Agent FLAN
1.0.0
[? HuggingFace] [? OpenXLab] [? Papier] [Projektseite]
Open-Source-Large-Language-Modelle (LLMs) haben bei verschiedenen NLP-Aufgaben große Erfolge erzielt, sind jedoch als Agenten API-basierten Modellen immer noch weit unterlegen. Die Integration der Agentenfähigkeiten in allgemeine LLMs wird zu einem entscheidenden und dringenden Problem. Dieses Papier liefert zunächst drei wichtige Beobachtungen: (1) Das aktuelle Agententrainingskorpus ist sowohl mit der Formatverfolgung als auch mit dem Agentenschlussfolgern verknüpft, was sich erheblich von der Verteilung seiner Daten vor dem Training unterscheidet; (2) LLMs weisen unterschiedliche Lerngeschwindigkeiten hinsichtlich der für Agentenaufgaben erforderlichen Fähigkeiten auf; und (3) aktuelle Ansätze haben Nebenwirkungen bei der Verbesserung der Agentenfähigkeiten durch die Einführung von Halluzinationen. Basierend auf den oben genannten Erkenntnissen schlagen wir Agent-FLAN zur effektiven Feinabstimmung von Sprachmodellen für Agenten vor. Durch sorgfältige Zerlegung und Neugestaltung des Trainingskorpus ermöglicht Agent-FLAN, dass Llama2-7B frühere Bestarbeiten in verschiedenen Agentenbewertungsdatensätzen um 3,5 % übertrifft. Mit umfassend konstruierten Negativproben lindert Agent-FLAN die Halluzinationsprobleme auf der Grundlage unseres etablierten Bewertungsmaßstabs erheblich. Darüber hinaus wird die Agentenfähigkeit von LLMs bei der Skalierung von Modellgrößen kontinuierlich verbessert, während die allgemeine Fähigkeit von LLMs leicht verbessert wird.
Die Agent-FLAN-Serien werden auf AgentInstruct und Toolbench verfeinert, indem die im Agent-FLAN-Papier vorgeschlagene Datengenerierungspipeline angewendet wird, die über starke Fähigkeiten bei verschiedenen Agentenaufgaben und der Tool-Nutzung verfügt
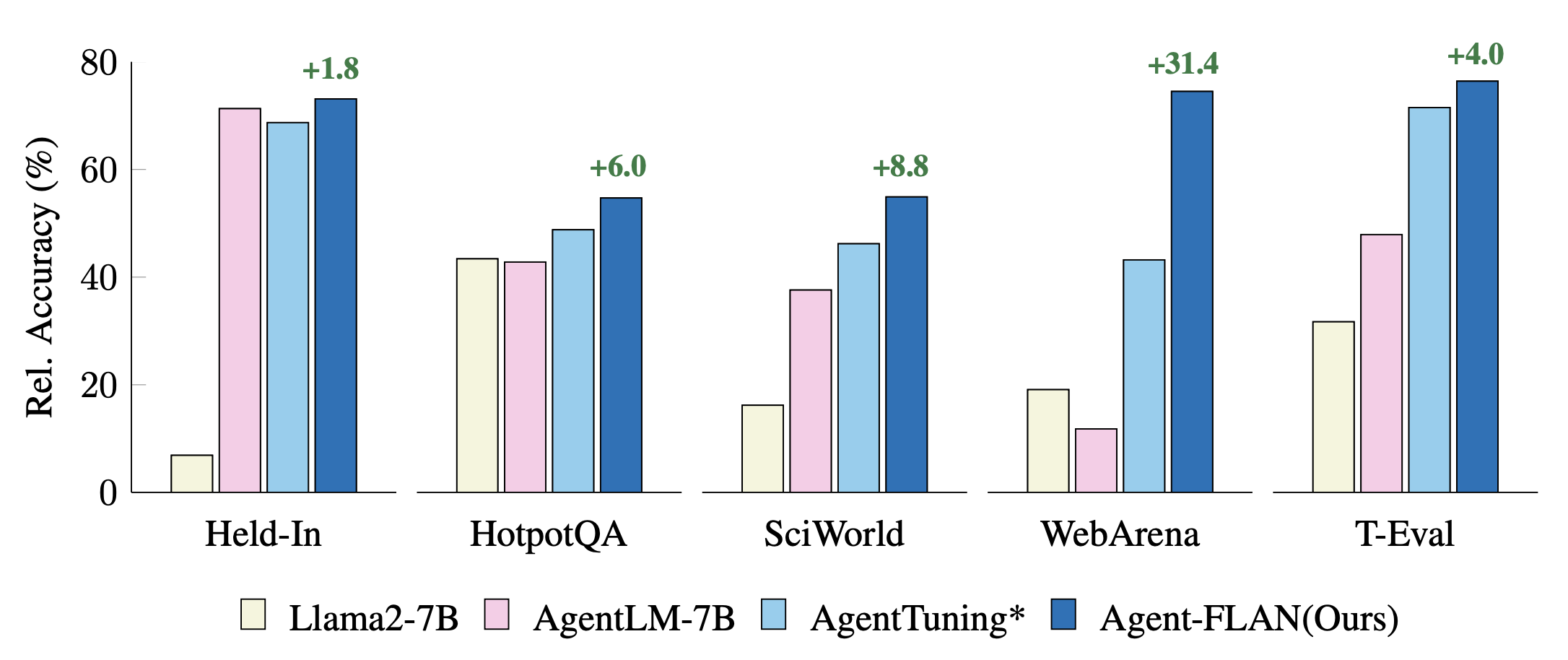
Vergleich aktueller Agent-Tuning-Ansätze für Held-In- und Held-Out-Aufgaben. Zur besseren Visualisierung werden die Leistungen mit GPT-4-Ergebnissen normalisiert. * bezeichnet unsere Neuimplementierung für einen fairen Vergleich.
Agent-FLAN wird durch gemischtes Training mit AgentInstruct-, ToolBench- und ShareGPT-Datensätzen aus der Llama2-Chat-Reihe erstellt.
Die Modelle folgen dem Konversationsformat von Llama-2-chat mit dem Vorlagenprotokoll wie folgt:
dict ( role = 'user' , begin = '<|Human|>െ' , end = ' n ' ),
dict ( role = 'system' , begin = '<|Human|>െ' , end = ' n ' ),
dict ( role = 'assistant' , begin = '<|Assistant|>െ' , end = 'ി n ' ),Das 7B-Modell ist auf dem Huggingface- und OpenXLab-Modellhub verfügbar.
| Modell | Huggingface Repo | OpenXLab-Repo |
|---|---|---|
| Agent-FLAN-7B | Modelllink | Modelllink |
Der Agent-FLAN-Datensatz ist auch im Huggingface-Datensatz-Hub verfügbar.
| Datensatz | Huggingface Repo |
|---|---|
| Agent-FLAN | Datensatz-Link |
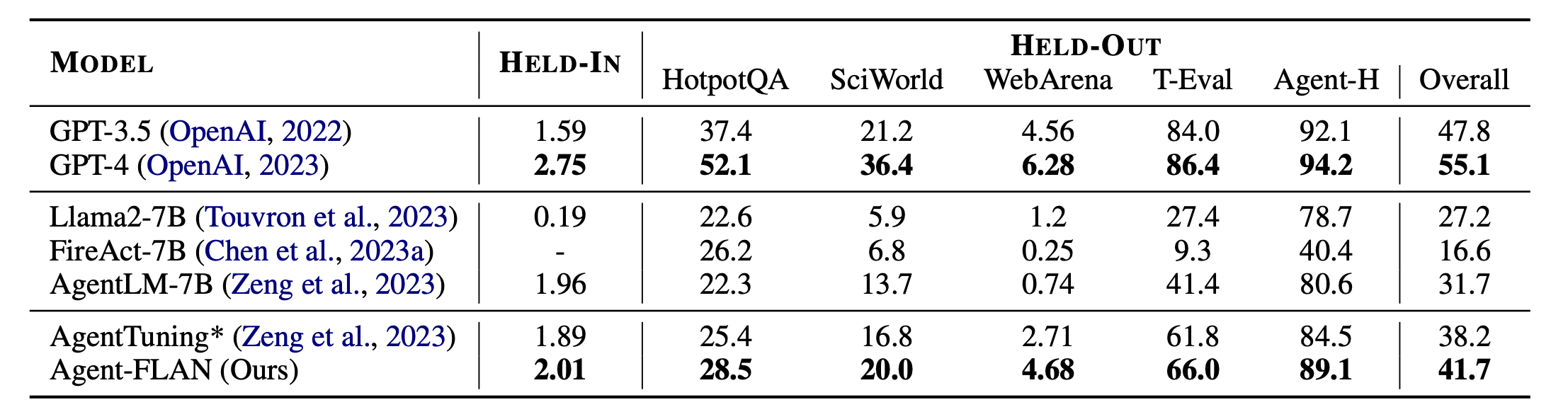
Hauptergebnisse von Agent-FLAN. Agent-FLAN übertrifft frühere Agent-Tuning-Ansätze bei weitem, sowohl bei zurückgehaltenen als auch bei zurückgehaltenen Aufgaben. * bezeichnet unsere Neuimplementierung mit der gleichen Menge an Trainingsdaten für einen fairen Vergleich. Da FireAct nicht auf dem AgentInstruct-Datensatz trainiert, lassen wir seine Leistung für den HELD-IN-Satz weg. Bold: das Beste an API-basierten und Open-Source-Modellen.
Agent-FLAN wird mit Lagent und T-Eval erstellt. Vielen Dank für ihre tolle Arbeit!
Wenn Sie dieses Projekt für Ihre Forschung nützlich finden, ziehen Sie bitte Folgendes in Betracht:
@article{chen2024agent,
title={Agent-FLAN: Designing Data and Methods of Effective Agent Tuning for Large Language Models},
author={Chen, Zehui and Liu, Kuikun and Wang, Qiuchen and Zhang, Wenwei and Liu, Jiangning and Lin, Dahua and Chen, Kai and Zhao, Feng},
journal={arXiv preprint arXiv:2403.12881},
year={2024}
}
Dieses Projekt wird unter der Apache 2.0-Lizenz veröffentlicht.


