dsub
Release 0.5.0
dsub ist ein Befehlszeilentool, das die einfache Übermittlung und Ausführung von Batch-Skripten in der Cloud ermöglicht.
Das dsub Benutzererlebnis ist nach dem Vorbild traditioneller High-Performance-Computing-Job-Scheduler wie Grid Engine und Slurm gestaltet. Sie schreiben ein Skript und übermitteln es dann über eine Shell-Eingabeaufforderung auf Ihrem lokalen Computer an einen Job-Scheduler.
Heute unterstützt dsub Google Cloud als Backend-Batch-Job-Runner sowie einen lokalen Anbieter für Entwicklung und Tests. Mit Hilfe der Community möchten wir weitere Backends hinzufügen, beispielsweise eine Grid Engine, Slurm, Amazon Batch und Azure Batch.
dsub ist in Python geschrieben und erfordert Python 3.7 oder höher.
dsub 0.4.7.dsub 0.4.1.dsub 0.3.10.Dies ist optional, aber unabhängig davon, ob Sie über PyPI oder Github installieren, wird Ihnen dringend empfohlen, eine virtuelle Python-Umgebung zu verwenden.
Sie können dies in einem Verzeichnis Ihrer Wahl tun.
python3 -m venv dsub_libs
source dsub_libs/bin/activate
Durch die Verwendung einer virtuellen Python-Umgebung werden Abhängigkeiten dsub Bibliothek von anderen Python-Anwendungen auf Ihrem System isoliert.
Aktivieren Sie diese virtuelle Umgebung in einer beliebigen Shell-Sitzung, bevor Sie dsub ausführen. Um die virtuelle Umgebung in Ihrer Shell zu deaktivieren, führen Sie den folgenden Befehl aus:
deactivate
Alternativ wird eine Reihe praktischer Skripts bereitgestellt, die die Virutalenv vor dem Aufruf von dsub , dstat und ddel aktivieren. Sie befinden sich im bin-Verzeichnis. Sie können diese Skripte verwenden, wenn Sie die virtuelle Umgebung nicht explizit in Ihrer Shell aktivieren möchten.
Obwohl es von dsub nicht direkt für die Anbieter google-batch oder google-cls-v2 verwendet wird, möchten Sie wahrscheinlich die Befehlszeilentools installieren, die im Google Cloud SDK enthalten sind.
Wenn Sie den local Anbieter für eine schnellere Jobentwicklung nutzen, müssen Sie das Google Cloud SDK installieren, das gsutil verwendet, um sicherzustellen, dass die Dateioperationssemantik mit den Google dsub Anbietern konsistent ist.
Installieren Sie das Google Cloud SDK
Laufen
gcloud init
gcloud fordert Sie auf, Ihr Standardprojekt festzulegen und Anmeldeinformationen für das Google Cloud SDK zu erteilen.
dsubWählen Sie eine der folgenden Optionen:
Installieren Sie ggf. pip.
Installieren Sie dsub
pip install dsub
Stellen Sie sicher, dass Git installiert ist
Anweisungen für Ihre Umgebung finden Sie auf der Git-Website.
Klonen Sie dieses Repository.
git clone https://github.com/DataBiosphere/dsub
cd dsub
Installieren Sie dsub (dadurch werden auch die Abhängigkeiten installiert)
python -m pip install .
Richten Sie die Bash-Tab-Vervollständigung ein (optional).
source bash_tab_complete
Überprüfen Sie die Installation minimal, indem Sie Folgendes ausführen:
dsub --help
(Optional) Installieren Sie Docker.
Dies ist nur erforderlich, wenn Sie Ihre eigenen Docker-Images erstellen oder den local Anbieter verwenden.
Nachdem Sie das dsub-Repo geklont haben, können Sie das Makefile auch verwenden, indem Sie Folgendes ausführen:
make
Dadurch wird eine virtuelle Python-Umgebung erstellt und dsub in einem Verzeichnis namens dsub_libs installiert.
Wir glauben, dass Ihnen der local Anbieter bei der Erstellung Ihrer dsub -Aufgaben sehr hilfreich sein wird. Anstatt eine Anfrage zur Ausführung Ihres Befehls auf einer Cloud-VM zu senden, führt der local Anbieter Ihre dsub Aufgaben auf Ihrem lokalen Computer aus.
Der local Anbieter ist nicht für den Betrieb im großen Maßstab ausgelegt. Es ist so konzipiert, dass es die Ausführung auf einer Cloud-VM emuliert, sodass Sie schnell iterieren können. Dadurch erhalten Sie schnellere Bearbeitungszeiten und es fallen keine Cloud-Gebühren an.
Führen Sie einen dsub -Job aus und warten Sie auf den Abschluss.
Hier ist ein sehr einfacher „Hello World“-Test:
dsub
--provider local
--logging "${TMPDIR:-/tmp}/dsub-test/logging/"
--output OUT="${TMPDIR:-/tmp}/dsub-test/output/out.txt"
--command 'echo "Hello World" > "${OUT}"'
--wait
Hinweis: TMPDIR ist auf den meisten Unix-Systemen standardmäßig auf /tmp eingestellt, wird aber auch oft nicht gesetzt. Bei einigen Versionen von MacOS ist TMPDIR auf einen Speicherort unter /var/folders festgelegt.
Hinweis: Die obige Syntax ${TMPDIR:-/tmp} wird bekanntermaßen von Bash, zsh, ksh unterstützt. Die Shell erweitert TMPDIR , aber wenn es nicht gesetzt ist, wird /tmp verwendet.
Sehen Sie sich die Ausgabedatei an.
cat "${TMPDIR:-/tmp}/dsub-test/output/out.txt"
dsub unterstützt derzeit die Cloud Life Sciences v2beta API von Google Cloud und entwickelt Unterstützung für die Batch API von Google Cloud.
dsub unterstützt die v2beta-API mit dem Anbieter google-cls-v2 . google-cls-v2 ist der aktuelle Standardanbieter. dsub wird in kommenden Versionen umgestellt, um google-batch zum Standard zu machen.
Die Schritte für den Einstieg unterscheiden sich geringfügig, wie in den folgenden Schritten angegeben:
Eröffnen Sie ein Google-Konto und erstellen Sie ein Projekt.
Aktivieren Sie die APIs:
v2beta -API (Anbieter: google-cls-v2 ):Aktivieren Sie die Cloud Life Sciences-, Storage- und Compute-APIs
batch API (Anbieter: google-batch ):Aktivieren Sie die Batch-, Storage- und Compute-APIs.
Geben Sie Anmeldeinformationen an, damit dsub Google APIs aufrufen kann:
gcloud auth application-default login
Erstellen Sie einen Google Cloud Storage-Bucket.
Die dsub-Protokolle und Ausgabedateien werden in einen Bucket geschrieben. Erstellen Sie einen Bucket mit dem Speicherbrowser oder führen Sie das Befehlszeilendienstprogramm gsutil aus, das im Cloud SDK enthalten ist.
gsutil mb gs://my-bucket
Ändern Sie my-bucket in einen eindeutigen Namen, der den Bucket-Benennungskonventionen folgt.
(Standardmäßig befindet sich der Bucket in den USA, Sie können die Standorteinstellung jedoch mit der Option -l ändern oder verfeinern.)
Führen Sie einen sehr einfachen dsub Job „Hello World“ aus und warten Sie, bis er abgeschlossen ist.
Für die v2beta -API (Anbieter: google-cls-v2 ):
dsub
--provider google-cls-v2
--project my-cloud-project
--regions us-central1
--logging gs://my-bucket/logging/
--output OUT=gs://my-bucket/output/out.txt
--command 'echo "Hello World" > "${OUT}"'
--wait
Ändern Sie my-cloud-project in Ihr Google Cloud-Projekt und my-bucket in den Bucket, den Sie oben erstellt haben.
Für die batch API (Anbieter: google-batch ):
dsub
--provider google-batch
--project my-cloud-project
--regions us-central1
--logging gs://my-bucket/logging/
--output OUT=gs://my-bucket/output/out.txt
--command 'echo "Hello World" > "${OUT}"'
--wait
Ändern Sie my-cloud-project in Ihr Google Cloud-Projekt und my-bucket in den Bucket, den Sie oben erstellt haben.
Die Ausgabe des Skriptbefehls wird in die von Ihnen angegebene OUT Datei im Cloud Storage geschrieben.
Sehen Sie sich die Ausgabedatei an.
gsutil cat gs://my-bucket/output/out.txt
Wo möglich, versucht dsub , Benutzern dabei zu helfen, lokal zu entwickeln und zu testen (für eine schnellere Iteration) und dann zur skalierten Ausführung überzugehen.
Zu diesem Zweck stellt dsub mehrere „Backend-Provider“ zur Verfügung, die jeweils eine konsistente Laufzeitumgebung implementieren. Die aktuellen Anbieter sind:
Weitere Details zur Laufzeitumgebung, die von den Backend-Anbietern implementiert wird, finden Sie unter dsub Backend-Anbieter.
google-cls-v2 und google-batch Der google-cls-v2 Anbieter basiert auf der Cloud Life Sciences v2beta API. Diese API ist ihrem Vorgänger, der Genomics v2alpha1 API, sehr ähnlich. Einzelheiten zu den Unterschieden finden Sie im Migrationsleitfaden.
Der google-batch Anbieter basiert auf der Cloud Batch API. Einzelheiten zu Cloud Life Sciences im Vergleich zu Batch finden Sie in diesem Migrationsleitfaden.
dsub verbirgt die Unterschiede zwischen den APIs weitgehend, es sind jedoch einige Unterschiede zu beachten:
google-batch erfordert, dass Jobs in einer Region ausgeführt werden Die Flags --regions und --zones für dsub geben an, wo die Aufgaben ausgeführt werden sollen. Mit google-cls-v2 können Sie eine Multiregion wie US , mehrere Regionen oder mehrere Zonen über mehrere Regionen hinweg angeben. Beim google-batch Anbieter müssen Sie entweder eine Region oder mehrere Zonen innerhalb einer einzelnen Region angeben.
dsub FunktionenIn den folgenden Abschnitten wird gezeigt, wie Sie komplexere Jobs ausführen.
Sie können einen Shell-Befehl direkt in der dsub-Befehlszeile eingeben, wie im Hallo-Beispiel oben.
Sie können Ihr Skript auch in einer Datei speichern, z. B. hello.sh . Dann können Sie Folgendes ausführen:
dsub
...
--script hello.sh
Wenn Ihr Skript Abhängigkeiten aufweist, die nicht in Ihrem Docker-Image gespeichert sind, können Sie diese auf die lokale Festplatte übertragen. Beachten Sie die nachstehenden Anweisungen zum Arbeiten mit Eingabe- und Ausgabedateien und -ordnern.
Um den Einstieg zu erleichtern, verwendet dsub ein Standard-Ubuntu-Docker-Image. Dieses Standardbild kann sich in zukünftigen Versionen jederzeit ändern. Für reproduzierbare Produktionsabläufe sollten Sie das Bild daher immer explizit angeben.
Sie können das Bild ändern, indem Sie das Flag --image übergeben.
dsub
...
--image ubuntu:16.04
--script hello.sh
Hinweis: Ihr --image muss den Bash-Shell-Interpreter enthalten.
Weitere Informationen zur Verwendung des Flags --image finden Sie im Abschnitt „Image“ unter „Skripte, Befehle und Docker“.
Mit dem Flag --env können Sie Umgebungsvariablen an Ihr Skript übergeben.
dsub
...
--env MESSAGE=hello
--command 'echo ${MESSAGE}'
Der Umgebungsvariablen MESSAGE wird der Wert hello zugewiesen, wenn Ihr Docker-Container ausgeführt wird.
Ihr Skript oder Befehl kann die Variable wie jede andere Linux-Umgebungsvariable als ${MESSAGE} referenzieren.
Stellen Sie sicher, dass Sie Ihre Befehlszeichenfolge in einfache Anführungszeichen und nicht in doppelte Anführungszeichen setzen. Wenn Sie doppelte Anführungszeichen verwenden, wird der Befehl in Ihrer lokalen Shell erweitert, bevor er an dsub übergeben wird. Weitere Informationen zur Verwendung des Flags --command finden Sie unter Skripte, Befehle und Docker
Um mehrere Umgebungsvariablen festzulegen, können Sie das Flag wiederholen:
--env VAR1=value1
--env VAR2=value2
Sie können auch mehrere durch Leerzeichen getrennte Variablen mit einem einzigen Flag festlegen:
--env VAR1=value1 VAR2=value2
dsub ahmt das Verhalten eines gemeinsam genutzten Dateisystems nach, indem es Cloud-Speicher-Bucket-Pfade für Eingabe- und Ausgabedateien und -ordner verwendet. Sie geben den Cloud-Speicher-Bucket-Pfad an. Pfade können sein:
gs://my-bucket/my-filegs://my-bucket/my-foldergs://my-bucket/my-folder/*Weitere Einzelheiten finden Sie in der Dokumentation zu Ein- und Ausgängen.
Wenn Ihr Skript erwartet, lokale Eingabedateien zu lesen, die nicht bereits in Ihrem Docker-Image enthalten sind, müssen die Dateien in Google Cloud Storage verfügbar sein.
Wenn Ihr Skript über abhängige Dateien verfügt, können Sie diese wie folgt für Ihr Skript verfügbar machen:
Um die Dateien in Google Cloud Storage hochzuladen, können Sie den Speicherbrowser oder gsutil verwenden. Sie können die Ausführung auch mit Daten ausführen, die öffentlich sind oder mit Ihrem Dienstkonto geteilt werden, einer E-Mail-Adresse, die Sie in der Google Cloud Console finden.
Um Eingabe- und Ausgabedateien anzugeben, verwenden Sie die Flags --input und --output :
dsub
...
--input INPUT_FILE_1=gs://my-bucket/my-input-file-1
--input INPUT_FILE_2=gs://my-bucket/my-input-file-2
--output OUTPUT_FILE=gs://my-bucket/my-output-file
--command 'cat "${INPUT_FILE_1}" "${INPUT_FILE_2}" > "${OUTPUT_FILE}"'
In diesem Beispiel:
gs://my-bucket/my-input-file-1 in einen Pfad auf der Datenfestplatte kopiert${INPUT_FILE_1} festgelegt.gs://my-bucket/my-input-file-2 in einen Pfad auf der Datenfestplatte kopiert${INPUT_FILE_2} festgelegt. Der --command kann mithilfe der Umgebungsvariablen auf die Dateipfade verweisen.
Auch in diesem Beispiel:
${OUTPUT_FILE} wird ein Pfad auf dem Datenträger festgelegt.${OUTPUT_FILE} angegebenen Speicherort auf die Datenfestplatte geschrieben. Nach Abschluss des --command wird die Ausgabedatei in den Bucket-Pfad gs://my-bucket/my-output-file kopiert
Es können mehrere --input und --output -Parameter angegeben werden, und zwar in beliebiger Reihenfolge.
Um Ordner statt Dateien zu kopieren, verwenden Sie die Flags --input-recursive und output-recursive :
dsub
...
--input-recursive FOLDER=gs://my-bucket/my-folder
--command 'find ${FOLDER} -name "foo*"'
Es können mehrere Parameter --input-recursive und --output-recursive angegeben werden, und zwar in beliebiger Reihenfolge.
Während die explizite Angabe von Eingaben die Nachverfolgung der Herkunft Ihrer Daten verbessert, gibt es Fälle, in denen Sie möglicherweise nicht alle Eingaben explizit aus Cloud Storage auf Ihrer Job-VM lokalisieren möchten.
Wenn Sie beispielsweise Folgendes haben:
ODER
ODER
Dann finden Sie es möglicherweise effizienter oder bequemer, auf diese Daten zuzugreifen, indem Sie sie schreibgeschützt mounten:
Die Anbieter google-cls-v2 und google-batch unterstützen diese Methoden zur Bereitstellung des Zugriffs auf Ressourcendaten.
Der local Anbieter unterstützt das Mounten eines lokalen Verzeichnisses auf ähnliche Weise, um Ihre lokale Entwicklung zu unterstützen.
Damit der Anbieter google-cls-v2 oder google-batch einen Cloud Storage-Bucket mithilfe von Cloud Storage FUSE bereitstellt, verwenden Sie das Befehlszeilenflag --mount :
--mount RESOURCES=gs://mybucket
Der Bucket wird schreibgeschützt in den Docker-Container gemountet, auf dem Ihr --script oder --command ausgeführt wird, und der Speicherort wird über die Umgebungsvariable ${RESOURCES} zur Verfügung gestellt. In Ihrem Skript können Sie mithilfe der Umgebungsvariablen auf den bereitgestellten Pfad verweisen. Bitte lesen Sie die wichtigsten Unterschiede zu einem POSIX-Dateisystem und Semantik, bevor Sie Cloud Storage FUSE verwenden.
Damit der Anbieter google-cls-v2 oder google-batch einen von Ihnen vorab erstellten und gefüllten persistenten Datenträger bereitstellt, verwenden Sie das Befehlszeilenflag --mount und die URL des Quelldatenträgers:
--mount RESOURCES="https://www.googleapis.com/compute/v1/projects/your-project/zones/your_disk_zone/disks/your-disk"
Damit der google-cls-v2 oder google-batch -Anbieter eine aus einem Image erstellte persistente Festplatte bereitstellen kann, verwenden Sie das Befehlszeilenflag --mount und die URL des Quellimages sowie die Größe (in GB) der Festplatte:
--mount RESOURCES="https://www.googleapis.com/compute/v1/projects/your-project/global/images/your-image 50"
Das Image wird zum Erstellen einer neuen persistenten Festplatte verwendet, die an eine Compute Engine-VM angehängt wird. Die Festplatte wird in den Docker-Container gemountet, indem Sie Ihr --script oder --command ausführen, und der Speicherort wird durch die Umgebungsvariable ${RESOURCES} zur Verfügung gestellt. In Ihrem Skript können Sie mithilfe der Umgebungsvariablen auf den bereitgestellten Pfad verweisen.
Informationen zum Erstellen eines Bildes finden Sie unter Erstellen eines benutzerdefinierten Bildes.
local Anbieter) Damit der local Anbieter ein Verzeichnis schreibgeschützt mounten kann, verwenden Sie das Befehlszeilen-Flag --mount und ein file:// -Präfix:
--mount RESOURCES=file://path/to/my/dir
Das lokale Verzeichnis wird in den Docker-Container eingebunden, der Ihr --script oder --command ausführt, und der Speicherort wird über die Umgebungsvariable ${RESOURCES} verfügbar gemacht. In Ihrem Skript können Sie mithilfe der Umgebungsvariablen auf den bereitgestellten Pfad verweisen.
dsub Aufgaben, die mit dem local Anbieter ausgeführt werden, nutzen die auf Ihrem lokalen Computer verfügbaren Ressourcen.
dsub Aufgaben, die mit den Anbietern google-cls-v2 oder google-batch ausgeführt werden, können eine breite Palette von CPU-, RAM-, Festplatten- und Hardwarebeschleunigeroptionen (z. B. GPU) nutzen.
Weitere Informationen finden Sie in der Dokumentation zu Compute Resources.
Standardmäßig generiert dsub eine job-id in der Form job-name--userid--timestamp , wobei der job-name auf 10 Zeichen gekürzt wird und der timestamp die Form YYMMDD-HHMMSS-XX hat, eindeutig auf Hundertstelsekunden . Wenn Sie mehrere Jobs gleichzeitig übermitteln, kann es immer noch zu Situationen kommen, in denen die job-id nicht eindeutig ist. Wenn Sie für diese Situation eine eindeutige job-id benötigen, können Sie den Parameter --unique-job-id verwenden.
Wenn der Parameter --unique-job-id festgelegt ist, ist die job-id stattdessen eine eindeutige 32-stellige UUID, die von https://docs.python.org/3/library/uuid.html erstellt wurde. Da einige Anbieter verlangen, dass die job-id mit einem Buchstaben beginnt, ersetzt dsub jede Anfangsziffer durch einen Buchstaben, sodass die Eindeutigkeit gewahrt bleibt.
Jedes der oben genannten Beispiele hat gezeigt, wie eine einzelne Aufgabe mit einem einzigen Satz von Variablen, Eingaben und Ausgaben übermittelt wird. Wenn Sie über einen Batch von Eingaben verfügen und den gleichen Vorgang darauf ausführen möchten, können Sie dsub einen Batch-Job erstellen.
Anstatt dsub wiederholt aufzurufen, können Sie eine TSV-Datei (Tabulator-getrennte Werte) erstellen, die die Variablen, Eingaben und Ausgaben für jede Aufgabe enthält, und dsub dann einmal aufrufen. Das Ergebnis ist eine einzelne job-id mit mehreren Aufgaben. Die Aufgaben werden unabhängig voneinander geplant und ausgeführt, können jedoch als Gruppe überwacht und gelöscht werden.
Die erste Zeile der TSV-Datei gibt die Namen und Typen der Parameter an. Zum Beispiel:
--env SAMPLE_ID<tab>--input VCF_FILE<tab>--output OUTPUT_PATH
Jede zusätzliche Zeile in der Datei sollte die Variablen-, Eingabe- und Ausgabewerte für jede Aufgabe bereitstellen. Jede Zeile hinter der Kopfzeile stellt die Werte für eine separate Aufgabe dar.
Es können mehrere Parameter --env , --input und --output angegeben werden, und zwar in beliebiger Reihenfolge. Zum Beispiel:
--env SAMPLE<tab>--input A<tab>--input B<tab>--env REFNAME<tab>--output O
S1<tab>gs://path/A1.txt<tab>gs://path/B1.txt<tab>R1<tab>gs://path/O1.txt
S2<tab>gs://path/A2.txt<tab>gs://path/B2.txt<tab>R2<tab>gs://path/O2.txt
Übergeben Sie die TSV-Datei mit dem Parameter --tasks an dsub. Dieser Parameter akzeptiert sowohl den Dateipfad als auch optional eine Reihe von Aufgaben zur Verarbeitung. Die Datei kann aus dem lokalen Dateisystem (auf dem Computer, von dem aus Sie dsub aufrufen) oder aus einem Bucket in Google Cloud Storage (Dateiname beginnt mit „gs://“) gelesen werden.
Angenommen, my-tasks.tsv enthält 101 Zeilen: einen einzeiligen Header und 100 Zeilen mit Parametern für auszuführende Aufgaben. Dann:
dsub ... --tasks ./my-tasks.tsv
erstellt einen Job mit 100 Aufgaben, während:
dsub ... --tasks ./my-tasks.tsv 1-10
erstellt einen Job mit 10 Aufgaben, eine für jede der Zeilen 2 bis 11.
Die Aufgabenbereichswerte können eine der folgenden Formen annehmen:
m zeigt an, dass Aufgabe m übermittelt werden soll (Zeile m+1)m- gibt an, alle Aufgaben ab Aufgabe m einzureichenmn gibt an, alle Aufgaben von m bis n (einschließlich) zu übermitteln. Das Flag --logging zeigt auf einen Speicherort für dsub Aufgabenprotokolldateien. Einzelheiten zur Angabe Ihres Protokollierungspfads finden Sie unter Protokollierung.
Es ist möglich, den Abschluss eines Auftrags abzuwarten, bevor mit dem nächsten begonnen wird. Einzelheiten finden Sie unter Jobsteuerung mit dsub.
Es ist möglich, dass dsub fehlgeschlagene Aufgaben automatisch wiederholt. Einzelheiten finden Sie unter Wiederholungsversuche mit dsub.
Sie können Aufträgen und Aufgaben benutzerdefinierte Beschriftungen hinzufügen, sodass Sie Aufgaben mithilfe Ihrer eigenen Kennungen überwachen und abbrechen können. Darüber hinaus werden bei den Google-Anbietern durch die Kennzeichnung einer Aufgabe zugehörige Rechenressourcen wie virtuelle Maschinen und Festplatten gekennzeichnet.
Weitere Einzelheiten finden Sie unter Status prüfen und Fehlerbehebung bei Jobs
Der Befehl dstat zeigt den Status von Jobs an:
dstat --provider google-cls-v2 --project my-cloud-project
Ohne zusätzliche Argumente zeigt dstat eine Liste der laufenden Jobs für den aktuellen USER an.
Um den Status eines bestimmten Jobs anzuzeigen, verwenden Sie das Flag --jobs :
dstat --provider google-cls-v2 --project my-cloud-project --jobs job-id
Bei einem Batch-Job listet die Ausgabe alle laufenden Aufgaben auf.
Jeder von dsub übermittelte Job erhält einen Satz Metadatenwerte, die zur Jobidentifizierung und Jobsteuerung verwendet werden können. Zu den mit jedem Job verknüpften Metadaten gehören:
job-name : Standardmäßig ist der Name Ihrer Skriptdatei oder das erste Wort Ihres Skriptbefehls; es kann explizit mit dem Parameter --name festgelegt werden.user-id : der Wert USER Umgebungsvariablen.job-id : Kennung des Jobs, die in Aufrufen von dstat und ddel zur Jobüberwachung bzw. zum Abbrechen des Jobs verwendet werden kann. Weitere Informationen zum job-id -Format finden Sie unter Job-IDs.task-id : Wenn der Job mit dem Parameter --tasks übermittelt wird, erhält jede Aufgabe einen sequentiellen Wert der Form „task -n “, wobei n 1-basiert ist.Beachten Sie, dass die Auftragsmetadatenwerte geändert werden, um den „Label-Einschränkungen“ zu entsprechen, die im Leitfaden „Status prüfen und Fehlerbehebung bei Aufträgen“ aufgeführt sind.
Metadaten können verwendet werden, um einen Job oder einzelne Aufgaben innerhalb eines Batch-Jobs abzubrechen.
Weitere Einzelheiten finden Sie unter Status prüfen und Fehlerbehebung bei Jobs
Standardmäßig gibt dstat eine Zeile pro Aufgabe aus. Wenn Sie einen Batch-Job mit vielen Aufgaben verwenden, können Sie von --summary profitieren.
$ dstat --provider google-cls-v2 --project my-project --status '*' --summary
Job Name Status Task Count
------------- ------------- -------------
my-job-name RUNNING 2
my-job-name SUCCESS 1
In diesem Modus druckt dstat eine Zeile pro Paar (Jobname, Aufgabenstatus). Sie können auf einen Blick sehen, wie viele Aufgaben abgeschlossen sind, wie viele noch ausgeführt werden und wie viele fehlgeschlagen/abgebrochen sind.
Der Befehl ddel löscht laufende Jobs.
Standardmäßig werden nur vom aktuellen Benutzer übermittelte Aufträge gelöscht. Verwenden Sie das Flag --users , um andere Benutzer anzugeben, oder '*' für alle Benutzer.
So löschen Sie einen laufenden Job:
ddel --provider google-cls-v2 --project my-cloud-project --jobs job-id
Wenn es sich bei dem Job um einen Batch-Job handelt, werden alle laufenden Aufgaben gelöscht.
So löschen Sie bestimmte Aufgaben:
ddel
--provider google-cls-v2
--project my-cloud-project
--jobs job-id
--tasks task-id1 task-id2
So löschen Sie alle laufenden Jobs für den aktuellen Benutzer:
ddel --provider google-cls-v2 --project my-cloud-project --jobs '*'
Wenn Sie den Befehl dsub mit dem Anbieter google-cls-v2 oder google-batch ausführen, müssen zwei verschiedene Sätze von Anmeldeinformationen berücksichtigt werden:
pipelines.run() Anfrage sendet, um Ihren Befehl/Skript auf einer VM auszuführen Bei dem Konto, das zum Senden der pipelines.run() -Anfrage verwendet wird, handelt es sich in der Regel um die Anmeldeinformationen Ihres Endbenutzers. Sie hätten dies eingerichtet, indem Sie Folgendes ausgeführt hätten:
gcloud auth application-default login
Das auf der VM verwendete Konto ist ein Dienstkonto. Das Bild unten verdeutlicht dies:
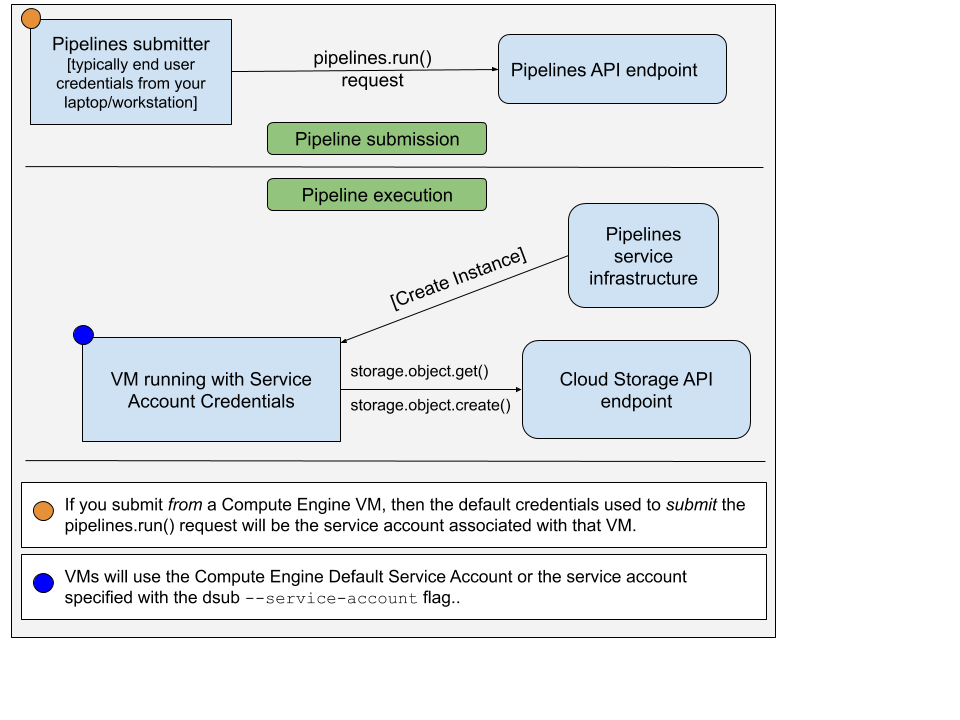
Standardmäßig verwendet dsub das standardmäßige Compute Engine-Dienstkonto als autorisiertes Dienstkonto auf der VM-Instanz. Sie können mit --service-account die E-Mail-Adresse eines anderen Dienstkontos angeben.
Standardmäßig gewährt dsub dem Dienstkonto die folgenden Zugriffsbereiche:
Darüber hinaus fügt die API immer diesen Bereich hinzu:
Sie können Bereiche mithilfe von --scopes angeben.
Obwohl es einfach ist, das Standarddienstkonto zu verwenden, verfügt dieses Konto standardmäßig auch über weitreichende Berechtigungen. Nach dem Prinzip der geringsten Rechte möchten Sie möglicherweise ein Dienstkonto erstellen und verwenden, das nur über ausreichende Rechte verfügt, um Ihren dsub -Befehl/Ihren dsub-Skript auszuführen.
Um ein neues Dienstkonto zu erstellen, führen Sie die folgenden Schritte aus:
Führen Sie den Befehl gcloud iam service-accounts create . Die E-Mail-Adresse des Dienstkontos lautet [email protected] .
gcloud iam service-accounts create "sa-name"
Gewähren Sie dem Dienstkonto IAM-Zugriff auf Buckets usw.
gsutil iam ch serviceAccount:[email protected]:roles/storage.objectAdmin gs://bucket-name
Aktualisieren Sie Ihren dsub -Befehl so, dass er --service-account enthält
dsub
--service-account [email protected]
...
Sehen Sie sich die Beispiele an:
Weitere Dokumentation finden Sie unter:


