MagicMix
1.0.0
Implementierung von MagicMix: Semantisches Mischen mit Diffusionsmodellen.
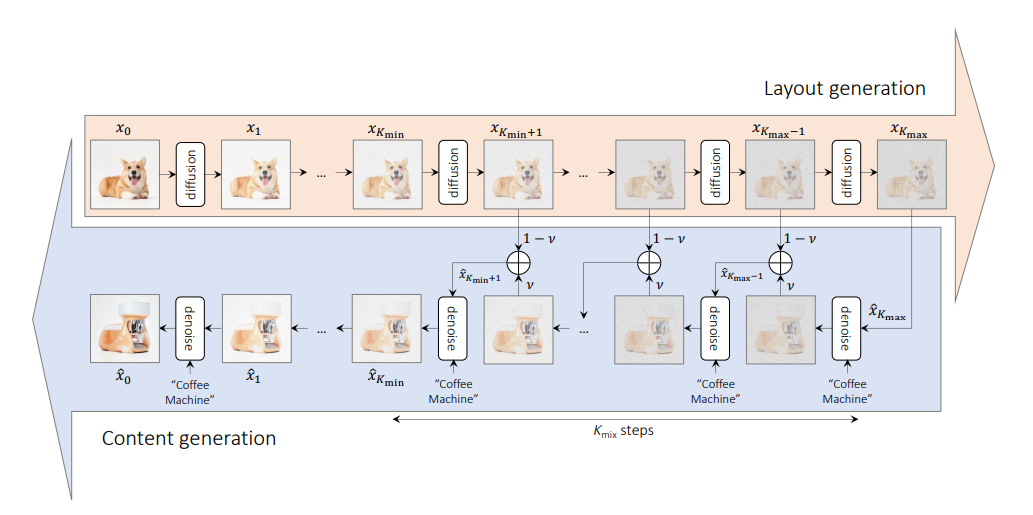
Ziel der Methode ist es, zwei unterschiedliche Konzepte semantisch zu vermischen, um unter Beibehaltung der räumlichen Anordnung und Geometrie ein neues Konzept zu synthetisieren.
Die Methode benötigt ein Bild, das die Layoutsemantik bereitstellt, und eine Eingabeaufforderung, die die Inhaltssemantik für den Mischprozess bereitstellt.
Es gibt 3 Parameter für die Methode:
v : Dies ist die Interpolationskonstante, die in der Layout-Generierungsphase verwendet wird. Je größer der Wert von v ist, desto größer ist der Einfluss der Eingabeaufforderung auf den Layout-Generierungsprozess.kmax und kmin : Diese bestimmen den Bereich für den Layout- und Inhaltsgenerierungsprozess. Ein höherer Wert von kmax führt zum Verlust weiterer Informationen über das Layout des Originalbilds und ein höherer Wert von kmin führt zu mehr Schritten für den Inhaltsgenerierungsprozess. from PIL import Image
from magic_mix import magic_mix
img = Image . open ( 'phone.jpg' )
out_img = magic_mix ( img , 'bed' , kmax = 0.5 )
out_img . save ( "mix.jpg" ) python3 magic_mix.py
"phone.jpg"
"bed"
"mix.jpg"
--kmin 0.3
--kmax 0.6
--v 0.5
--steps 50
--seed 42
--guidance_scale 7.5
Schauen Sie sich auch das Demo-Notizbuch an, um Beispiele aus der Arbeit zu reproduzieren.
Sie können auch die Community-Pipeline in der Diffusor-Bibliothek verwenden.
from diffusers import DiffusionPipeline , DDIMScheduler
from PIL import Image
pipe = DiffusionPipeline . from_pretrained (
"CompVis/stable-diffusion-v1-4" ,
custom_pipeline = "magic_mix" ,
scheduler = DDIMScheduler . from_pretrained ( "CompVis/stable-diffusion-v1-4" , subfolder = "scheduler" ),
). to ( 'cuda' )
img = Image . open ( 'phone.jpg' )
mix_img = pipe (
img ,
prompt = 'bed' ,
kmin = 0.3 ,
kmax = 0.5 ,
mix_factor = 0.5 ,
)
mix_img . save ( 'mix.jpg' )







Ich bin nicht der Autor des Papiers und dies ist keine offizielle Umsetzung


