ai pizza
1.0.0
Dennoch weiß niemand, ob eine Maschine etwas Neues erschaffen kann, oder ob sie sich auf das beschränkt, was sie bereits weiß. Aber schon jetzt kann künstliche Intelligenz komplizierte Probleme lösen und unstrukturierte Datensätze analysieren. Wir von Dodo haben beschlossen, ein Experiment durchzuführen. Etwas zu organisieren und strukturell zu beschreiben, das als chaotisch und subjektiv gilt – den Geschmack. Wir haben uns entschieden, künstliche Intelligenz zu nutzen, um die wildesten Kombinationen von Zutaten zu finden, die dennoch von den meisten Menschen als lecker empfunden werden.
In Zusammenarbeit mit Experten von MIPT und Skoltech haben wir künstliche Intelligenz geschaffen, die mehr als 300.000 Rezepte und Forschungsergebnisse zu molekularen Kombinationen von Inhaltsstoffen analysiert hat, die von Cambridge und mehreren anderen Universitäten in den USA durchgeführt wurden. Auf dieser Grundlage hat die KI gelernt, nicht offensichtliche Verbindungen zwischen Zutaten zu finden und zu verstehen, wie man die Zutaten paart und wie das Vorhandensein der einzelnen Zutaten die Kombinationen aller anderen beeinflusst.
Für jedes Modell benötigen Sie Daten. Deshalb haben wir zum Trainieren unserer KI über 300.000 Kochrezepte gesammelt.
Der schwierige Teil bestand nicht darin, sie zu sammeln, sondern sie in die gleiche Form zu bringen. Beispielsweise werden Chilischoten in Rezepten als „Chili“, „Chili“, „Chiles“ oder sogar „Chilis“ aufgeführt. Für uns ist es offensichtlich, dass all dies „Chili“ bedeutet, aber neuronale Netzwerke betrachten jedes davon als individuelle Einheit.
Anfangs hatten wir über 100.000 einzigartige Inhaltsstoffe, und nachdem wir die Daten bereinigt hatten, waren nur noch 1.000 einzigartige Positionen übrig.
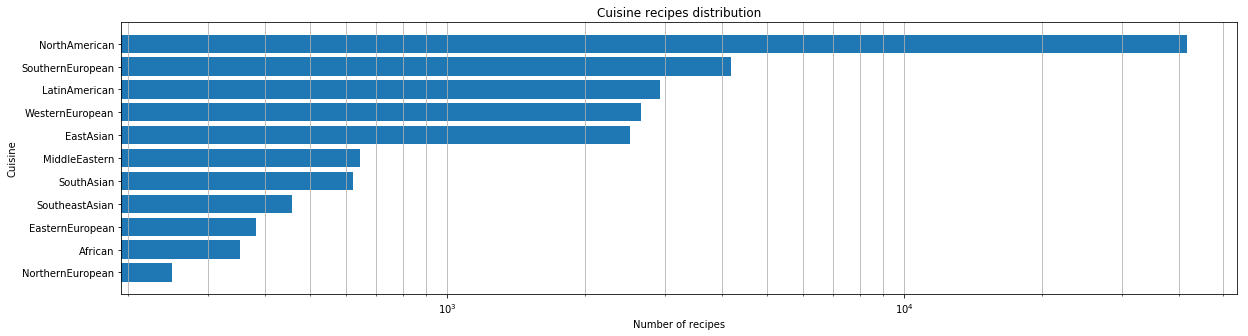
Nachdem wir den Datensatz erhalten hatten, führten wir eine erste Analyse durch. Zunächst führten wir eine quantitative Bewertung durch, wie viele Küchen in unserem Datensatz vorhanden waren.
Für jede Küche haben wir die beliebtesten Zutaten ermittelt.
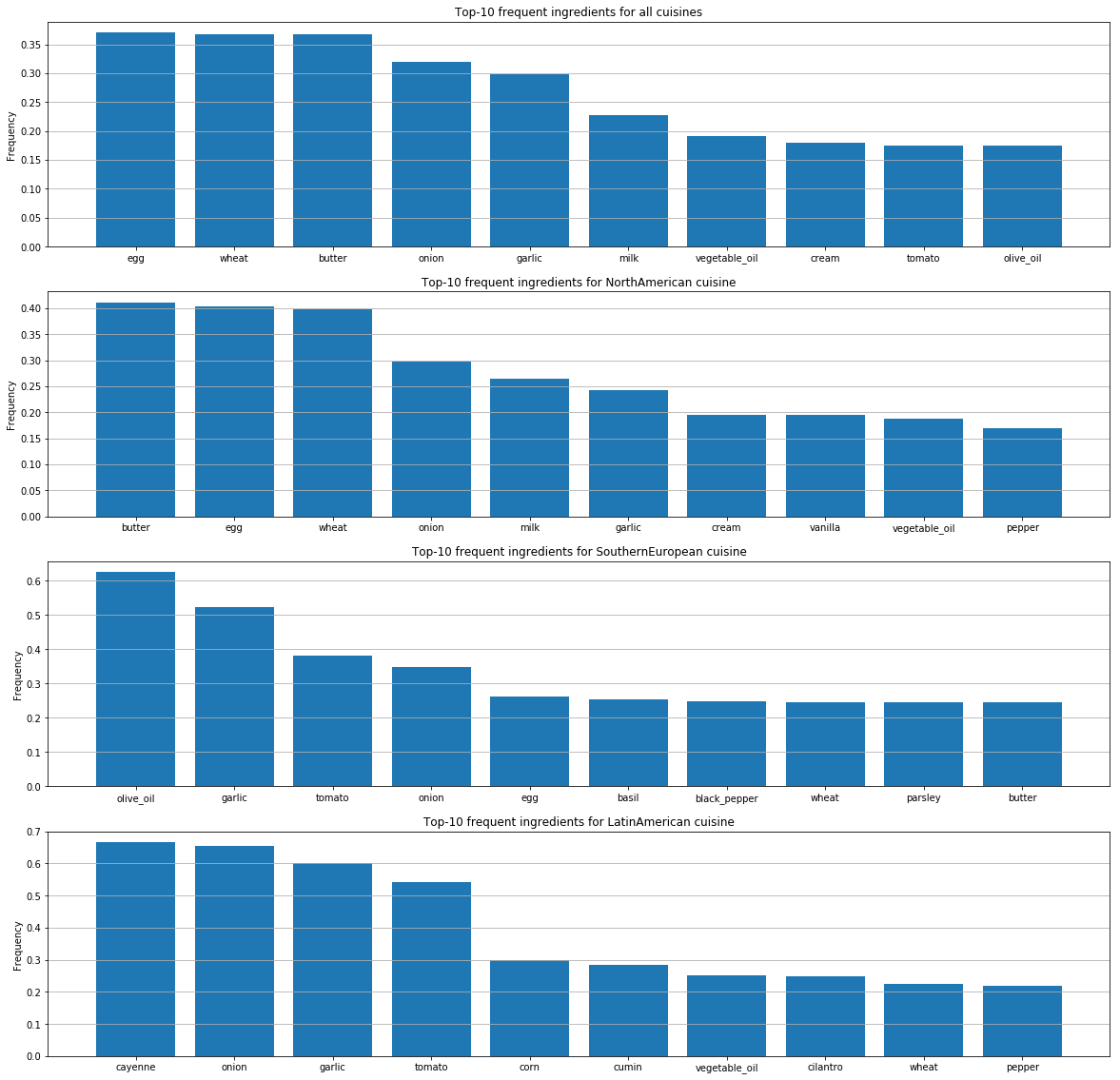
Diese Grafiken zeigen Unterschiede in den Geschmackspräferenzen der Menschen je nach Land und Unterschiede in der Art und Weise, wie sie Zutaten kombinieren.
Danach beschlossen wir, Pizzarezepte aus aller Welt zu analysieren, um die Muster zu entdecken. Dies sind die Schlussfolgerungen, die wir gezogen haben.
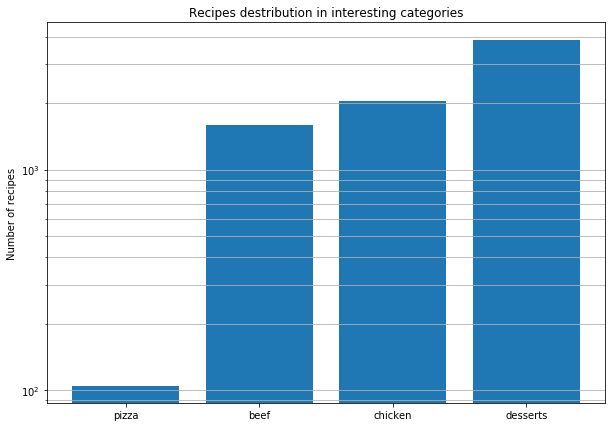
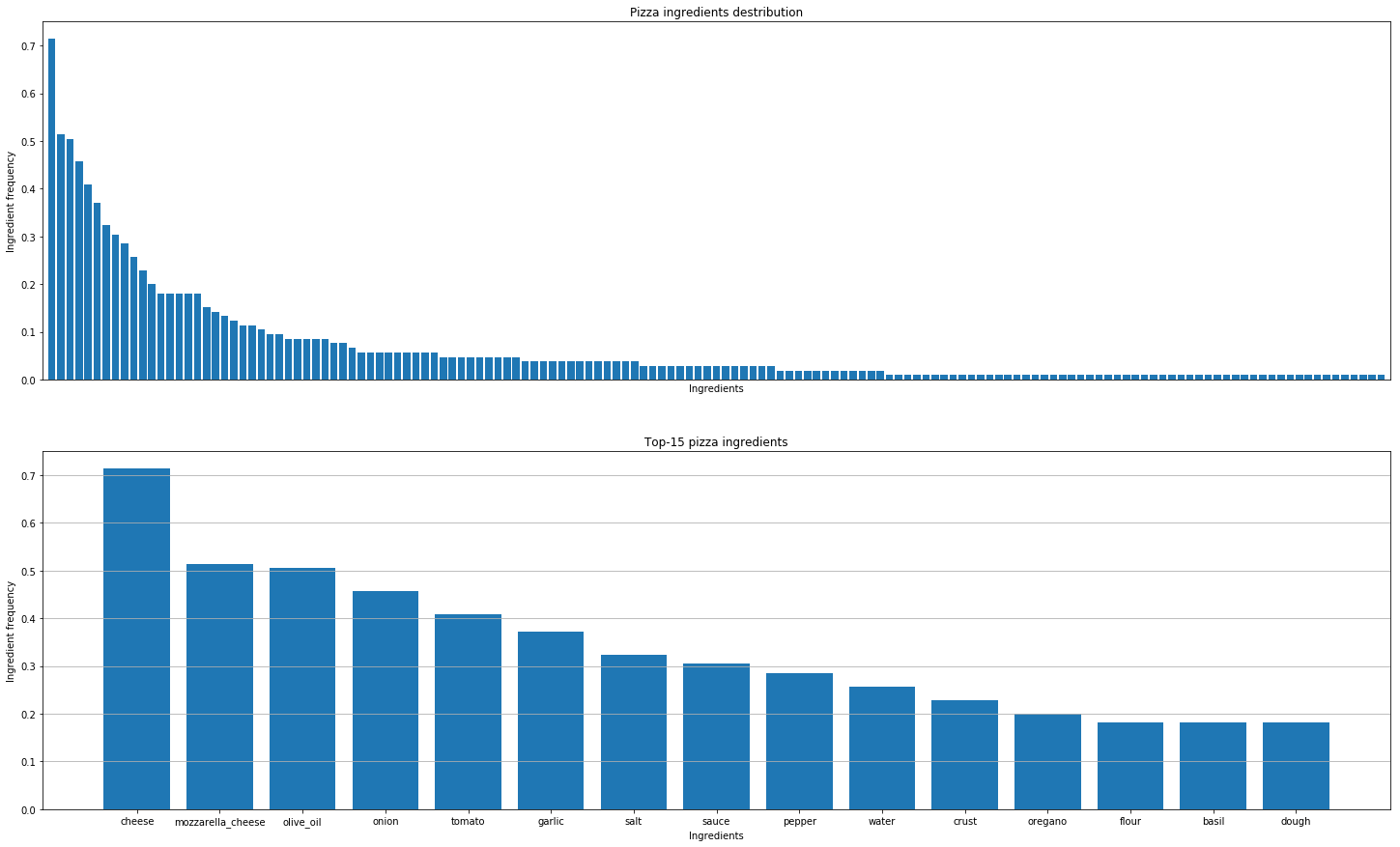
Tatsächliche Geschmackskombinationen zu finden ist nicht dasselbe wie molekulare Kombinationen herauszufinden. Alle Käsesorten haben die gleiche molekulare Zusammensetzung, aber das bedeutet nicht, dass gute Kombinationen nur aus den ähnlichsten Zutaten entstehen können.
Es sind jedoch die Kombinationen molekular ähnlicher Inhaltsstoffe, die wir sehen müssen, wenn wir die Inhaltsstoffe in Mathematik umwandeln. Denn ähnliche Objekte (die gleichen Käsesorten) müssen ähnlich bleiben, egal wie wir sie beschreiben. Auf diese Weise können wir feststellen, ob die Objekte korrekt beschrieben sind.
Um das Rezept in einer für das neuronale Netzwerk verständlichen Form darzustellen, verwendeten wir Skip-Gram Negative Sampling (SGNS) – einen Algorithmus von word2vec, der auf dem Vorkommen von Wörtern im Kontext basiert.
Wir haben uns entschieden, keine vorab trainierten word2vec-Modelle zu verwenden, da sich die semantische Struktur des Rezepts von der einfacher Texte unterscheidet. Und mit diesen Modellen könnten wir wichtige Informationen verlieren.
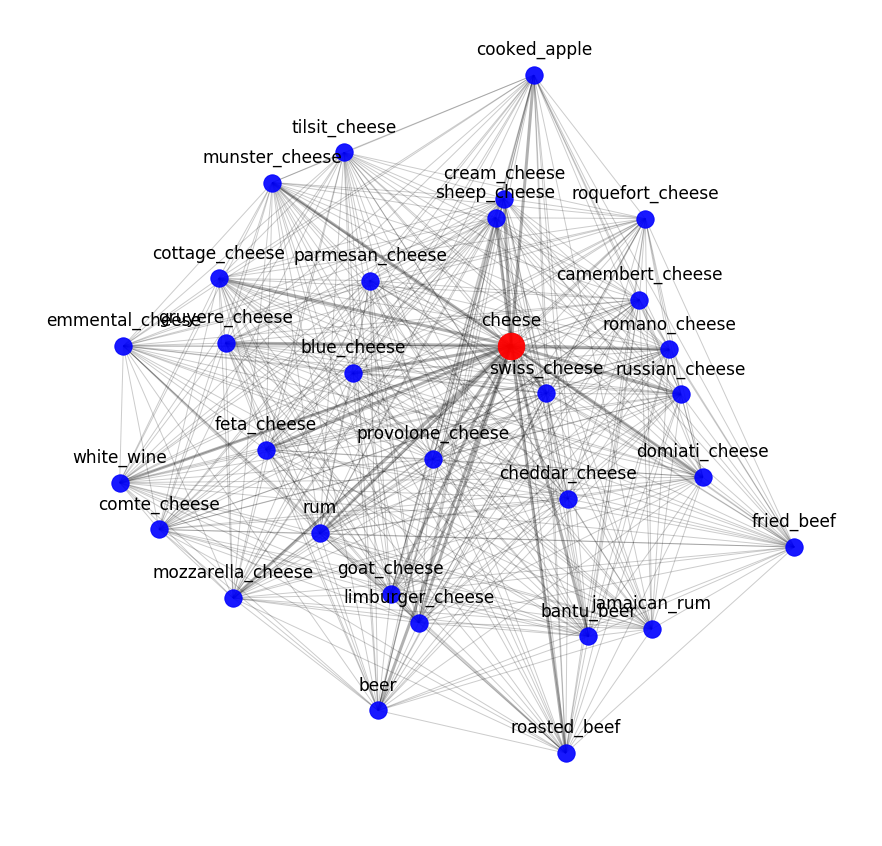
Sie können das Ergebnis von word2vec beurteilen, indem Sie sich die nächsten semantischen Nachbarn ansehen. Hier ist zum Beispiel, was unser Model über Käse weiß:
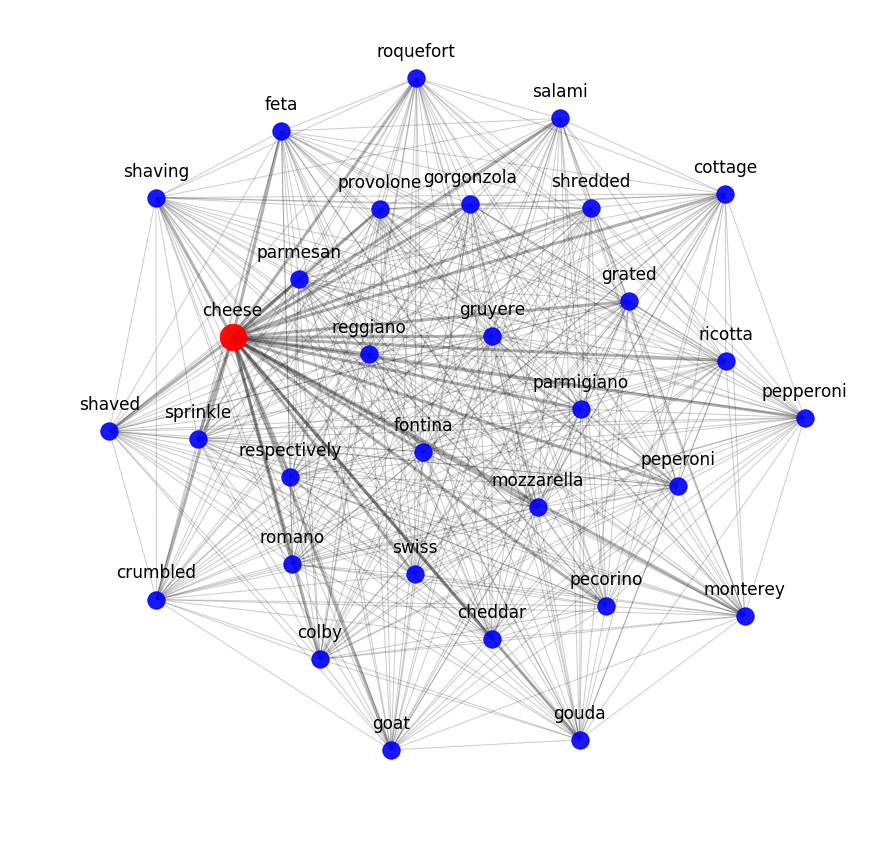
Um zu testen, inwieweit semantische Modelle die Rezeptzusammenhänge von Zutaten erfassen können, haben wir ein Themenmodell angewendet. Mit anderen Worten: Wir haben versucht, den Rezeptdatensatz nach mathematisch ermittelten Gesetzmäßigkeiten in Cluster zu zerlegen.
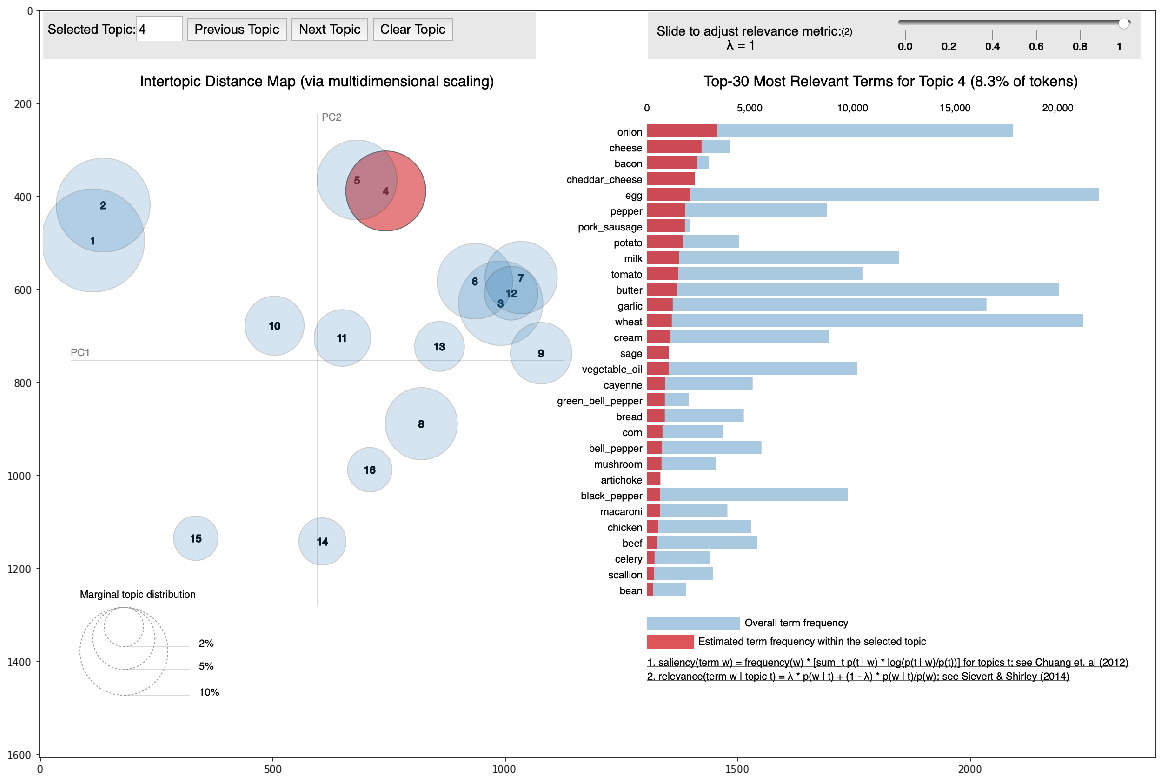
Für alle Rezepte kannten wir bestimmte Cluster, denen sie entsprachen. Bei Beispielrezepten kannten wir deren Zusammenhang mit realen Clustern. Auf dieser Grundlage haben wir den Zusammenhang zwischen diesen beiden Clustertypen gefunden.
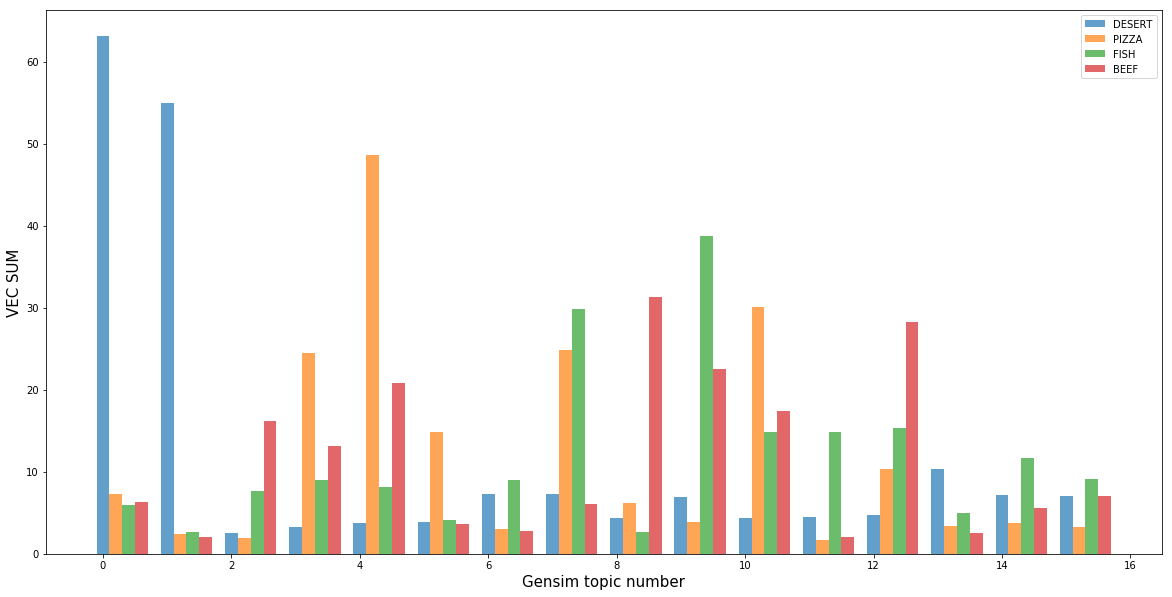
Am offensichtlichsten war die Klasse der Desserts, die in den vom Themenmodell generierten Themen 0 und 1 enthalten waren. Außer Desserts gibt es fast keine weiteren Kurse zu diesen Themen, was darauf hindeutet, dass Desserts sich leicht von anderen Gerichten unterscheiden lassen. Außerdem gibt es für jedes Thema eine Klasse, die es am besten beschreibt. Dies bedeutet, dass es unseren Modellen gelungen ist, die nicht offensichtliche Bedeutung von „Geschmack“ mathematisch zu definieren.
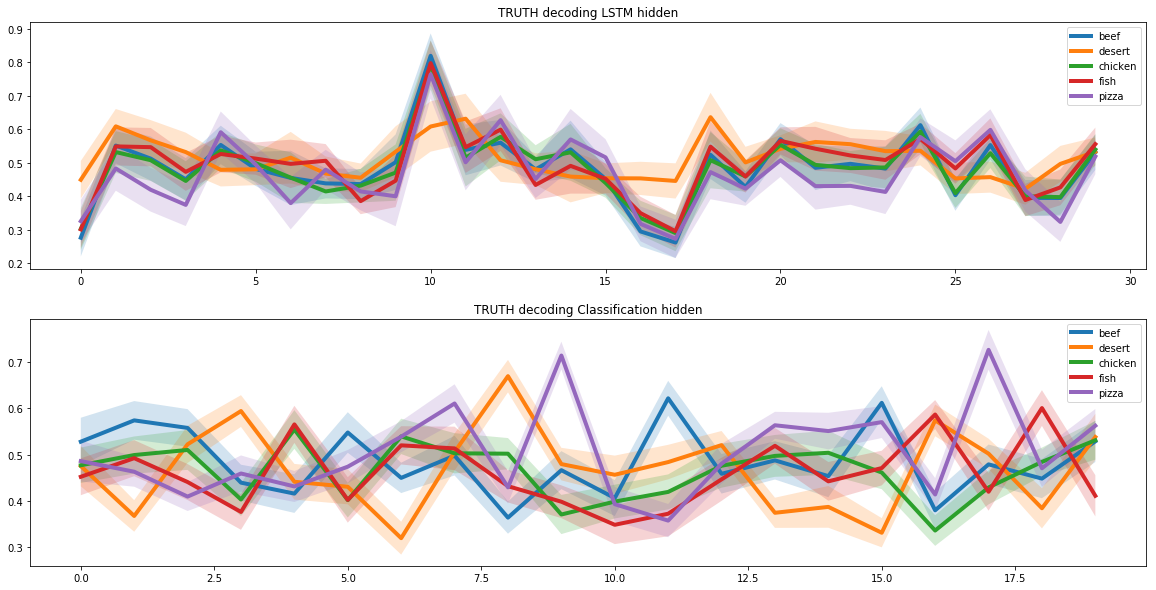
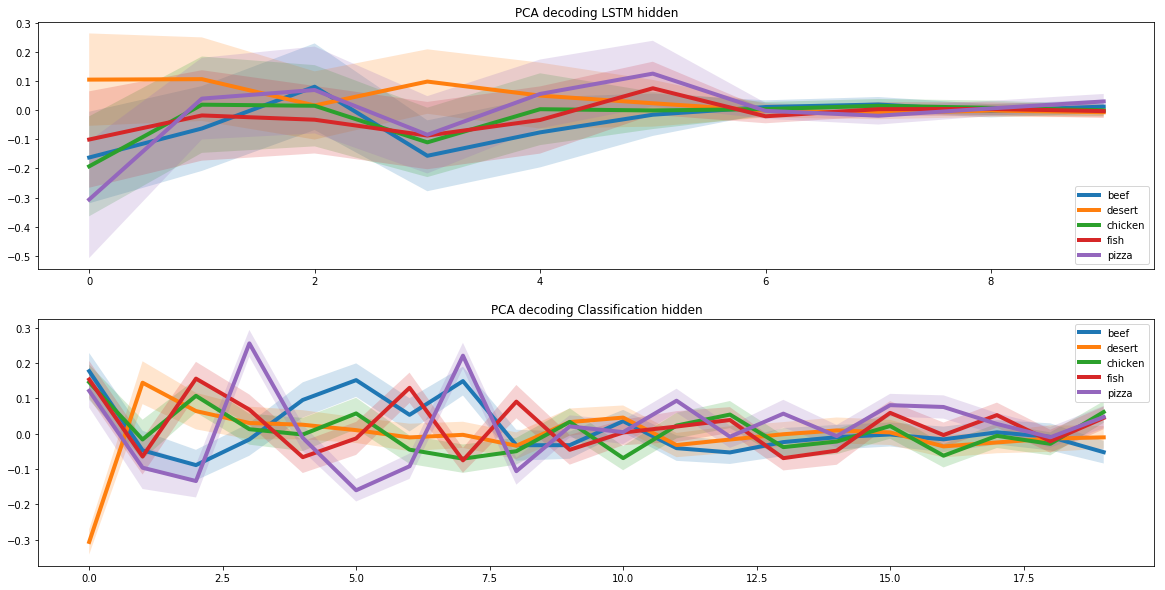
Wir haben zwei wiederkehrende neuronale Netze verwendet, um neue Rezepte zu erstellen. Zu diesem Zweck haben wir angenommen, dass es im gesamten Rezeptraum einen Unterraum gibt, der den Pizzarezepten entspricht. Und damit das neuronale Netzwerk lernen konnte, neue Pizzarezepte zu erstellen, mussten wir diesen Unterraum finden.
Diese Aufgabe ähnelt der automatischen Bildkodierung, bei der wir das Bild als niedrigdimensionalen Vektor darstellen. Solche Vektoren können viele spezifische Informationen über das Bild enthalten.
Diese Vektoren können beispielsweise Informationen über die Haarfarbe einer Person zur Gesichtserkennung in einem Foto in einer separaten Zelle speichern. Wir haben diesen Ansatz gerade wegen der einzigartigen Eigenschaften des verborgenen Unterraums gewählt.
Um den Pizza-Unterraum zu identifizieren, haben wir die Pizzarezepte durch zwei wiederkehrende neuronale Netze laufen lassen. Der erste erhielt das Pizzarezept und fand dessen Darstellung als latenten Vektor. Der zweite erhielt einen latenten Vektor vom ersten neuronalen Netzwerk und erstellte darauf basierend ein Rezept. Die Rezepte am Eingang des ersten neuronalen Netzwerks und am Ausgang des zweiten sollten übereinstimmen.
Auf diese Weise lernten zwei neuronale Netze, das Rezept eines latenten Vektors korrekt umzuwandeln. Und auf dieser Grundlage konnten wir einen versteckten Unterraum finden, der der gesamten Palette an Pizzarezepten entspricht.
Als wir das Problem der Erstellung eines Pizzarezepts lösten, mussten wir dem Modell molekulare Kombinationskriterien hinzufügen. Dazu haben wir die Ergebnisse einer gemeinsamen Studie von Wissenschaftlern aus Cambridge und mehreren US-Universitäten genutzt.
Die Studie ergab, dass die Inhaltsstoffe mit den häufigsten Molekülpaaren die besten Kombinationen bilden. Daher bevorzugte das neuronale Netzwerk bei der Rezeptur Zutaten mit einer ähnlichen molekularen Struktur.
Dadurch lernte unser neuronales Netzwerk, Pizzarezepte zu erstellen. Durch die Anpassung der Koeffizienten kann das neuronale Netzwerk sowohl klassische Rezepte wie Margaritas oder Peperoni als auch solche ungewöhnlichen Rezepte produzieren, von denen eines das Herzstück von Opensource Pizza ist.
| NEIN | Rezept |
|---|---|
| 1 | Spinat, Käse, Tomate, schwarze_Oliven, Oliven, Knoblauch, Pfeffer, Basilikum, Zitrusfrüchte, Melone, Sprossen, Buttermilch, Zitrone, Bass, Nüsse, Steckrüben |
| 2 | Zwiebel, Tomate, Olive, schwarzer Pfeffer, Brot, Teig |
| 3 | Huhn, Zwiebel, schwarze_Olive, Käse, Soße, Tomate, Olivenöl, Mozzarella-Käse |
| 4 | Tomate, Butter, Frischkäse, Pfeffer, Olivenöl, Käse, schwarzer Pfeffer, Mozzarellakäse |
Open Source Pizza ist unter der MIT-Lizenz lizenziert.
Golodyayev Arseniy, MIPT, Skoltech, [email protected]
Egor Baryshnikov, Skoltech, [email protected]


