SOLIDER
1.0.0

Willkommen bei SOLIDER ! SOLIDER ist ein semantisch kontrollierbares, selbstüberwachtes Lernframework zum Erlernen allgemeiner menschlicher Darstellungen aus massiven, unbeschrifteten menschlichen Bildern, was nachgelagerten, menschenzentrierten Aufgaben größtmöglichen Nutzen bringen kann. Im Gegensatz zu den bestehenden selbstüberwachten Lernmethoden wird in SOLIDER Vorwissen aus menschlichen Bildern genutzt, um pseudosemantische Etiketten zu erstellen und mehr semantische Informationen in die erlernte Darstellung zu importieren. Unterdessen erfordern verschiedene nachgelagerte Aufgaben immer unterschiedliche Verhältnisse semantischer Informationen und Erscheinungsinformationen, und eine einzelne erlernte Darstellung kann nicht alle Anforderungen erfüllen. Um dieses Problem zu lösen, führt SOLIDER ein bedingtes Netzwerk mit einem semantischen Controller ein, der unterschiedliche Anforderungen nachgelagerter Aufgaben erfüllen kann. Weitere Einzelheiten finden Sie in unserem Artikel Beyond Appearance: a Semantic Controllable Self-Supervised Learning Framework for Human-Centric Visual Tasks.
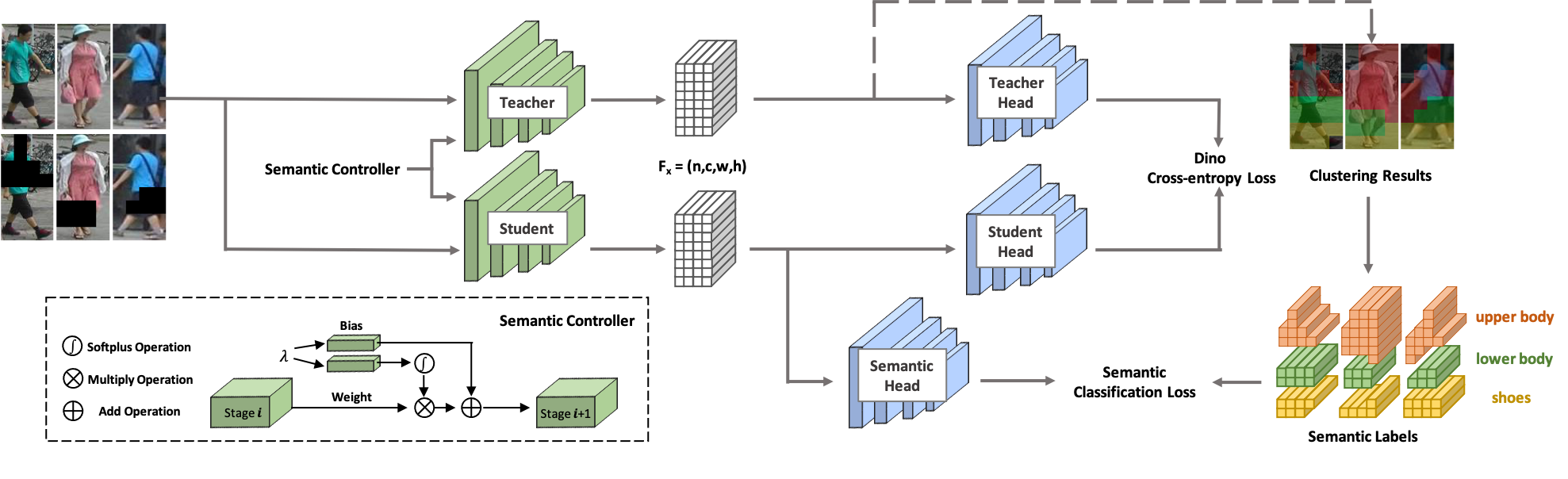
Diese Codebasis wurde mit Python Version 3.7, PyTorch Version 1.7.1, CUDA 10.1 und Torchvision 0.8.2 entwickelt.
Als Trainingsdaten verwenden wir LUPerson , das aus unbeschrifteten menschlichen Bildern besteht. Laden Sie LUPerson über den offiziellen Link herunter und entpacken Sie es.
sh run_solider.shsh run_dino.sh
sh resume_solider.shEs gibt eine Demo zum Ausführen des trainierten SOLIDER-Modells, das in die Inferenz oder die Feinabstimmung der nachgelagerten Aufgabe eingebettet werden kann.
python demo.pyWir verwenden Swin-Transformer als unser Rückgrat, was bei vielen CV-Aufgaben große Vorteile bietet.
| Aufgabe | Datensatz | Swin Tiny (Link) | Klein (Link) | Swin-Basis (Link) |
|---|---|---|---|---|
| Personen-Re-Identifizierung (mAP/R1) ohne Neubewertung | Markt1501 | 91,6/96,1 | 93,3/96,6 | 93,9/96,9 |
| MSMT17 | 67,4/85,9 | 76,9/90,8 | 77,1/90,7 | |
| Personen-Re-Identifizierung (mAP/R1) mit Neubewertung | Markt1501 | 95,3/96,6 | 95,4/96,4 | 95,6/96,7 |
| MSMT17 | 81,5/89,2 | 86,5/91,7 | 86,5/91,7 | |
| Attributerkennung (mA) | PETA_ZS | 74,37 | 76.21 | 76,43 |
| RAP_ZS | 74,23 | 75,95 | 76,42 | |
| PA100K | 84.14 | 86,25 | 86,37 | |
| Personensuche (mAP/R1) | CUHK-SYSU | 94,9/95,7 | 95,5/95,8 | 94,9/95,5 |
| PRW | 56,8/86,8 | 59,8/86,7 | 59,7/86,8 | |
| Fußgängererkennung (MR-2) | CityPersons | 10,3/40,8 | 10,0/39,2 | 9,7/39,4 |
| Human Parsing (mIOU) | LIPPE | 57,52 | 60.21 | 60,50 |
| Posenschätzung (AP/AR) | COCO | 74,4/79,6 | 76,3/81,3 | 76,6/81,5 |
Unsere Implementierung basiert hauptsächlich auf den folgenden Codebasen. Wir danken den Autoren herzlich für ihre wunderbaren Werke.
Wenn Sie SOLIDER in Ihrer Forschung verwenden, zitieren Sie unsere Arbeit bitte mithilfe des folgenden BibTeX-Eintrags:
@inproceedings{chen2023beyond,
title={Beyond Appearance: a Semantic Controllable Self-Supervised Learning Framework for Human-Centric Visual Tasks},
author={Weihua Chen and Xianzhe Xu and Jian Jia and Hao Luo and Yaohua Wang and Fan Wang and Rong Jin and Xiuyu Sun},
booktitle={The IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023},
}


