Artikel: Zur Testzeit-Zero-Shot-Generalisierung von Vision-Language-Modellen: Brauchen wir wirklich schnelles Lernen? .
Autoren: Maxime Zanella, Ismail Ben Ayed.
Dies ist das offizielle GitHub-Repository für unseren beim CVPR '24 angenommenen Artikel. In dieser Arbeit wird die MeanShift Test-Time Augmentation (MTA)-Methode vorgestellt, die Vision-Language-Modelle nutzt, ohne dass schnelles Lernen erforderlich ist. Unsere Methode erweitert ein einzelnes Bild nach dem Zufallsprinzip in N erweiterte Ansichten und wechselt dann zwischen zwei Schlüsselschritten (siehe mta.py und Details im Codeabschnitt):
In diesem Schritt wird für jede erweiterte Ansicht ein Score berechnet, um deren Relevanz und Qualität zu bewerten (Inlierness-Score).
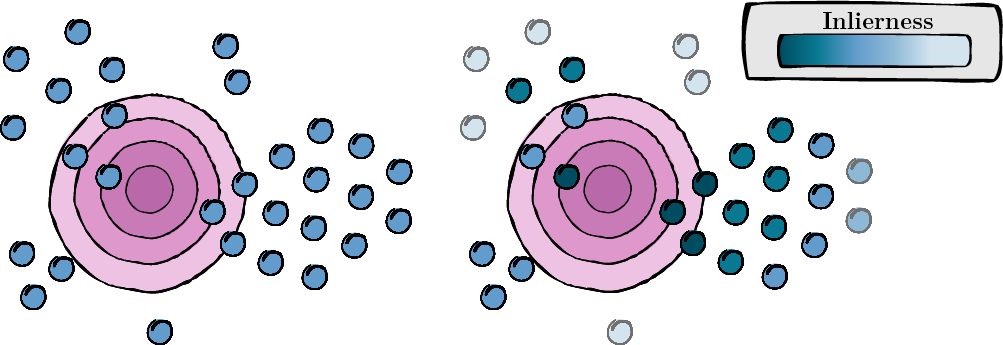
Abbildung 1: Score-Berechnung für jede erweiterte Ansicht.
Basierend auf den im vorherigen Schritt berechneten Bewertungen suchen wir nach dem Modus der Datenpunkte (MeanShift).
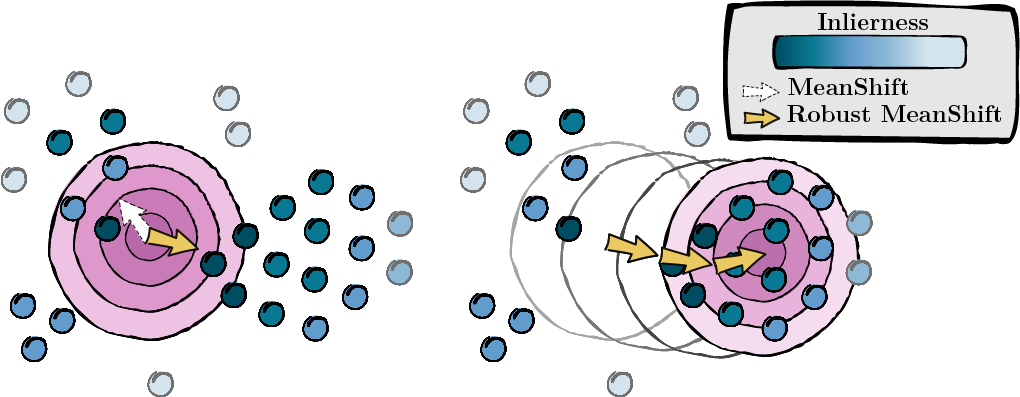
Abbildung 2: Suche nach dem Modus, gewichtet nach Inlierness-Scores.
Wir folgen der TPT-Installation und -Vorverarbeitung. Dadurch wird sichergestellt, dass Ihr Datensatz ordnungsgemäß formatiert ist. Ihr Repository finden Sie hier. Wenn es bequemer ist, können Sie die Ordnernamen jedes Datensatzes im Wörterbuch ID_to_DIRNAME in data/datautils.py (Zeile 20) ändern.
Führen Sie MTA für den ImageNet-Datensatz mit einem zufälligen Startwert von 1 und der Eingabeaufforderung „Foto eines“ aus, indem Sie den folgenden Befehl eingeben:
python main.py --data /path/to/your/data --mta --testsets I --seed 1Oder die 15 Datensätze auf einmal:
python main.py --data /path/to/your/data --mta --testsets I/A/R/V/K/DTD/Flower102/Food101/Cars/SUN397/Aircraft/Pets/Caltech101/UCF101/eurosat --seed 1Weitere Informationen zum Verfahren in mta.py.
gaussian_kernelsolve_mtay ) einheitlich fest.Wenn Sie dieses Projekt nützlich finden, zitieren Sie es bitte wie folgt:
@inproceedings { zanella2024test ,
title = { On the test-time zero-shot generalization of vision-language models: Do we really need prompt learning? } ,
author = { Zanella, Maxime and Ben Ayed, Ismail } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition } ,
pages = { 23783--23793 } ,
year = { 2024 }
}Wir danken den TPT-Autoren für ihren Open-Source-Beitrag. Ihr Repository finden Sie hier.


