Ein Framework zum Trainieren multimodaler Any-to-Any-Grundlagenmodelle.
Skalierbar. Open-Source. Über Dutzende Modalitäten und Aufgaben hinweg.
EPFL - Apple
Website | BibTeX | ? Demo
Offizielle Implementierung und vorab trainierte Modelle für:
4M: Massively Multimodal Masked Modeling , NeurIPS 2023 (Spotlight)
David Mizrahi*, Roman Bachmann*, Oğuzhan Fatih Kar, Teresa Yeo, Mingfei Gao, Afshin Dehghan, Amir Zamir
4M-21: Ein Any-to-Any-Vision-Modell für Dutzende Aufgaben und Modalitäten , NeurIPS 2024
Roman Bachmann*, Oğuzhan Fatih Kar*, David Mizrahi*, Ali Garjani, Mingfei Gao, David Griffiths, Jiaming Hu, Afshin Dehghan, Amir Zamir
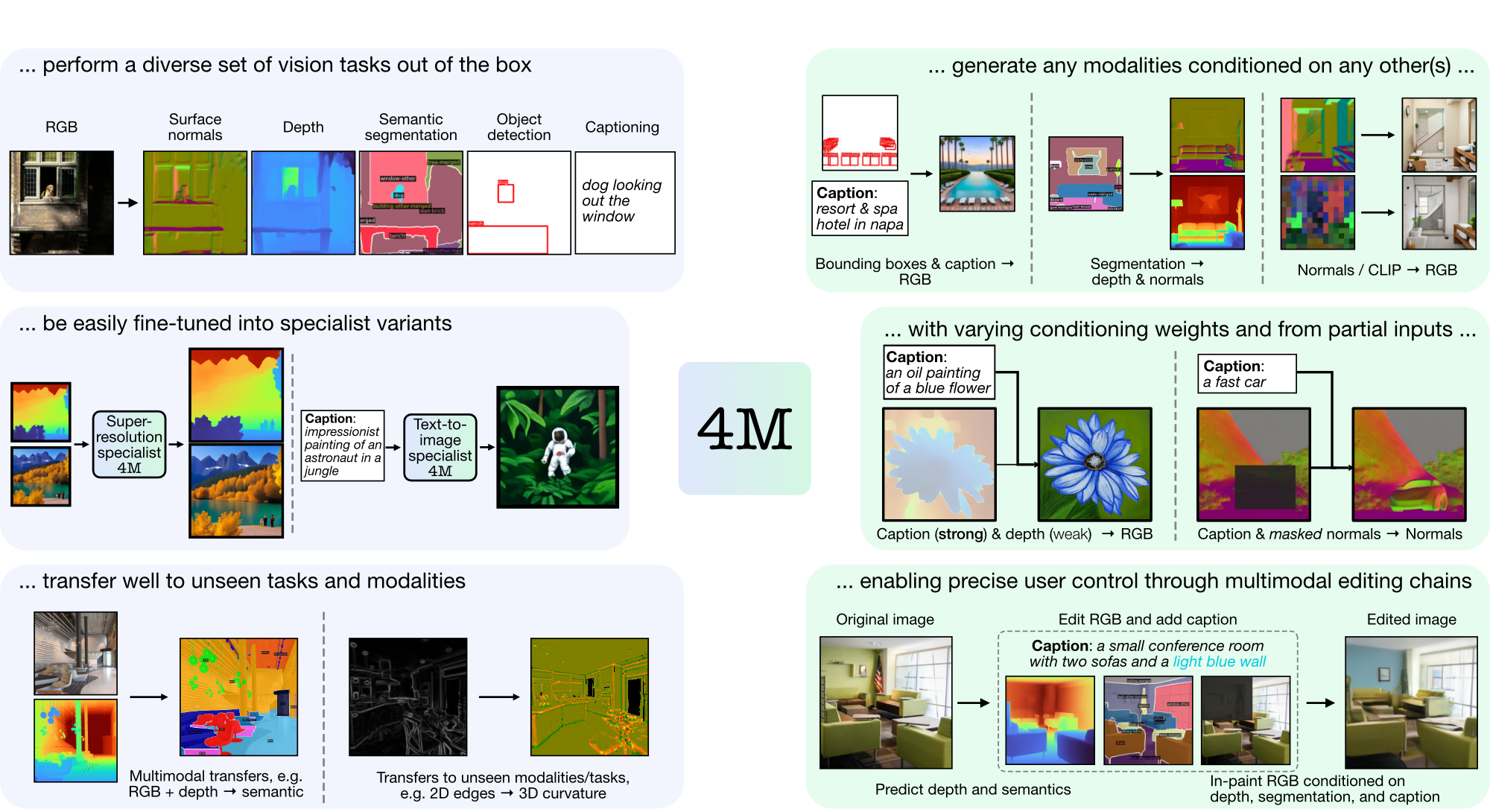
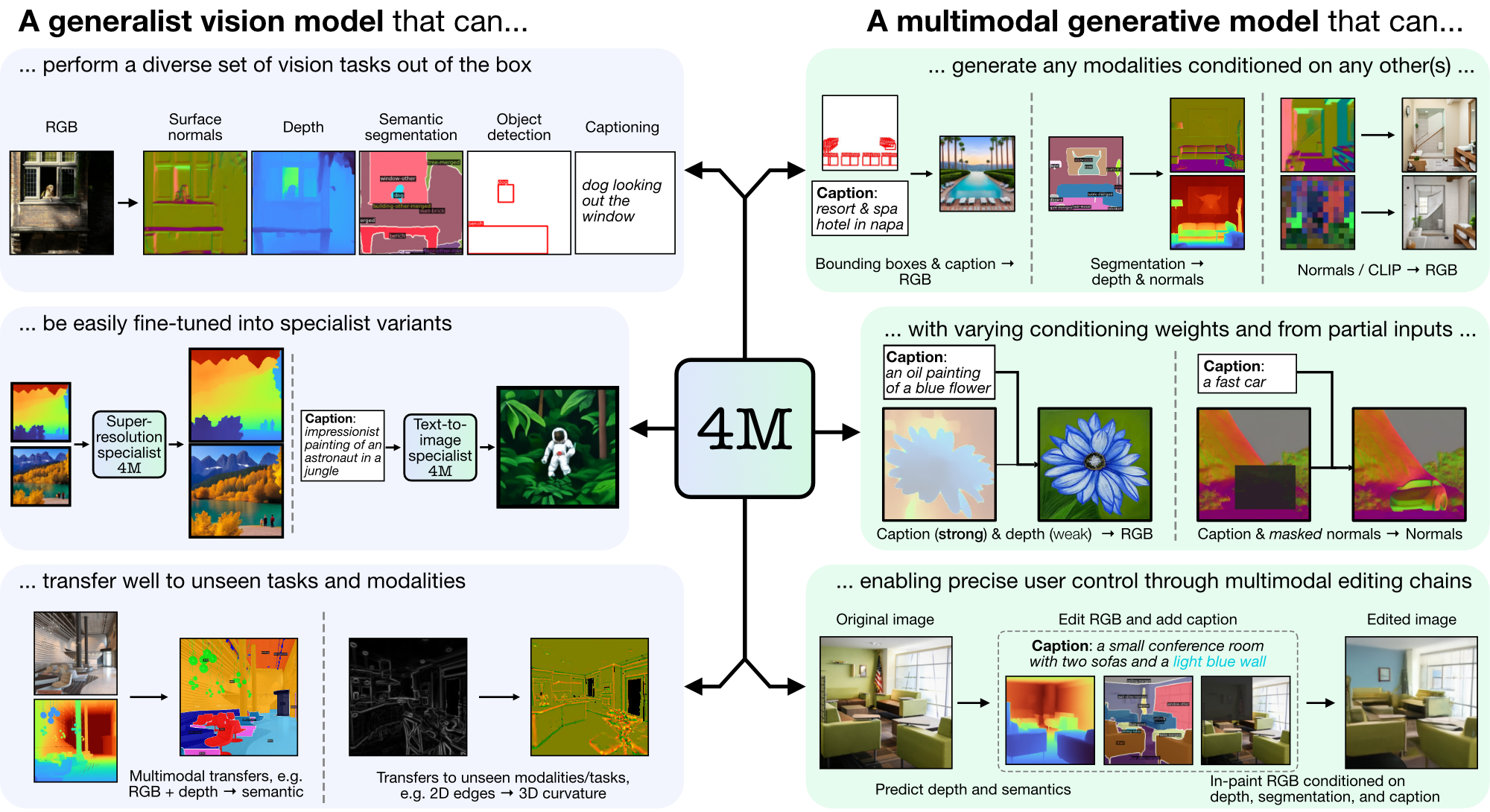
4M ist ein Framework zum Trainieren von „Any-to-Any“-Grundlagenmodellen, das Tokenisierung und Maskierung verwendet, um auf viele verschiedene Modalitäten zu skalieren. Mit 4M trainierte Modelle können ein breites Spektrum an Sehaufgaben ausführen, lassen sich gut auf unbekannte Aufgaben und Modalitäten übertragen und sind flexible und steuerbare multimodale generative Modelle. Wir veröffentlichen Code und Modelle für „4M: Massively Multimodal Masked Modeling“ (hier als 4M-7 bezeichnet) sowie „4M-21: An Any-to-Any Vision Model for Tens of Tasks and Modalities“ (hier als 4M bezeichnet). -21).
git clone https://github.com/apple/ml-4m
cd ml-4m
conda create -n fourm python=3.9 -y
conda activate fourm
pip install --upgrade pip # enable PEP 660 support
pip install -e .
# Run in Python shell
import torch
print(torch.cuda.is_available()) # Should return True
Wenn CUDA nicht verfügbar ist, sollten Sie eine Neuinstallation von PyTorch gemäß den offiziellen Installationsanweisungen in Betracht ziehen. Wenn Sie xFormers installieren möchten (optional, für schnellere Tokenizer), folgen Sie ebenfalls der README-Datei, um sicherzustellen, dass die CUDA-Version korrekt ist.
Wir stellen einen Demo-Wrapper zur Verfügung, um schnell mit der Verwendung von 4M-Modellen für RGB-to-All- oder {caption, Bounding Boxes}-to-All-Generierungsaufgaben zu beginnen. Um beispielsweise alle Modalitäten aus einer bestimmten RGB-Eingabe zu generieren, rufen Sie Folgendes auf:
from fourm . demo_4M_sampler import Demo4MSampler , img_from_url
sampler = Demo4MSampler ( fm = 'EPFL-VILAB/4M-21_XL' ). cuda ()
img = img_from_url ( 'https://storage.googleapis.com/four_m_site/images/demo_rgb.png' ) # 1x3x224x224 ImageNet-standardized PyTorch Tensor
preds = sampler ({ 'rgb@224' : img . cuda ()}, seed = None )
sampler . plot_modalities ( preds , save_path = None )Sie sollten mit einer Ausgabe wie der folgenden rechnen:


Um die Generierung von Untertiteln für alle durchzuführen, können Sie die Sampler-Eingabe ersetzen durch: preds = sampler({'caption': 'A lake house with a boat in front [S_1]'}) . Eine Liste der verfügbaren 4M-Modelle finden Sie im folgenden Modellzoo. Weitere Anweisungen zur Generierung finden Sie in README_GENERATION.md.
Anweisungen zum Vorbereiten ausgerichteter multimodaler Datensätze finden Sie in README_DATA.md.
Anweisungen zum Trainieren modalitätsspezifischer Tokenizer finden Sie in README_TOKENIZATION.md.
Anweisungen zum Trainieren von 4M-Modellen finden Sie in README_TRAINING.md.
Anweisungen zur Verwendung von 4M-Modellen für Inferenz/Generierung finden Sie in README_GENERATION.md. Wir stellen auch ein Generierungsnotizbuch zur Verfügung, das Beispiele für 4M-Inferenz enthält, insbesondere für die Durchführung bedingter Bildgenerierung und allgemeiner Bildverarbeitungsaufgaben (z. B. RGB-to-All).
Wir bieten 4M- und Tokenizer-Checkpoints als Safetensoren und bieten außerdem einfaches Laden über Hugging Face Hub.
| Modell | # Mod. | Datensätze | # Parameter | Konfig | Gewichte |
|---|---|---|---|---|---|
| 4M-B | 7 | CC12M | 198M | Konfig | Checkpoint / HF-Hub |
| 4M-B | 7 | COYO700M | 198M | Konfig | Checkpoint / HF-Hub |
| 4M-B | 21 | CC12M+COYO700M+C4 | 198M | Konfig | Checkpoint / HF-Hub |
| 4M-L | 7 | CC12M | 705M | Konfig | Checkpoint / HF-Hub |
| 4M-L | 7 | COYO700M | 705M | Konfig | Checkpoint / HF-Hub |
| 4M-L | 21 | CC12M+COYO700M+C4 | 705M | Konfig | Checkpoint / HF-Hub |
| 4M-XL | 7 | CC12M | 2,8B | Konfig | Checkpoint / HF-Hub |
| 4M-XL | 7 | COYO700M | 2,8B | Konfig | Checkpoint / HF-Hub |
| 4M-XL | 21 | CC12M+COYO700M+C4 | 2,8B | Konfig | Checkpoint / HF-Hub |
So laden Sie Modelle vom Hugging Face Hub:
from fourm . models . fm import FM
fm7b_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_B_CC12M' )
fm7b_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_B_COYO700M' )
fm21b = FM . from_pretrained ( 'EPFL-VILAB/4M-21_B' )
fm7l_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_L_CC12M' )
fm7l_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_L_COYO700M' )
fm21l = FM . from_pretrained ( 'EPFL-VILAB/4M-21_L' )
fm7xl_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_XL_CC12M' )
fm7xl_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_XL_COYO700M' )
fm21xl = FM . from_pretrained ( 'EPFL-VILAB/4M-21_XL' )Um die Checkpoints manuell zu laden, laden Sie zunächst die Safetensors-Dateien über die oben genannten Links herunter und rufen Sie auf:
from fourm . utils import load_safetensors
from fourm . models . fm import FM
ckpt , config = load_safetensors ( '/path/to/checkpoint.safetensors' )
fm = FM ( config = config )
fm . load_state_dict ( ckpt )Diese Modelle wurden mit den standardmäßigen 4M-7 CC12M-Modellen initialisiert, das Training wurde jedoch mit einer Modalitätsmischung fortgesetzt, die stark auf Texteingaben ausgerichtet war. Sie sind weiterhin in der Lage, alle anderen Aufgaben auszuführen, schneiden aber im Vergleich zu den nicht feinabgestimmten Modellen besser bei der Text-zu-Bild-Generierung ab.
| Modell | # Mod. | Datensätze | # Parameter | Konfig | Gewichte |
|---|---|---|---|---|---|
| 4M-T2I-B | 7 | CC12M | 198M | Konfig | Checkpoint / HF-Hub |
| 4M-T2I-L | 7 | CC12M | 705M | Konfig | Checkpoint / HF-Hub |
| 4M-T2I-XL | 7 | CC12M | 2,8B | Konfig | Checkpoint / HF-Hub |
So laden Sie Modelle vom Hugging Face Hub:
from fourm . models . fm import FM
fm7b_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_B_CC12M' )
fm7l_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_L_CC12M' )
fm7xl_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_XL_CC12M' )Das manuelle Laden von Kontrollpunkten erfolgt auf die gleiche Weise wie oben für die 4M-Basismodelle.
| Modell | # Mod. | Datensätze | # Parameter | Konfig | Gewichte |
|---|---|---|---|---|---|
| 4M-SR-L | 7 | CC12M | 198M | Konfig | Checkpoint / HF-Hub |
So laden Sie Modelle vom Hugging Face Hub:
from fourm . models . fm import FM
fm7l_sr_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-SR_L_CC12M' )Das manuelle Laden von Kontrollpunkten erfolgt auf die gleiche Weise wie oben für die 4M-Basismodelle.
| Modalität | Auflösung | Anzahl der Token | Codebuchgröße | Diffusionsdecoder | Gewichte |
|---|---|---|---|---|---|
| RGB | 224-448 | 196-784 | 16k | ✓ | Checkpoint / HF-Hub |
| Tiefe | 224-448 | 196-784 | 8k | ✓ | Checkpoint / HF-Hub |
| Normalen | 224-448 | 196-784 | 8k | ✓ | Checkpoint / HF-Hub |
| Kanten (Canny, SAM) | 224-512 | 196-1024 | 8k | ✓ | Checkpoint / HF-Hub |
| Semantische COCO-Segmentierung | 224-448 | 196-784 | 4k | ✗ | Checkpoint / HF-Hub |
| CLIP-B/16 | 224-448 | 196-784 | 8k | ✗ | Checkpoint / HF-Hub |
| DINOv2-B/14 | 224-448 | 256-1024 | 8k | ✗ | Checkpoint / HF-Hub |
| DINOv2-B/14 (global) | 224 | 16 | 8k | ✗ | Checkpoint / HF-Hub |
| ImageBind-H/14 | 224-448 | 256-1024 | 8k | ✗ | Checkpoint / HF-Hub |
| ImageBind-H/14 (global) | 224 | 16 | 8k | ✗ | Checkpoint / HF-Hub |
| SAM-Instanzen | - | 64 | 1k | ✗ | Checkpoint / HF-Hub |
| 3D-menschliche Posen | - | 8 | 1k | ✗ | Checkpoint / HF-Hub |
So laden Sie Modelle vom Hugging Face Hub:
from fourm . vq . vqvae import VQVAE , DiVAE
# 4M-7 modalities
tok_rgb = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_rgb_16k_224-448' )
tok_depth = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_depth_8k_224-448' )
tok_normal = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_normal_8k_224-448' )
tok_semseg = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_semseg_4k_224-448' )
tok_clip = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_CLIP-B16_8k_224-448' )
# 4M-21 modalities
tok_edge = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_edge_8k_224-512' )
tok_dinov2 = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_DINOv2-B14_8k_224-448' )
tok_dinov2_global = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_DINOv2-B14-global_8k_16_224' )
tok_imagebind = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_ImageBind-H14_8k_224-448' )
tok_imagebind_global = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_ImageBind-H14-global_8k_16_224' )
sam_instance = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_sam-instance_1k_64' )
human_poses = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_human-poses_1k_8' )Um die Checkpoints manuell zu laden, laden Sie zunächst die Safetensors-Dateien über die oben genannten Links herunter und rufen Sie auf:
from fourm . utils import load_safetensors
from fourm . vq . vqvae import VQVAE , DiVAE
ckpt , config = load_safetensors ( '/path/to/checkpoint.safetensors' )
tok = VQVAE ( config = config ) # Or DiVAE for models with a diffusion decoder
tok . load_state_dict ( ckpt )Der Code in diesem Repository wird unter der Apache 2.0-Lizenz veröffentlicht, wie in der LICENSE-Datei zu finden.
Die Modellgewichte in diesem Repository werden unter der Beispielcode-Lizenz veröffentlicht, die in der Datei LICENSE_WEIGHTS zu finden ist.
Wenn Sie dieses Repository hilfreich finden, denken Sie bitte darüber nach, unsere Arbeit zu zitieren:
@inproceedings{4m,
title={{4M}: Massively Multimodal Masked Modeling},
author={David Mizrahi and Roman Bachmann and O{u{g}}uzhan Fatih Kar and Teresa Yeo and Mingfei Gao and Afshin Dehghan and Amir Zamir},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
}
@article{4m21,
title={{4M-21}: An Any-to-Any Vision Model for Tens of Tasks and Modalities},
author={Roman Bachmann and O{u{g}}uzhan Fatih Kar and David Mizrahi and Ali Garjani and Mingfei Gao and David Griffiths and Jiaming Hu and Afshin Dehghan and Amir Zamir},
journal={arXiv 2024},
year={2024},
}


