Offizielle Umsetzung von „Splatter Image: Ultra-Fast Single-View 3D Reconstruction“ (CVPR 2024)
[16. April 2024] Mehrere große Aktualisierungen des Projekts seit der ersten Veröffentlichung:
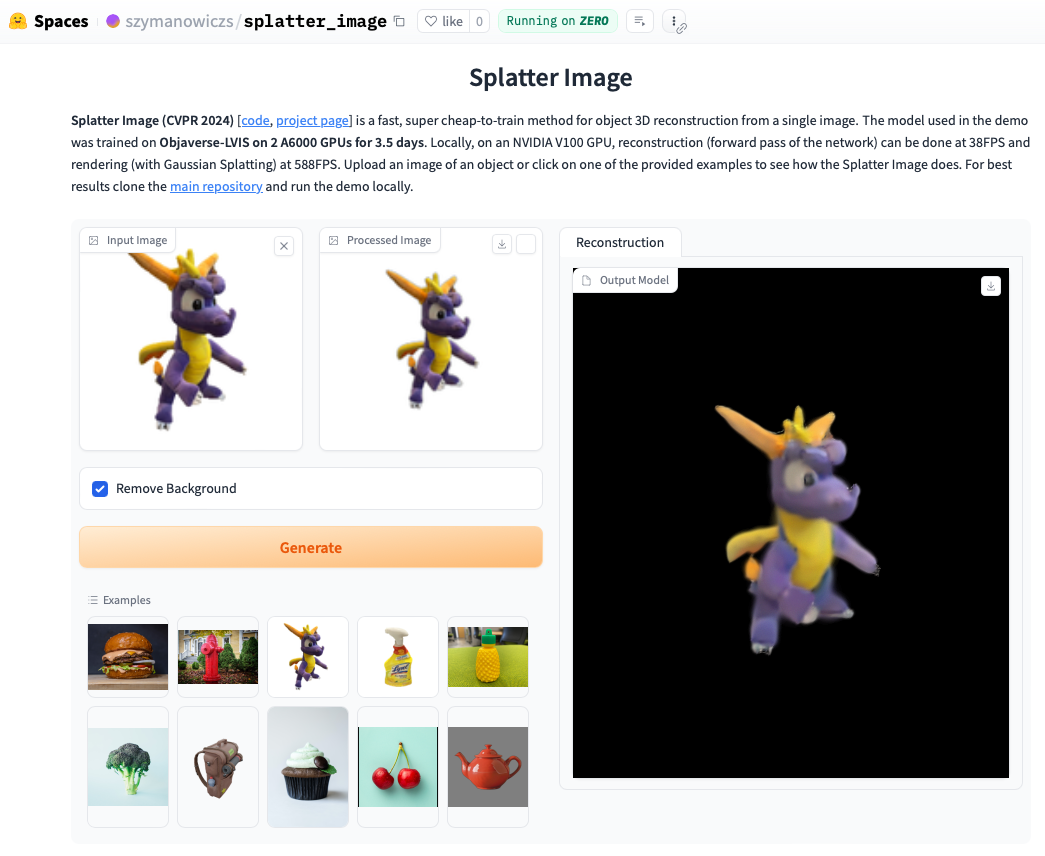
Schauen Sie sich die Online-Demo an. Das lokale Ausführen der Demo geht oft sogar noch schneller und Sie können die mit Gaussian Splatting gerenderten Schleifen sehen (im Gegensatz zum extrahierten .ply-Objekt, das Artefakte anzeigen kann). Um die Demo lokal auszuführen, befolgen Sie einfach die folgenden Installationsanweisungen und rufen Sie anschließend auf:
python gradio_app.py
conda create --name splatter-image
conda activate splatter-image
Installieren Sie Pytorch gemäß den offiziellen Anweisungen. Die nachweislich funktionierende Pytorch/Python/Pytorch3D-Kombination ist:
Installieren Sie andere Anforderungen:
pip install -r requirements.txt
Installieren Sie den Gaussian Splatting Renderer, also die Bibliothek zum Rendern einer Gaußschen Punktwolke in ein Bild. Rufen Sie dazu das Gaussian Splatting-Repository ab und führen Sie bei aktivierter Conda-Umgebung pip install submodules/diff-gaussian-rasterization aus. Sie müssen die Hardware- und Softwareanforderungen erfüllen. Wir haben alle unsere Experimente auf einer NVIDIA A6000-GPU und die Geschwindigkeitsmessungen auf einer NVIDIA V100-GPU durchgeführt.
Wenn Sie mit CO3D-Daten trainieren möchten, müssen Sie Pytorch3D 0.7.2 installieren. Anweisungen finden Sie hier. Es wird empfohlen, mit pip von einer vorgefertigten Binärdatei zu installieren. Suchen Sie hier eine kompatible Binärdatei und installieren Sie sie mit pip . Führen Sie beispielsweise mit Python 3.8, Pytorch 1.13.0 und CUDA 11.6 pip install --no-index --no-cache-dir pytorch3d -f https://anaconda.org/pytorch3d/pytorch3d/0.7.2/download/linux-64/pytorch3d-0.7.2-py38_cu116_pyt1130.tar.bz2 aus pip install --no-index --no-cache-dir pytorch3d -f https://anaconda.org/pytorch3d/pytorch3d/0.7.2/download/linux-64/pytorch3d-0.7.2-py38_cu116_pyt1130.tar.bz2 .
Für Schulungen/Bewertungen zu ShapeNet-SRN-Klassen (Autos, Stühle) laden Sie bitte die Datei srn_*.zip (* = Autos oder Stühle) aus dem PixelNeRF-Datenordner herunter. Entpacken Sie die Datendatei und ändern Sie SHAPENET_DATASET_ROOT in datasets/srn.py in den übergeordneten Ordner des entpackten Ordners. Wenn Ihre Ordnerstruktur beispielsweise wie folgt lautet: /home/user/SRN/srn_cars/cars_train , legen Sie in datasets/srn.py SHAPENET_DATASET_ROOT="/home/user/SRN" fest. Es ist keine zusätzliche Vorverarbeitung erforderlich.
Für Schulungen/Bewertungen zu CO3D laden Sie die Hydranten- und Teddybär-Kurse aus der CO3D-Version herunter. Führen Sie dazu die folgenden Befehle aus:
git clone https://github.com/facebookresearch/co3d.git
cd co3d
mkdir DOWNLOAD_FOLDER
python ./co3d/download_dataset.py --download_folder DOWNLOAD_FOLDER --download_categories hydrant,teddybear
Als nächstes legen Sie CO3D_RAW_ROOT auf Ihren DOWNLOAD_FOLDER in data_preprocessing/preoprocess_co3d.py fest. Legen Sie CO3D_OUT_ROOT auf den Ort fest, an dem Sie vorverarbeitete Daten speichern möchten. Laufen
python -m data_preprocessing.preprocess_co3d
und setzen Sie CO3D_DATASET_ROOT:=CO3D_OUT_ROOT .
Für ShapeNet mit mehreren Kategorien verwenden wir den ShapeNet 64x64-Datensatz von NMR, der von DVR-Autoren gehostet wird und hier heruntergeladen werden kann. Entpacken Sie den Ordner und setzen Sie NMR_DATASET_ROOT auf das Verzeichnis, das nach dem Entpacken die Unterkategorieordner enthält. Mit anderen Worten, das Verzeichnis NMR_DATASET_ROOT sollte die Ordner 02691156 , 02828884 , 02933112 usw. enthalten.
Für das Training auf Objaverse haben wir Renderings von Zero-1-to-3 verwendet, die mit dem folgenden Befehl heruntergeladen werden können:
wget https://tri-ml-public.s3.amazonaws.com/datasets/views_release.tar.gz
Haftungsausschluss: Beachten Sie, dass die Renderings mit Objaverse generiert werden. Die gesamten Renderings werden unter der ODC-By 1.0-Lizenz veröffentlicht. Die Lizenzen für die Darstellung einzelner Objekte werden unter derselben Creative-Commons-Lizenz veröffentlicht wie in Objaverse.
Laden Sie außerdem bitte lvis-annotations-filtered.json aus dem Modell-Repository herunter. Dieser JSON enthält die Liste der IDs von Objekten aus der LVIS-Teilmenge. Diese Vermögenswerte sind von höherer Qualität.
Setzen Sie OBJAVERSE_ROOT in datasets/objaverse.py auf das Verzeichnis des entpackten Ordners mit Renderings und legen Sie OBJAVERSE_LVIS_ANNOTATION_PATH in derselben Datei auf das Verzeichnis der heruntergeladenen .json Datei fest.
Beachten Sie, dass der Objaverse-Datensatz nur für Training und Validierung gedacht ist. Es gibt keine Testteilmenge.
Zur Bewertung des auf Objaverse trainierten Modells verwenden wir den Google Scanned Objects-Datensatz, um sicherzustellen, dass es keine Überschneidungen mit dem Trainingssatz gibt. Laden Sie von Free3D bereitgestellte Renderings herunter. Entpacken Sie den heruntergeladenen Ordner und legen Sie GSO_ROOT in datasets/gso.py auf das Verzeichnis des entpackten Ordners fest.
Beachten Sie, dass der Google Scanned Objects-Datensatz nicht für das Training gedacht ist. Es wird verwendet, um das auf Objaverse trainierte Modell zu testen.
Vorab trainierte Modelle für alle Datensätze sind jetzt über Huggingface Models verfügbar. Wenn Sie nur eine qualitative/quantitative Bewertung durchführen möchten, müssen Sie diese nicht manuell herunterladen. Sie werden automatisch verwendet, wenn Sie das Bewertungsskript ausführen (siehe unten).
Sie können sie bei Bedarf auch manuell herunterladen, indem Sie auf der Seite „Huggingface-Modelldateien“ manuell auf die Schaltfläche „Herunterladen“ klicken. Laden Sie die Konfigurationsdatei herunter und sehen Sie sich eval.py an, um zu erfahren, wie das Modell geladen wird.
Sobald Sie den entsprechenden Datensatz heruntergeladen haben, kann die Auswertung durchgeführt werden
python eval.py $dataset_name
$dataset_name ist der Name des Datensatzes. Wir unterstützen:
gso (von Google gescannte Objekte),objaverse (Objaverse-LVIS),nmr (Multi-Kategorie-ShapeNet),hydrants (CO3D-Hydranten),teddybears (CO3D-Teddybären),cars (ShapeNet-Autos),chairs (ShapeNet-Stühle). Der Code lädt automatisch das entsprechende Modell für den angeforderten Datensatz herunter.Sie können auch Ihre eigenen Modelle trainieren und damit auswerten
python eval.py $dataset_name --experiment_path $experiment_path
$experiment_path sollte eine model_latest.pth Datei und einen .hydra Ordner mit config.yaml darin enthalten.
Um die Validierungsaufteilung auszuwerten, rufen Sie mit der Option --split val auf.
Um Renderings der Objekte zu speichern, während sich die Kamera in einer Schleife bewegt, rufen Sie mit der Option --split vis auf. Bei dieser Option werden die quantitativen Bewertungen nicht zurückgegeben, da Ground-Truth-Bilder nicht in allen Datensätzen verfügbar sind.
Mit der Option --save_vis können Sie festlegen, wie viele Objekte beim Rendern gespeichert werden sollen. Mit der Option --out_folder können Sie festlegen, wo die Renderings gespeichert werden sollen.
Einzelansichtsmodelle werden in zwei Phasen trainiert, zunächst ohne LPIPS (der größte Teil des Trainings), gefolgt von der Feinabstimmung mit LPIPS.
python train_network.py +dataset=$dataset_name
opt.pretrained_ckpt (standardmäßig auf null gesetzt). python train_network.py +dataset=$dataset_name +experiment=$lpips_experiment_name
$lpips_experiment_name verwendet werden soll, hängt vom Datensatz ab. Wenn sich $dataset_name in [Autos, Hydranten, Teddybären] befindet, verwenden Sie lpips_100k.yaml. Wenn $dataset_name „chairs“ lautet, verwenden Sie lpips_200k.yaml. Wenn $dataset_name nmr ist, verwenden Sie lpips_nmr.yaml. Wenn $dataset_name objaverse ist, verwenden Sie lpips_objaverse.yaml. Denken Sie daran, das Verzeichnis des Modells aus der ersten Stufe in der entsprechenden .yaml-Datei abzulegen, bevor Sie die zweite Stufe starten.So trainieren Sie einen 2-Ansichten-Modelllauf:
python train_network.py +dataset=cars cam_embd=pose_pos data.input_images=2 opt.imgs_per_obj=5
Die Trainingsschleife ist in train_network.py implementiert und der Evaluierungscode befindet sich in eval.py . Datensätze werden in datasets/srn.py und datasets/co3d.py implementiert. Das Modell ist in scene/gaussian_predictor.py implementiert. Der Aufruf des Renderers ist in gaussian_renderer/__init__.py zu finden.
Der Gaußsche Rasterer geht von der Zeilen-Hauptordnung der Starrkörper-Transformationsmatrizen aus, dh dass Positionsvektoren Zeilenvektoren sind. Außerdem sind Kameras in der COLMAP/OpenCV-Konvention erforderlich, d. h. x zeigt nach rechts, y nach unten und z von der Kamera weg (nach vorne).
@inproceedings{szymanowicz24splatter,
title={Splatter Image: Ultra-Fast Single-View 3D Reconstruction},
author={Stanislaw Szymanowicz and Christian Rupprecht and Andrea Vedaldi},
year={2024},
booktitle={The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
}
S. Szymanowicz wird durch ein EPSRC Doctoral Training Partnerships Scholarship (DTP) EP/R513295/1 und das Oxford-Ashton-Stipendium unterstützt. A. Vedaldi wird von ERC-CoG UNION 101001212 unterstützt. Wir danken Eldar Insafutdinov für seine Hilfe bei den Installationsanforderungen.


