Projektseite | Papier | Modellkarte?
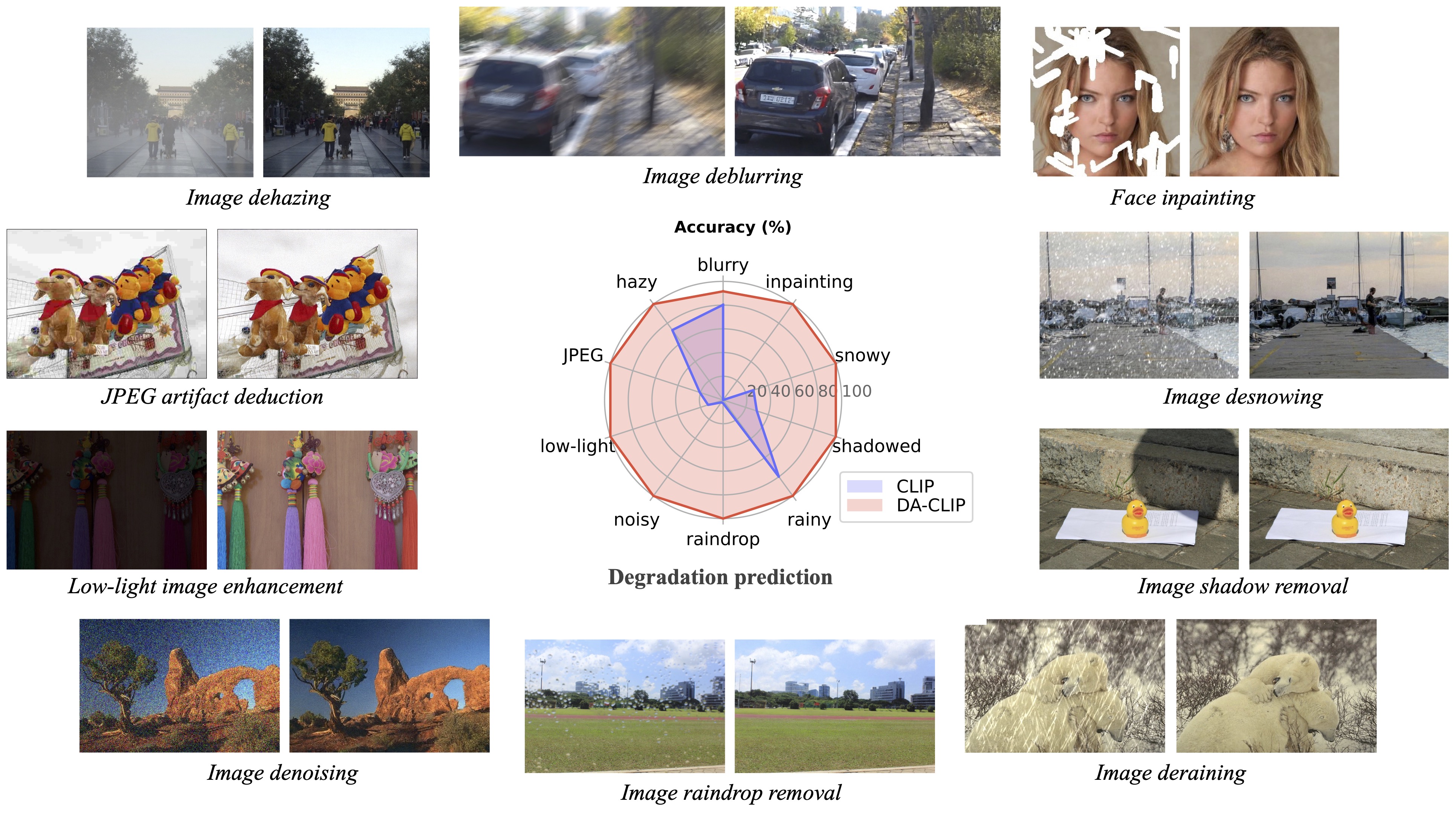
Unsere Nachfolgearbeit „Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models“ (CVPRW 2024) stellt eine hintere Stichprobe für eine bessere Bilderzeugung vor und verarbeitet reale Bilder mit gemischter Verschlechterung ähnlich wie Real-ESRGAN.
[ 16.04.2024 ] Unser Nachfolgepapier „Fotorealistische Bildwiederherstellung in freier Wildbahn mit kontrollierten Seh-Sprachmodellen“ ist jetzt auf ArXiv!
[ 15.04.2024 ] Ein Wild-IR-Modell für reale Verschlechterungen und die hintere Abtastung für eine bessere Bilderzeugung aktualisiert. Für wild-ir werden auch die vorab trainierten Gewichte wild-ir.pth und wild-daclip_ViT-L-14.pt bereitgestellt.
[ 20.01.2024 ] ??? Unser DA-CLIP-Papier wurde vom ICLR 2024 angenommen ??? Darüber hinaus stellen wir in der Modellkarte ein robusteres Modell zur Verfügung.
[ 25.10.2023 ] Datensatz-Links für Training und Tests hinzugefügt.
[ 13.10.2023 ] Replikat-Demo und API hinzugefügt. Danke an @chenxwh!!! Wir haben die Hugging Face-Demo und die Online-Colab-Demo aktualisiert. Danke an @fffiloni und @camenduru !!! Wir haben auch eine Modelkarte in Hugging Face erstellt? und lieferte weitere Beispiele zum Testen.
[ 09.10.2023 ] Die vorab trainierten Gewichte von DA-CLIP und dem Universal IR-Modell werden in Link1 bzw. Link2 veröffentlicht. Darüber hinaus stellen wir auch eine Gradio-App-Datei für den Fall zur Verfügung, dass Sie Ihre eigenen Bilder testen möchten.
Betriebssystem: Ubuntu 20.04
Nvidia:
Cuda: 11.4
Python 3.8
Wir empfehlen Ihnen, zunächst eine virtuelle Umgebung zu erstellen mit:
python3 -m venv .envsource .env/bin/activate pip install -U pip pip install -r Anforderungen.txt
Gehen Sie in das Verzeichnis universal-image-restoration und führen Sie Folgendes aus:
import Torchfrom PIL import Imageimport open_clipcheckpoint = 'pretrained/daclip_ViT-B-32.pt'model, preprocess = open_clip.create_model_from_pretrained('daclip_ViT-B-32', pretrained=checkpoint)tokenizer = open_clip.get_tokenizer('ViT-B-32 ')image = preprocess(Image.open("haze_01.png")).unsqueeze(0)degradations = ['motion-blurry','hazy','jpeg-compressed','low-light','noisy','raindrop' ,'rainy','shadowed','snowy','uncompleted']text = tokenizer(degradations)with Torch.no_grad(), Torch.cuda.amp.autocast():text_features = model.encode_text(text)image_features, degra_features = model.encode_image(image, control=True)degra_features /= degra_features.norm(dim=-1, keepdim=True)text_features / = text_features.norm(dim=-1, keepdim=True)text_probs = (100.0 * degra_features @ text_features.T).softmax(dim=-1)index = Torch.argmax(text_probs[0])print(f"Task: {task_name}: {degradations[index]} - {text_probs[0] [Index]}")Vorbereiten der Trainings- und Testdatensätze gemäß unserem Abschnitt „Datensatzkonstruktion“ wie folgt:
#### für Trainingsdatensatz ######## (unvollständig bedeutet Inpainting) ####datasets/universal/train|--motion-blurry| |--LQ/*.png| |--GT/*.png|--hazy|--jpeg-compressed|--low-light|--noisy|--raindrop|--rainy|--shadowed|--snowy|--uncompleted## ## zum Testen des Datensatzes ######## (die gleiche Struktur wie Zug) ####datasets/universal/val ...#### für saubere Untertitel ####datasets/universal/daclip_train.csv datasets/universal/daclip_val.csv
Wechseln Sie dann in das Verzeichnis universal-image-restoration/config/daclip-sde und ändern Sie die Datensatzpfade in den Optionsdateien in options/train.yml und options/test.yml .
Sie können den Verzeichnissen train “ und val weitere Aufgaben oder Datensätze hinzufügen und das Wort „degradation“ zu distortion hinzufügen.
| Abbau | Bewegungsunschärfe | dunstig | jpeg-komprimiert* | wenig Licht | laut* (dasselbe wie bei JPEG) |
|---|---|---|---|---|---|
| Datensätze | Gopro | RESIDE-6k | DIV2K+Flickr2K | LOL | DIV2K+Flickr2K |
| Abbau | Regentropfen | regnerisch | beschattet | schneebedeckt | unvollendet |
|---|---|---|---|---|---|
| Datensätze | Regentropfen | Rain100H: trainieren, testen | SRD | Schnee100K | CelebaHQ-256 |
Sie sollten die Zugdatensätze nur für das Training extrahieren . Alle Validierungsdatensätze können im Google Drive heruntergeladen werden. Für JPEG- und verrauschte Datensätze können Sie mit diesem Skript LQ-Bilder generieren.
Weitere Informationen finden Sie unter DA-CLIP.md.
Der Hauptcode für das Training befindet sich in universal-image-restoration/config/daclip-sde und das Kernnetzwerk für DA-CLIP befindet sich in universal-image-restoration/open_clip/daclip_model.py .
Legen Sie die vorab trainierten DA-CLIP-Gewichte im pretrained Verzeichnis ab und überprüfen Sie den daclip Pfad.
Anschließend können Sie das Modell mit den folgenden Bash-Skripten trainieren:
cd universal-image-restoration/config/daclip-sde# Für eine einzelne GPU:python3 train.py -opt=options/train.yml# Für verteiltes Training müssen die gpu_ids in der Option filepython3 -m Torch.distributed.launch geändert werden - -nproc_per_node=2 --master_port=4321 train.py -opt=options/train.yml --launcher pytorch
Die Modelle und Trainingsprotokolle werden in log/universal-ir gespeichert. Sie können Ihr Protokoll jederzeit ausdrucken, indem Sie tail -f log/universal-ir/train_universal-ir_***.log -n 100 ausführen.
Die gleichen Trainingsschritte können für die Bildwiederherstellung in freier Wildbahn (wild-ir) verwendet werden.
| Modellname | Beschreibung | GoogleDrive | Umarmendes Gesicht |
|---|---|---|---|
| DA-CLIP | Degradationsbewusstes CLIP-Modell | herunterladen | herunterladen |
| Universal-IR | DA-CLIP-basiertes universelles Bildwiederherstellungsmodell | herunterladen | herunterladen |
| DA-CLIP-Mix | Degradationsbewusstes CLIP-Modell (Gaußsche Unschärfe + Gesichtsinpainting und Gaußsche Unschärfe + Rainy hinzufügen) | herunterladen | herunterladen |
| Universal-IR-Mix | DA-CLIP-basiertes universelles Bildwiederherstellungsmodell (fügen Sie robustes Training und Mix-Degradationen hinzu) | herunterladen | herunterladen |
| Wild-DA-CLIP | Degradationsbewusstes CLIP-Modell in freier Wildbahn (ViT-L-14) | herunterladen | herunterladen |
| Wild-IR | DA-CLIP-basiertes Bildwiederherstellungsmodell in freier Wildbahn | herunterladen | herunterladen |
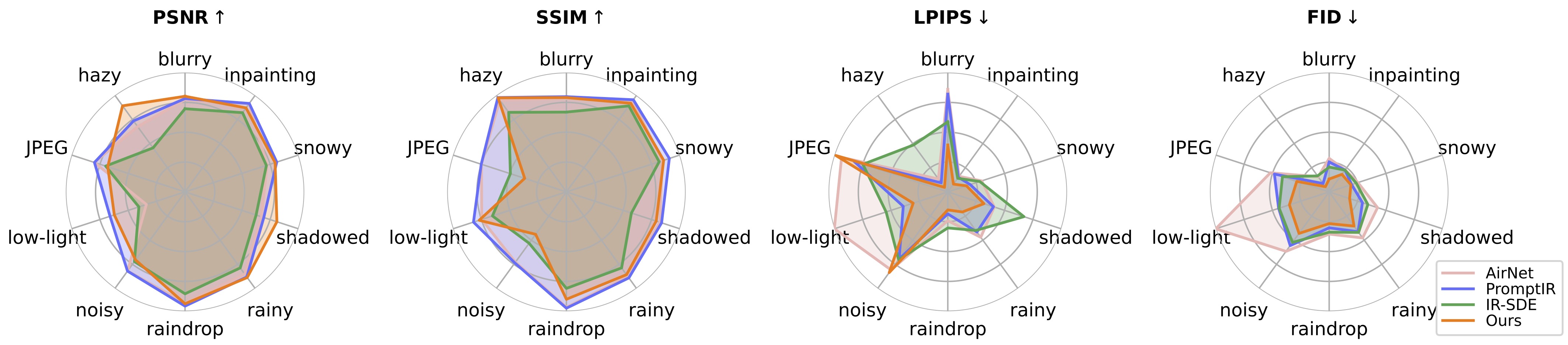
Um unsere Methode zur Bildwiederherstellung zu bewerten, ändern Sie bitte den Benchmark-Pfad und den Modellpfad und führen Sie sie aus
cd universal-image-restoration/config/universal-ir python test.py -opt=options/test.yml
Hier stellen wir eine app.py-Datei zum Testen Ihrer eigenen Bilder zur Verfügung. Zuvor müssen Sie die vorab trainierten Gewichte (DA-CLIP und UIR) herunterladen und den Modellpfad in options/test.yml ändern. Anschließend können Sie durch einfaches Ausführen von python app.py http://localhost:7860 öffnen, um das Modell zu testen. (Wir stellen auch mehrere Bilder mit unterschiedlichen Degradationen im images bereit.) Wir stellen auch weitere Beispiele aus unserem Testdatensatz im Google Drive bereit.
Die gleichen Schritte können für die Bildwiederherstellung in freier Wildbahn (Wild-IR) verwendet werden.



? Beim Testen haben wir festgestellt, dass es mit dem aktuellen vorab trainierten Modell immer noch schwierig ist, einige reale Bilder zu verarbeiten, die möglicherweise Verteilungsverschiebungen mit unserem Trainingsdatensatz aufweisen (aufgenommen von verschiedenen Geräten oder mit unterschiedlichen Auflösungen oder Verschlechterungen). Wir betrachten es als eine zukünftige Arbeit und werden versuchen, unser Modell praktischer zu machen! Wir ermutigen auch Benutzer, die an unserer Arbeit interessiert sind, ihre eigenen Modelle mit größeren Datensätzen und mehr Verschlechterungsarten zu trainieren.
? Übrigens haben wir auch festgestellt, dass die direkte Größenänderung von Eingabebildern bei den meisten Aufgaben zu einer schlechten Leistung führt . Wir könnten versuchen, den Schritt zur Größenänderung in das Training einzubauen, aber er zerstört aufgrund der Interpolation immer die Bildqualität.
? Für die Inpainting-Aufgabe unterstützt unser aktuelles Modell aufgrund der Datensatzbeschränkung nur das Inpainting von Gesichtern. Wir stellen unsere Maskenbeispiele zur Verfügung und Sie können das Skript „generate_masked_face“ verwenden, um unvollständige Gesichter zu generieren.
Danksagung: Unser DA-CLIP basiert auf IR-SDE und open_clip. Danke für ihren Code!
Wenn Sie Fragen haben, wenden Sie sich bitte an: [email protected]
Wenn unser Code Ihnen bei Ihrer Recherche oder Arbeit hilft, denken Sie bitte darüber nach, unseren Artikel zu zitieren. Im Folgenden finden Sie BibTeX-Referenzen:
@article{luo2023controlling,
title={Controlling Vision-Language Models for Universal Image Restoration},
author={Luo, Ziwei and Gustafsson, Fredrik K and Zhao, Zheng and Sj{"o}lund, Jens and Sch{"o}n, Thomas B},
journal={arXiv preprint arXiv:2310.01018},
year={2023}
}
@article{luo2024photo,
title={Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models},
author={Luo, Ziwei and Gustafsson, Fredrik K and Zhao, Zheng and Sj{"o}lund, Jens and Sch{"o}n, Thomas B},
journal={arXiv preprint arXiv:2404.09732},
year={2024}
}

