisch (Latein), Niederländisch, Norwegisch, Oriya, Punjabi, Polnisch, Portugiesisch, Rumänisch, Russisch, Slowakisch , Slowenisch, Albanisch, Serbisch (Kyrillisch), Schwedisch, Tamilisch, Telugu, Thailändisch, Tagalog, Türkisch, Ukrainisch, Urdu, Vietnamesisch, Yoruba, Chinesisch
ISO 639-1-Codes mit IETF BCP 47-Skript-Namensschild. outputFormat: 'ISO639_1_BCP47'
am, ar, az-Latn, be, bg, bn, ca, cs, da, de, el, en, es, et, eu, fa, fi, fr, gu, he, hi, hr, hu, hy, is, it, ja, ka, kn, ko, ku-Arabisch, lo, lt, lv, ml, mr, ms-Latn, nl, no, or, pa, pl, pt, ro, ru, sk, sl, sq, sr-Cyrl, sv, ta, te, th, tl, tr, uk, ur, vi, yo, zh
ISO 639-2/T -Codes (die auch 639-3 gültig sind) outputFormat: 'ISO639_2T' . Auch mit BCP 47 ISO639_2T_BCP47 erhältlich
amh, ara, aze, bel, bul, ben, cat, ces, dan, deu, ell, eng, spa, est, eus, fas, fin, fra, guj, heb, hin, hrv, hun, hye, isl, ita, jpn, kat, kan, kor, kur, lao, lit, lav, mal, mar, msa, nld, nor, ori, pan, pol, por, ron, rus, slk, slv, sqi, srp, swe, tam, tel, tha, tgl, tur, ukr, urd, vie, yor, zho
Wenn Sie für Open-Source-Verbesserungen spenden, mich für private Änderungen beauftragen, eine alternative Datensatzschulung anfordern oder mich kontaktieren möchten, verwenden Sie bitte den folgenden Link: https://linktr.ee/nitotm