PixArt alpha
1.0.0
conda create -n pixart python=3.9
conda activate pixart
pip install torch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 --index-url https://download.pytorch.org/whl/cu118
git clone https://github.com/PixArt-alpha/PixArt-alpha.git
cd PixArt-alpha
pip install -r requirements.txtAlle Modelle werden automatisch heruntergeladen. Sie können die Datei auch manuell von dieser URL herunterladen.
| Modell | #Params | URL | In OpenXLab herunterladen |
|---|---|---|---|
| T5 | 4.3B | T5 | T5 |
| VAE | 80M | VAE | VAE |
| PixArt-α-SAM-256 | 0,6B | PixArt-XL-2-SAM-256x256.pth oder Diffusorversion | 256-SAM |
| PixArt-α-256 | 0,6B | PixArt-XL-2-256x256.pth oder Diffusorversion | 256 |
| PixArt-α-256-MSCOCO-FID7.32 | 0,6B | PixArt-XL-2-256x256.pth | 256 |
| PixArt-α-512 | 0,6B | PixArt-XL-2-512x512.pth oder Diffusorversion | 512 |
| PixArt-α-1024 | 0,6B | PixArt-XL-2-1024-MS.pth oder Diffusorversion | 1024 |
| PixArt-δ-1024-LCM | 0,6B | Diffusorversion | |
| ControlNet-HED-Encoder | 30M | ControlNetHED.pth | |
| PixArt-δ-512-ControlNet | 0,9B | PixArt-XL-2-512-ControlNet.pth | 512 |
| PixArt-δ-1024-ControlNet | 0,9B | PixArt-XL-2-1024-ControlNet.pth | 1024 |
Alle Modelle finden Sie AUCH in OpenXLab_PixArt-alpha
Erstens.
Dank @kopyl können Sie den gesamten Feinabstimmungs-Trainingsablauf für den Pokemon-Datensatz von HugginFace mit Notebooks reproduzieren:
Dann für weitere Details.
Hier nehmen wir die SAM-Datensatz-Trainingskonfiguration als Beispiel, aber natürlich können Sie mit dieser Methode auch Ihren eigenen Datensatz vorbereiten.
Sie müssen NUR die Konfigurationsdatei in config und den Dataloader im Datensatz ändern.
python -m torch.distributed.launch --nproc_per_node=2 --master_port=12345 train_scripts/train.py configs/pixart_config/PixArt_xl2_img256_SAM.py --work-dir output/train_SAM_256Die Verzeichnisstruktur für den SAM-Datensatz ist:
cd ./data
SA1B
├──images/ (images are saved here)
│ ├──sa_xxxxx.jpg
│ ├──sa_xxxxx.jpg
│ ├──......
├──captions/ (corresponding captions are saved here, same name as images)
│ ├──sa_xxxxx.txt
│ ├──sa_xxxxx.txt
├──partition/ (all image names are stored txt file where each line is a image name)
│ ├──part0.txt
│ ├──part1.txt
│ ├──......
├──caption_feature_wmask/ (run tools/extract_caption_feature.py to generate caption T5 features, same name as images except .npz extension)
│ ├──sa_xxxxx.npz
│ ├──sa_xxxxx.npz
│ ├──......
├──img_vae_feature/ (run tools/extract_img_vae_feature.py to generate image VAE features, same name as images except .npy extension)
│ ├──train_vae_256/
│ │ ├──noflip/
│ │ │ ├──sa_xxxxx.npy
│ │ │ ├──sa_xxxxx.npy
│ │ │ ├──......
Hier bereiten wir data_toy zum besseren Verständnis vor
cd ./data
git lfs install
git clone https://huggingface.co/datasets/PixArt-alpha/data_toyDann ist hier ein Beispiel für die Datei „partition/part0.txt“.
Außerdem finden Sie hier für das JSON-Datei-gesteuerte Training eine Spielzeug-JSON-Datei zum besseren Verständnis.
Befolgen Sie die Schulungsanleitung Pixart + DreamBooth
Befolgen Sie die Schulungsanleitung PixArt + LCM
Befolgen Sie die Schulungsanleitung PixArt + ControlNet
pip install peft==0.6.2
accelerate launch --num_processes=1 --main_process_port=36667 train_scripts/train_pixart_lora_hf.py --mixed_precision= " fp16 "
--pretrained_model_name_or_path=PixArt-alpha/PixArt-XL-2-1024-MS
--dataset_name=lambdalabs/pokemon-blip-captions --caption_column= " text "
--resolution=1024 --random_flip
--train_batch_size=16
--num_train_epochs=200 --checkpointing_steps=100
--learning_rate=1e-06 --lr_scheduler= " constant " --lr_warmup_steps=0
--seed=42
--output_dir= " pixart-pokemon-model "
--validation_prompt= " cute dragon creature " --report_to= " tensorboard "
--gradient_checkpointing --checkpoints_total_limit=10 --validation_epochs=5
--rank=16 Inferenz erfordert bei Verwendung dieses Repositorys mindestens 23GB GPU-Speicher, bei Verwendung in 11GB and 8GB ? Diffusoren.
Unterstützt derzeit:
Installieren Sie zunächst die erforderlichen Abhängigkeiten. Stellen Sie sicher, dass Sie die Modelle in den Ordner „output/pretrained_models“ heruntergeladen haben, und führen Sie sie dann auf Ihrem lokalen Computer aus:
DEMO_PORT=12345 python app/app.pyAlternativ wird eine Beispiel-Dockerdatei bereitgestellt, um einen Laufzeitcontainer zu erstellen, der die Gradio-App startet.
docker build . -t pixart
docker run --gpus all -it -p 12345:12345 -v < path_to_huggingface_cache > :/root/.cache/huggingface pixartOder verwenden Sie Docker-Compose. Beachten Sie: Wenn Sie den Kontext von der 1024- auf die 512- oder LCM-Version der App ändern möchten, ändern Sie einfach die Umgebungsvariable APP_CONTEXT in der Datei docker-compose.yml. Der Standardwert ist 1024
docker compose build
docker compose up Schauen wir uns ein einfaches Beispiel mit http://your-server-ip:12345 an.
Stellen Sie sicher, dass Sie über die aktualisierten Versionen der folgenden Bibliotheken verfügen:
pip install -U transformers accelerate diffusers SentencePiece ftfy beautifulsoup4Und dann:
import torch
from diffusers import PixArtAlphaPipeline , ConsistencyDecoderVAE , AutoencoderKL
device = torch . device ( "cuda:0" if torch . cuda . is_available () else "cpu" )
# You can replace the checkpoint id with "PixArt-alpha/PixArt-XL-2-512x512" too.
pipe = PixArtAlphaPipeline . from_pretrained ( "PixArt-alpha/PixArt-XL-2-1024-MS" , torch_dtype = torch . float16 , use_safetensors = True )
# If use DALL-E 3 Consistency Decoder
# pipe.vae = ConsistencyDecoderVAE.from_pretrained("openai/consistency-decoder", torch_dtype=torch.float16)
# If use SA-Solver sampler
# from diffusion.sa_solver_diffusers import SASolverScheduler
# pipe.scheduler = SASolverScheduler.from_config(pipe.scheduler.config, algorithm_type='data_prediction')
# If loading a LoRA model
# transformer = Transformer2DModel.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", subfolder="transformer", torch_dtype=torch.float16)
# transformer = PeftModel.from_pretrained(transformer, "Your-LoRA-Model-Path")
# pipe = PixArtAlphaPipeline.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", transformer=transformer, torch_dtype=torch.float16, use_safetensors=True)
# del transformer
# Enable memory optimizations.
# pipe.enable_model_cpu_offload()
pipe . to ( device )
prompt = "A small cactus with a happy face in the Sahara desert."
image = pipe ( prompt ). images [ 0 ]
image . save ( "./catcus.png" )Weitere Informationen zu SA-Solver Sampler finden Sie in der Dokumentation.
Diese Integration ermöglicht den Betrieb der Pipeline mit einer Batchgröße von 4 unter 11 GB GPU-VRAM. Schauen Sie sich die Dokumentation an, um mehr zu erfahren.
PixArtAlphaPipeline mit weniger als 8 GB GPU-VRAMDer GPU-VRAM-Verbrauch unter 8 GB wird jetzt unterstützt. Weitere Informationen finden Sie in der Dokumentation.
Um zu beginnen, installieren Sie zunächst die erforderlichen Abhängigkeiten und führen Sie sie dann auf Ihrem lokalen Computer aus:
# diffusers version
DEMO_PORT=12345 python app/app.py Schauen wir uns ein einfaches Beispiel mit http://your-server-ip:12345 an.
Sie können auch hier klicken, um eine kostenlose Testversion von Google Colab zu erhalten.
python tools/convert_pixart_alpha_to_diffusers.py --image_size your_img_size --multi_scale_train (True if you use PixArtMS else False) --orig_ckpt_path path/to/pth --dump_path path/to/diffusers --only_transformer=True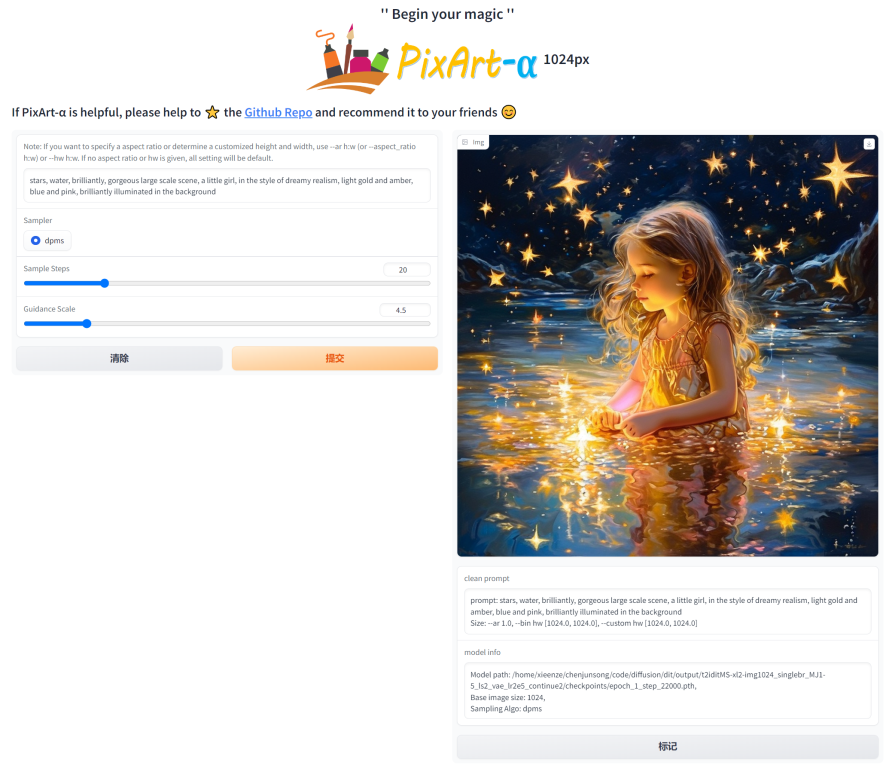
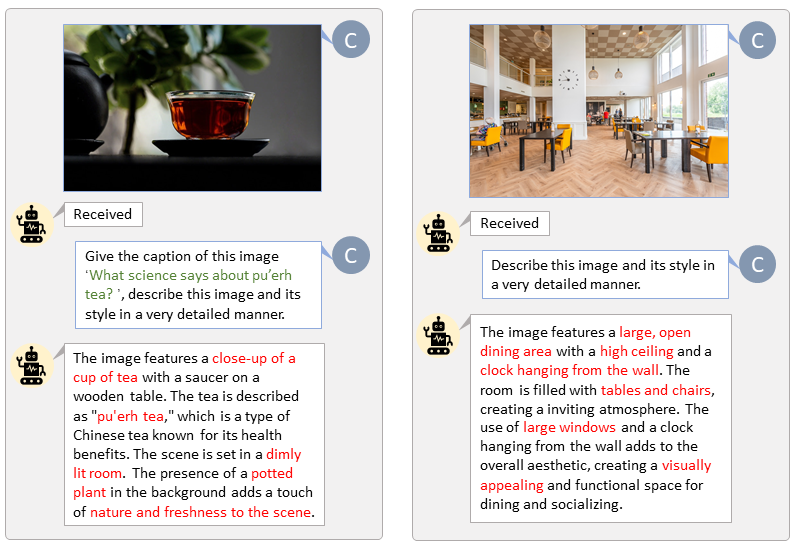
Dank der Codebasis von LLaVA-Lightning-MPT können wir den LAION- und SAM-Datensatz mit dem folgenden Startcode beschriften:
python tools/VLM_caption_lightning.py --output output/dir/ --data-root data/root/path --index path/to/data.jsonWir präsentieren die automatische Beschriftung mit benutzerdefinierten Eingabeaufforderungen für LAION (links) und SAM (rechts). Die grün hervorgehobenen Wörter stellen die Originalunterschrift in LAION dar, während die rot markierten Wörter die von LLaVA gekennzeichneten detaillierten Untertitel anzeigen.
Bereiten Sie die T5-Textfunktion und die VAE-Bildfunktion im Voraus vor, um den Trainingsprozess zu beschleunigen und GPU-Speicher zu sparen.
python tools/extract_features.py --img_size=1024
--json_path " data/data_info.json "
--t5_save_root " data/SA1B/caption_feature_wmask "
--vae_save_root " data/SA1B/img_vae_features "
--pretrained_models_dir " output/pretrained_models "
--dataset_root " data/SA1B/Images/ " Wir erstellen ein Video, in dem PixArt mit den derzeit leistungsstärksten Text-to-Image-Modellen verglichen wird.
@misc{chen2023pixartalpha,
title={PixArt-$alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis},
author={Junsong Chen and Jincheng Yu and Chongjian Ge and Lewei Yao and Enze Xie and Yue Wu and Zhongdao Wang and James Kwok and Ping Luo and Huchuan Lu and Zhenguo Li},
year={2023},
eprint={2310.00426},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{chen2024pixartdelta,
title={PIXART-{delta}: Fast and Controllable Image Generation with Latent Consistency Models},
author={Junsong Chen and Yue Wu and Simian Luo and Enze Xie and Sayak Paul and Ping Luo and Hang Zhao and Zhenguo Li},
year={2024},
eprint={2401.05252},
archivePrefix={arXiv},
primaryClass={cs.CV}
}


