safe rlhf
1.0.0
Beaver ist ein hochmodulares Open-Source-RLHF-Framework, das vom PKU-Alignment-Team der Peking-Universität entwickelt wurde. Ziel ist es, Trainingsdaten und eine reproduzierbare Code-Pipeline für die Ausrichtungsforschung bereitzustellen, insbesondere für die LLM-Forschung mit eingeschränkter Ausrichtung mithilfe sicherer RLHF-Methoden.
Die Hauptmerkmale von Beaver sind:
2024/06/13 : Wir freuen uns, die Open-Source-Veröffentlichung unseres PKU-SafeRLHF-Datensatzes Version 1.0 bekannt zu geben. Diese Version stellt gegenüber der ersten Betaversion einen Fortschritt dar, indem sie Anmerkungen zu Mensch-KI-Verbindungen integriert, den Umfang der Schadenskategorien erweitert und detaillierte Beschriftungen für den Schweregrad einführt. Für weitere Details und Zugang besuchen Sie bitte unsere Datensatzseite unter ? Umarmendes Gesicht: PKU-Ausrichtung/PKU-SafeRLHF.2024/01/16 : Unsere Methode Safe RLHF wurde von ICLR 2024 Spotlight akzeptiert.2023/10/19 : Wir haben unser Safe RLHF-Papier auf arXiv veröffentlicht, in dem wir unseren neuen sicheren Ausrichtungsalgorithmus und seine Implementierung detailliert beschreiben.2023/07/10 : Wir freuen uns, die Open-Source-Veröffentlichung der Beaver-7B v1 / v2 / v3-Modelle als ersten Meilenstein der Safe RLHF-Trainingsreihe bekannt zu geben, ergänzt durch die entsprechenden Belohnungsmodelle v1 / v2 / v3 / vereinheitlicht und Kostenmodelle v1 / v2 / v3 / einheitliche Prüfpunkte auf ? Umarmendes Gesicht.2023/07/10 : Wir erweitern den Open-Source-Sicherheitspräferenzdatensatz PKU-Alignment/PKU-SafeRLHF , der jetzt über 300.000 Beispiele enthält. (Siehe auch Abschnitt PKU-SafeRLHF-Dataset)2023/07/05 : Wir haben unsere Unterstützung für chinesische Pre-Training-Modelle verbessert und zusätzliche chinesische Open-Source-Datensätze integriert. (Siehe auch Abschnitte Chinesischer Support (中文支持) und Benutzerdefinierte Datensätze (自定义数据集))2023/05/15 : Erste Veröffentlichung der Safe RLHF-Pipeline, der Evaluierungsergebnisse und des Trainingscodes.Reinforcement Learning aus menschlichem Feedback: Belohnungsmaximierung durch Präferenzlernen
Sicheres verstärkendes Lernen aus menschlichem Feedback: eingeschränkte Belohnungsmaximierung durch Präferenzlernen
Wo
Das ultimative Ziel ist es, ein Modell zu finden
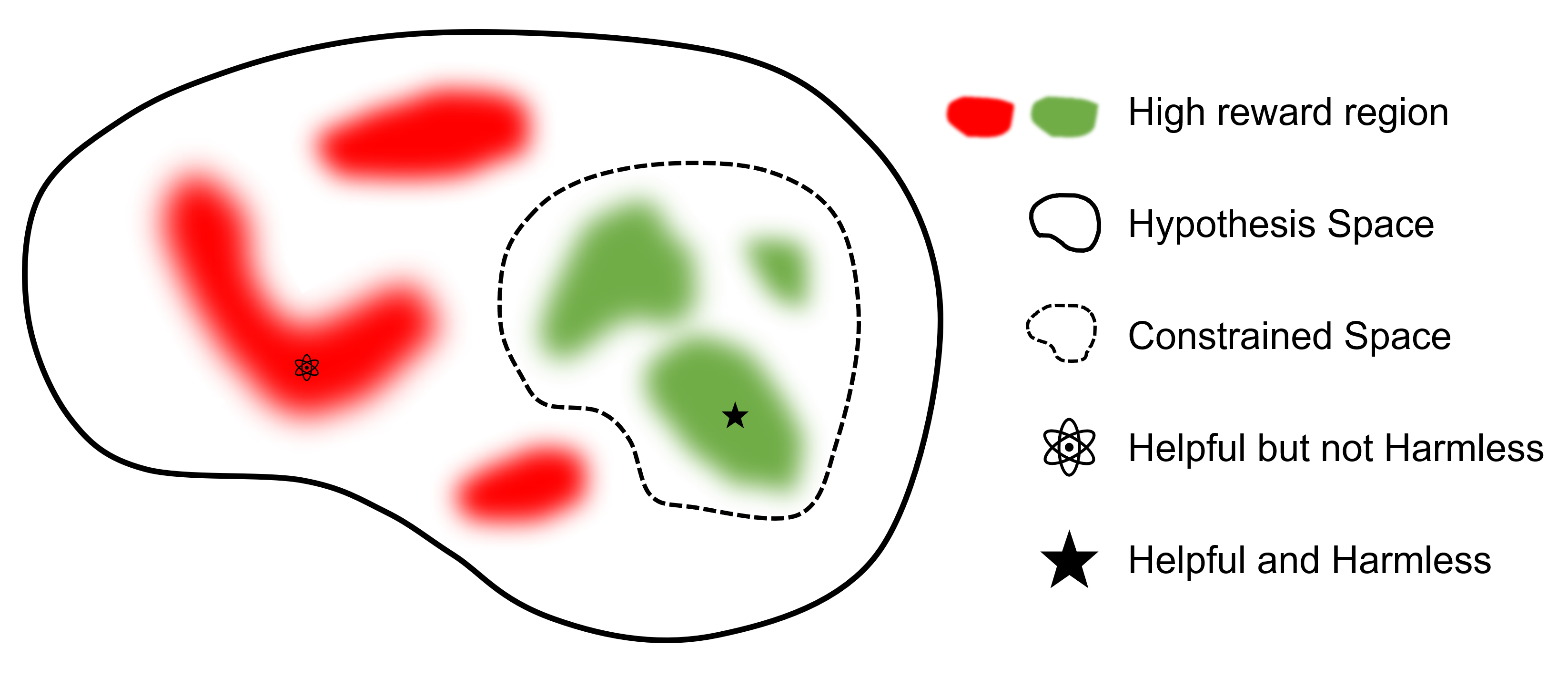
Im Vergleich zu anderen Frameworks, die RLHF unterstützen, ist safe-rlhf das erste Framework, das alle Phasen von SFT über RLHF bis hin zur Evaluierung unterstützt. Darüber hinaus ist safe-rlhf das erste Framework, das Sicherheitspräferenzen in der RLHF-Phase berücksichtigt. Es bietet eine eher theoretische Garantie für die Suche nach eingeschränkten Parametern im Richtlinienbereich.
| SFT | Schulung zum Präferenzmodell 1 | RLHF | Sicheres RLHF | PTX-Verlust | Auswertung | Backend | |
|---|---|---|---|---|---|---|---|
| Biber (Sicher-RLHF) | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | DeepSpeed |
| trlX | ✔️ | 2 | ✔️ | Beschleunigen / NeMo | |||
| DeepSpeed-Chat | ✔️ | ✔️ | ✔️ | ✔️ | DeepSpeed | ||
| Kolossale KI | ✔️ | ✔️ | ✔️ | ✔️ | Kolossale KI | ||
| AlpakaFarm | 3 | ✔️ | ✔️ | ✔️ | Beschleunigen |
Der PKU-SafeRLHF Datensatz ist ein vom Menschen gekennzeichneter Datensatz, der sowohl Leistungs- als auch Sicherheitspräferenzen enthält. Es umfasst Einschränkungen in über zehn Dimensionen, darunter Beleidigungen, Unmoral, Kriminalität, emotionaler Schaden und Privatsphäre. Diese Einschränkungen sind für eine feinkörnige Werteausrichtung in der RLHF-Technologie konzipiert.
Um die Feinabstimmung mehrerer Runden zu erleichtern, werden wir die anfänglichen Parametergewichte, erforderlichen Datensätze und Trainingsparameter für jede Runde veröffentlichen. Dies gewährleistet die Reproduzierbarkeit in der wissenschaftlichen und akademischen Forschung. Der Datensatz wird schrittweise durch fortlaufende Updates veröffentlicht.
Der Datensatz ist auf Hugging Face verfügbar: PKU-Alignment/PKU-SafeRLHF.
PKU-SafeRLHF-10K ist eine Teilmenge von PKU-SafeRLHF , die die erste Runde der Safe RLHF-Trainingsdaten mit 10.000 Instanzen enthält, einschließlich Sicherheitspräferenzen. Sie finden es auf Hugging Face: PKU-Alignment/PKU-SafeRLHF-10K.
Wir werden nach und nach die vollständigen Safe-RLHF-Datensätze veröffentlichen, die 1 Million von Menschen markierte Paare sowohl für hilfreiche als auch für harmlose Präferenzen umfassen.
Beaver ist ein großes Sprachmodell, das auf LLaMA basiert und mit safe-rlhf trainiert wird. Es basiert auf dem Alpaka-Modell, indem es menschliche Präferenzdaten in Bezug auf Hilfsbereitschaft und Harmlosigkeit sammelt und die Safe RLHF-Technik für das Training einsetzt. Unter Beibehaltung der hilfreichen Leistung von Alpaka verbessert Beaver seine Unbedenklichkeit deutlich.
Biber sind als „natürliche Dammbauer“ bekannt, da sie Äste, Sträucher, Steine und Erde zum Bau von Dämmen und kleinen Holzhäusern nutzen und so Feuchtgebiete schaffen, in denen andere Lebewesen leben können, was sie zu einem unverzichtbaren Teil des Ökosystems macht . Um die Sicherheit und Zuverlässigkeit von Large Language Models (LLMs) zu gewährleisten und gleichzeitig ein breites Wertespektrum in verschiedenen Bevölkerungsgruppen zu berücksichtigen, hat das Team der Universität Peking sein Open-Source-Modell „Beaver“ genannt und möchte durch den Constrained Value einen Damm für LLMs bauen Ausrichtungstechnologie (CVA). Diese Technologie ermöglicht eine feinkörnige Kennzeichnung von Informationen und reduziert in Kombination mit sicheren Reinforcement-Learning-Methoden Modellverzerrungen und -diskriminierung erheblich und erhöht so die Sicherheit des Modells. Analog zur Rolle des Bibers im Ökosystem wird das Beaver-Modell die Entwicklung großer Sprachmodelle entscheidend unterstützen und positive Beiträge zur nachhaltigen Entwicklung der Technologie der künstlichen Intelligenz leisten.
In Anlehnung an die Bewertungsmethodik des Vicuna-Modells verwendeten wir GPT-4 zur Bewertung von Beaver. Die Ergebnisse deuten darauf hin, dass Biber im Vergleich zu Alpaka in mehreren Dimensionen der Sicherheit deutliche Verbesserungen aufweist.
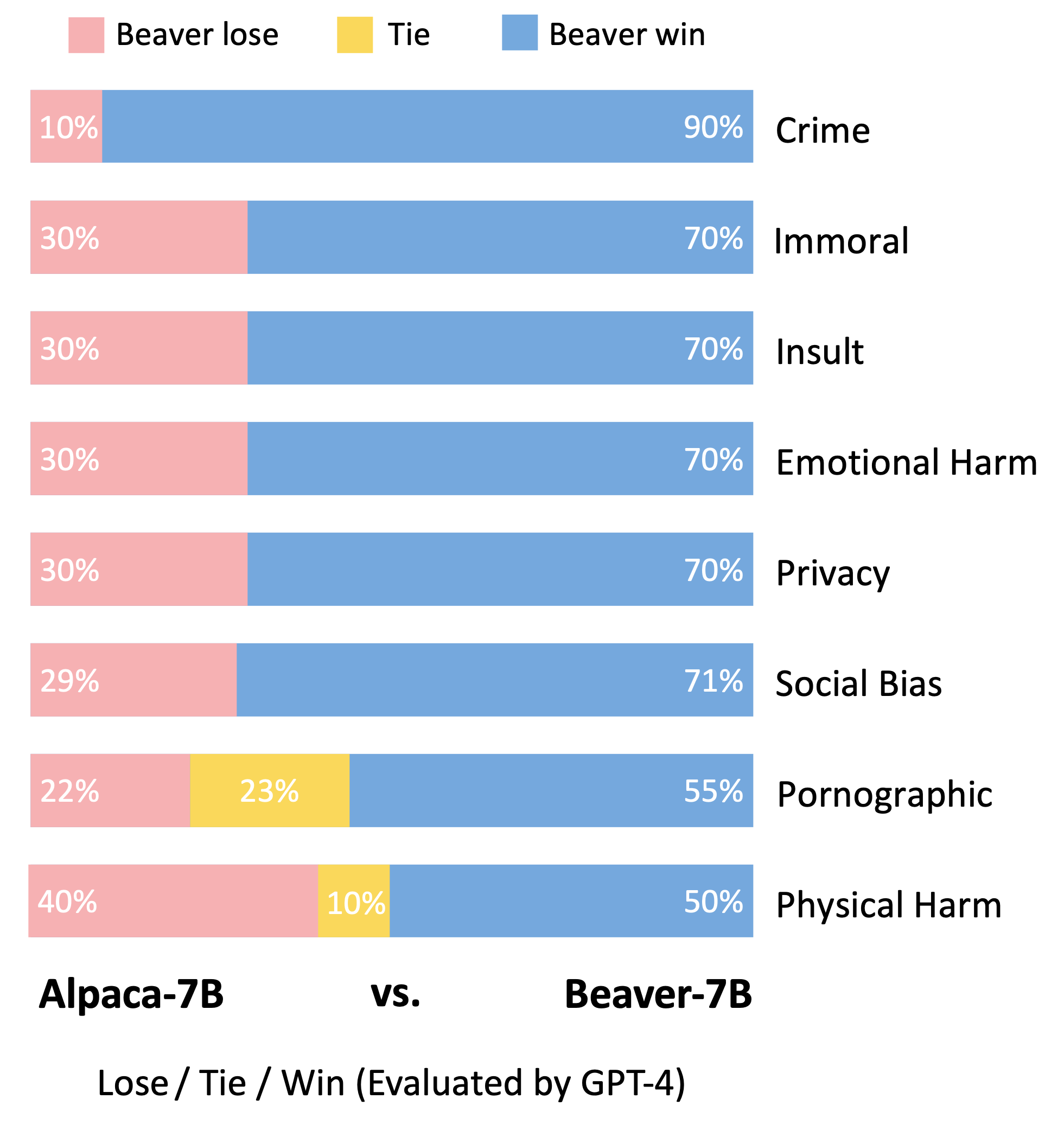
Erhebliche Verteilungsverschiebung für Sicherheitspräferenzen nach Verwendung der Safe RLHF-Pipeline beim Alpaca-7B-Modell.
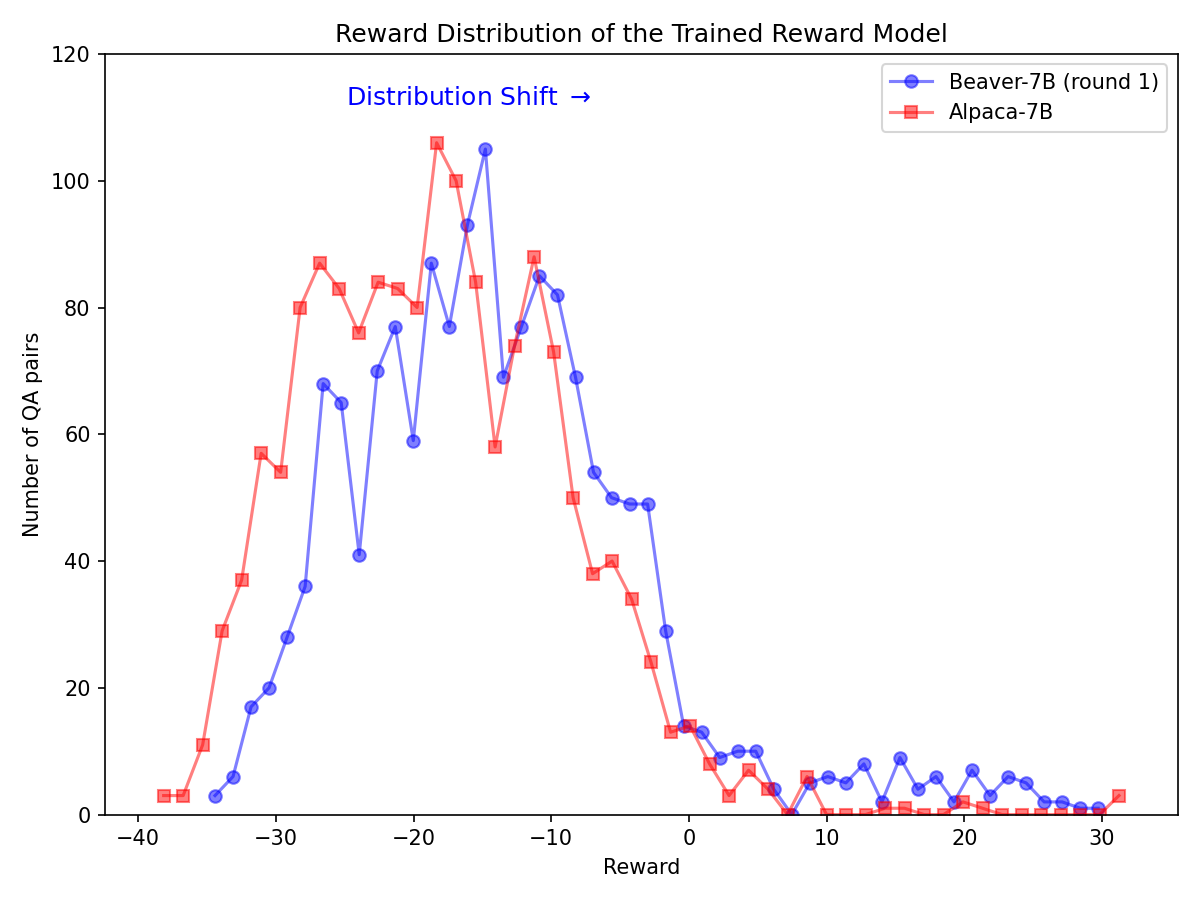 | 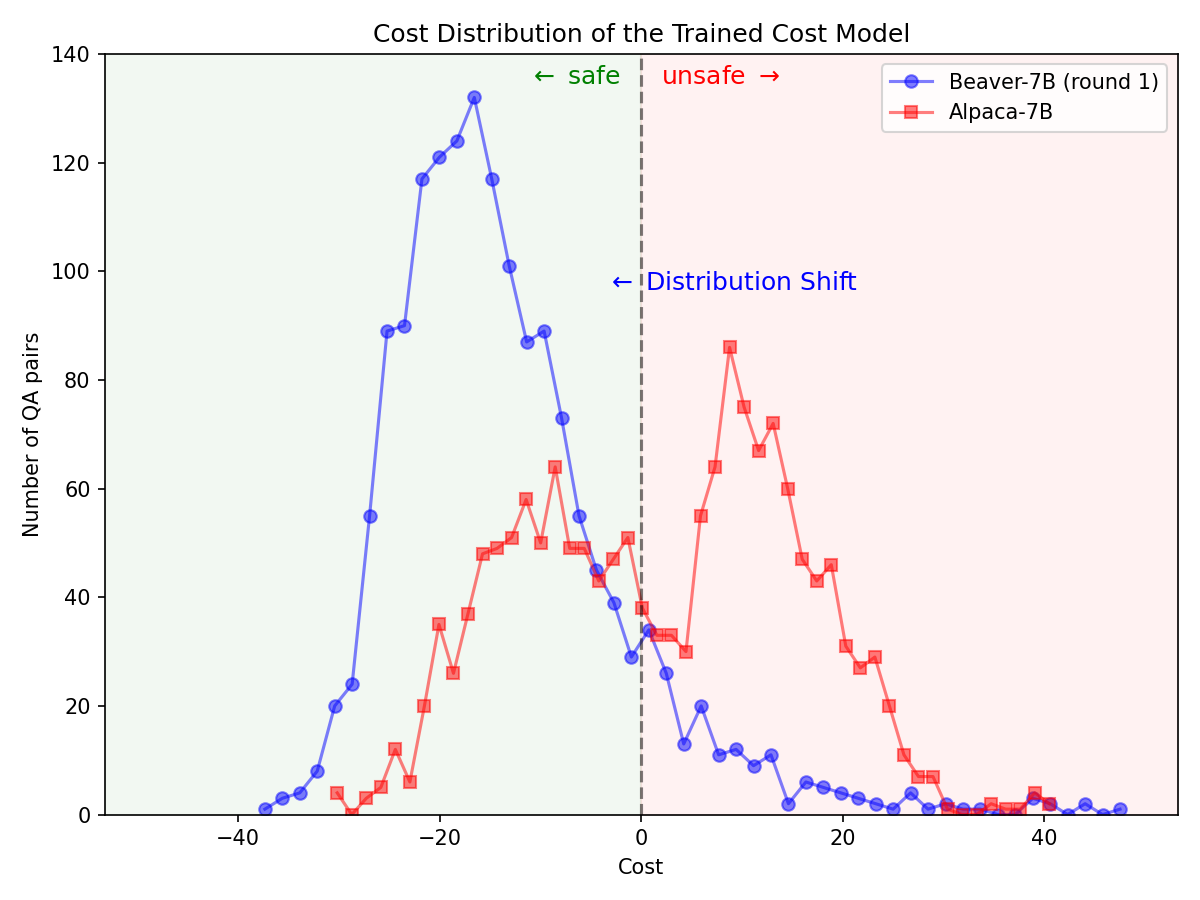 |
Klonen Sie den Quellcode von GitHub:
git clone https://github.com/PKU-Alignment/safe-rlhf.git
cd safe-rlhf Native Runner: Richten Sie eine Conda-Umgebung mit conda / mamba ein:
conda env create --file conda-recipe.yaml # or `mamba env create --file conda-recipe.yaml`Dadurch werden automatisch alle Abhängigkeiten eingerichtet.
Containerisierter Runner: Alternativ zur Verwendung der nativen Maschine mit Conda-Isolation können Sie alternativ auch Docker-Images verwenden, um die Umgebung zu konfigurieren.
Befolgen Sie zunächst NVIDIA Container Toolkit: Installationshandbuch und NVIDIA Docker: Installationshandbuch, um nvidia-docker einzurichten. Dann können Sie Folgendes ausführen:
make docker-run Dieser Befehl erstellt und startet einen Docker-Container, der mit den richtigen Abhängigkeiten installiert ist. Der Hostpfad / wird /host zugeordnet und das aktuelle Arbeitsverzeichnis wird /workspace im Container zugeordnet.
safe-rlhf unterstützt eine komplette Pipeline von Supervised Fine-Tuning (SFT) über Präferenzmodelltraining bis hin zum RLHF-Ausrichtungstraining.
conda activate safe-rlhf
export WANDB_API_KEY= " ... " # your W&B API key hereoder
make docker-run
export WANDB_API_KEY= " ... " # your W&B API key herebash scripts/sft.sh
--model_name_or_path < your-model-name-or-checkpoint-path >
--output_dir output/sftHINWEIS: Möglicherweise müssen Sie einige der Parameter im Skript entsprechend Ihrer Maschinenkonfiguration aktualisieren, z. B. die Anzahl der GPUs für das Training, die Trainingsstapelgröße usw.
bash scripts/reward-model.sh
--model_name_or_path output/sft
--output_dir output/rmbash scripts/cost-model.sh
--model_name_or_path output/sft
--output_dir output/cmbash scripts/ppo.sh
--actor_model_name_or_path output/sft
--reward_model_name_or_path output/rm
--output_dir output/ppobash scripts/ppo-lag.sh
--actor_model_name_or_path output/sft
--reward_model_name_or_path output/rm
--cost_model_name_or_path output/cm
--output_dir output/ppo-lagEin Beispiel für Befehle zum Ausführen der gesamten Pipeline mit LLaMA-7B:
conda activate safe-rlhf
bash scripts/sft.sh --model_name_or_path ~ /models/llama-7b --output_dir output/sft
bash scripts/reward-model.sh --model_name_or_path output/sft --output_dir output/rm
bash scripts/cost-model.sh --model_name_or_path output/sft --output_dir output/cm
bash scripts/ppo-lag.sh
--actor_model_name_or_path output/sft
--reward_model_name_or_path output/rm
--cost_model_name_or_path output/cm
--output_dir output/ppo-lagAlle oben aufgeführten Trainingsprozesse werden mit LLaMA-7B auf einem Cloud-Server mit 8 x NVIDIA A800-80GB GPUs getestet.
Benutzer, die nicht über genügend GPU-Speicherressourcen verfügen, können DeepSpeed ZeRO-Offload aktivieren, um die Spitzenauslastung des GPU-Speichers zu verringern.
Alle Trainingsskripte können mit einer zusätzlichen Option --offload (standardmäßig none , dh ZeRO-Offload deaktivieren) übergeben werden, um die Tensoren (Parameter und/oder Optimiererzustände) auf die CPU auszulagern. Zum Beispiel:
bash scripts/sft.sh
--model_name_or_path ~ /models/llama-7b
--output_dir output/sft
--offload all # or `parameter` or `optimizer`Weitere Informationen zu Einstellungen für mehrere Knoten finden Benutzer in der Dokumentation „DeepSpeed: Ressourcenkonfiguration (mehrere Knoten)“. Hier ist ein Beispiel, um den Trainingsprozess auf 4 Knoten zu starten (jeder hat 8 GPUs):
# myhostfile
worker-1 slots=8
worker-2 slots=8
worker-3 slots=8
worker-4 slots=8
Starten Sie dann die Trainingsskripte mit:
bash scripts/sft.sh
--hostfile myhostfile
--model_name_or_path ~ /models/llama-7b
--output_dir output/sft safe-rlhf bietet eine Abstraktion zum Erstellen von Datensätzen für alle Phasen der überwachten Feinabstimmung, des Präferenzmodelltrainings und des RL-Trainings.
class RawSample ( TypedDict , total = False ):
"""Raw sample type.
For SupervisedDataset, should provide (input, answer) or (dialogue).
For PreferenceDataset, should provide (input, answer, other_answer, better).
For SafetyPreferenceDataset, should provide (input, answer, other_answer, safer, is_safe, is_other_safe).
For PromptOnlyDataset, should provide (input).
"""
# Texts
input : NotRequired [ str ] # either `input` or `dialogue` should be provided
"""User input text."""
answer : NotRequired [ str ]
"""Assistant answer text."""
other_answer : NotRequired [ str ]
"""Other assistant answer text via resampling."""
dialogue : NotRequired [ list [ str ]] # either `input` or `dialogue` should be provided
"""Dialogue history."""
# Flags
better : NotRequired [ bool ]
"""Whether ``answer`` is better than ``other_answer``."""
safer : NotRequired [ bool ]
"""Whether ``answer`` is safer than ``other_answer``."""
is_safe : NotRequired [ bool ]
"""Whether ``answer`` is safe."""
is_other_safe : NotRequired [ bool ]
"""Whether ``other_answer`` is safe."""Hier ist ein Beispiel für die Implementierung eines benutzerdefinierten Datensatzes (weitere Beispiele finden Sie unter safe_rlhf/datasets/raw):
import argparse
from datasets import load_dataset
from safe_rlhf . datasets import RawDataset , RawSample , parse_dataset
class MyRawDataset ( RawDataset ):
NAME = 'my-dataset-name'
def __init__ ( self , path = None ) -> None :
# Load a dataset from Hugging Face
self . data = load_dataset ( path or 'my-organization/my-dataset' )[ 'train' ]
def __getitem__ ( self , index : int ) -> RawSample :
data = self . data [ index ]
# Construct a `RawSample` dictionary from your custom dataset item
return RawSample (
input = data [ 'col1' ],
answer = data [ 'col2' ],
other_answer = data [ 'col3' ],
better = float ( data [ 'col4' ]) > float ( data [ 'col5' ]),
...
)
def __len__ ( self ) -> int :
return len ( self . data ) # dataset size
def parse_arguments ():
parser = argparse . ArgumentParser (...)
parser . add_argument (
'--datasets' ,
type = parse_dataset ,
nargs = '+' ,
metavar = 'DATASET[:PROPORTION[:PATH]]' ,
)
...
return parser . parse_args ()
def main ():
args = parse_arguments ()
...
if __name__ == '__main__' :
main ()Anschließend können Sie diesen Datensatz wie folgt an die Trainingsskripte übergeben:
python3 train.py --datasets my-dataset-name Sie können auch mehrere Datensätze mit optional zusätzlichen Datensatzanteilen übergeben (getrennt durch einen Doppelpunkt : ). Zum Beispiel:
python3 train.py --datasets alpaca:0.75 my-dataset-name:0.5Dabei werden 75 % des Stanford Alpaca-Datensatzes und 50 % Ihres benutzerdefinierten Datensatzes nach dem Zufallsprinzip aufgeteilt.
Darüber hinaus kann dem Datensatzargument auch ein lokaler Pfad folgen (getrennt durch einen Doppelpunkt : ), wenn Sie das Datensatz-Repository bereits von Hugging Face geklont haben.
git lfs install
git clone https://huggingface.co/datasets/my-organization/my-dataset ~ /path/to/my-dataset/repository
python3 train.py --datasets alpaca:0.75 my-dataset-name:0.5: ~ /path/to/my-dataset/repositoryHINWEIS: Die Datensatzklasse muss importiert werden, bevor das Trainingsskript mit der Analyse der Befehlszeilenargumente beginnt.
python3 -m safe_rlhf.serve.cli --model_name_or_path output/sft # or output/ppo-lagpython3 -m safe_rlhf.serve.arena --red_corner_model_name_or_path output/sft --blue_corner_model_name_or_path output/ppo-lag
Die Safe-RLHF-Pipeline unterstützt nicht nur die LLaMA-Modellfamilie, sondern auch andere vorab trainierte Modelle wie Baichuan, InternLM usw., die eine bessere Unterstützung für Chinesisch bieten. Sie müssen lediglich den Pfad zum vorab trainierten Modell im Trainings- und Inferenzcode aktualisieren.
Safe-RLHF 管道不仅仅支持 LLaMA 系列模型, 它也支持其他一些对中文支持更好的预训练模型, 例如 Baichuan和 InternLM 等.推理的代码中更新预训练模型的路径即可.
# SFT training
bash scripts/sft.sh --model_name_or_path baichuan-inc/Baichuan-7B --output_dir output/baichuan-sft
# Inference
python3 -m safe_rlhf.serve.cli --model_name_or_path output/baichuan-sft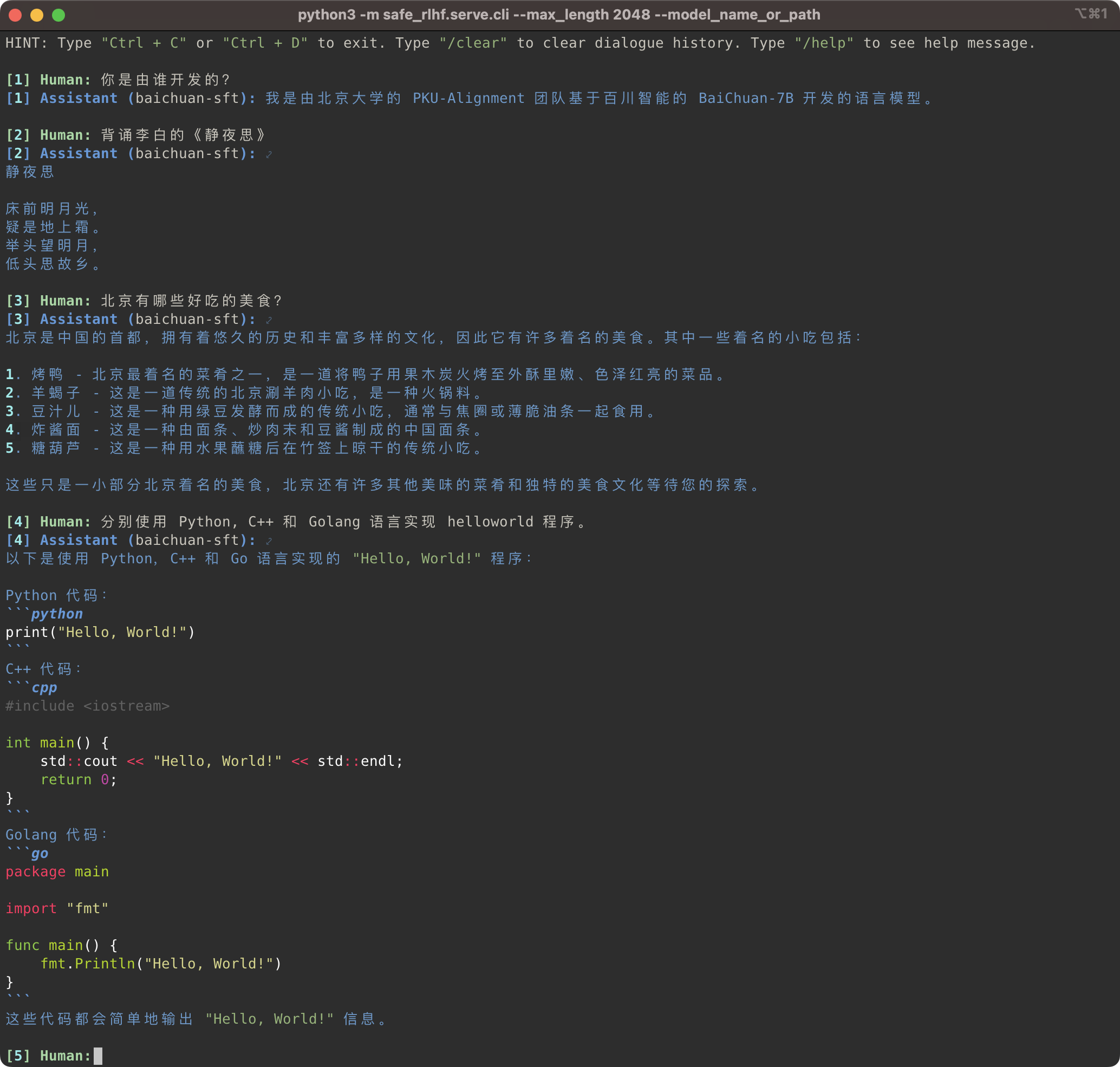
In der Zwischenzeit haben wir unseren Rohdatensätzen Unterstützung für chinesische Datensätze wie die Firefly- und MOSS-Serie hinzugefügt. Sie müssen lediglich den Datensatzpfad im Trainingscode ändern, um den entsprechenden Datensatz für die Feinabstimmung des chinesischen Vortrainingsmodells zu verwenden:
Es gibt auch Raw-Datasets, darunter Firefly und MOSS系列等.在训练代码中更改数据集路径
# scripts/sft.sh
- --train_datasets alpaca
+ --train_datasets firefly Anweisungen zum Hinzufügen benutzerdefinierter Datensätze finden Sie im Abschnitt Benutzerdefinierte Datensätze.
关于如何添加自定义数据集的方法,请参阅章节 Custom Datasets (自定义数据集)。
scripts/arena-evaluation.sh
--red_corner_model_name_or_path output/sft
--blue_corner_model_name_or_path output/ppo-lag
--reward_model_name_or_path output/rm
--cost_model_name_or_path output/cm
--output_dir output/arena-evaluation # Install BIG-bench
git clone https://github.com/google/BIG-bench.git
(
cd BIG-bench
python3 setup.py sdist
python3 -m pip install -e .
)
# BIG-bench evaluation
python3 -m safe_rlhf.evaluate.bigbench
--model_name_or_path output/ppo-lag
--task_name < BIG-bench-task-name > # Install OpenAI Python API
pip3 install openai
export OPENAI_API_KEY= " ... " # your OpenAI API key here
# GPT-4 evaluation
python3 -m safe_rlhf.evaluate.gpt4
--red_corner_model_name_or_path output/sft
--blue_corner_model_name_or_path output/ppo-lagWenn Sie Safe-RLHF nützlich finden oder Safe-RLHF (Modell, Code, Datensatz usw.) in Ihrer Forschung verwenden, denken Sie bitte darüber nach, die folgenden Arbeiten in Ihren Veröffentlichungen zu zitieren.
@inproceedings { safe-rlhf ,
title = { Safe RLHF: Safe Reinforcement Learning from Human Feedback } ,
author = { Josef Dai and Xuehai Pan and Ruiyang Sun and Jiaming Ji and Xinbo Xu and Mickel Liu and Yizhou Wang and Yaodong Yang } ,
booktitle = { The Twelfth International Conference on Learning Representations } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=TyFrPOKYXw }
}
@inproceedings { beavertails ,
title = { BeaverTails: Towards Improved Safety Alignment of {LLM} via a Human-Preference Dataset } ,
author = { Jiaming Ji and Mickel Liu and Juntao Dai and Xuehai Pan and Chi Zhang and Ce Bian and Boyuan Chen and Ruiyang Sun and Yizhou Wang and Yaodong Yang } ,
booktitle = { Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track } ,
year = { 2023 } ,
url = { https://openreview.net/forum?id=g0QovXbFw3 }
}Alle unten aufgeführten Studierenden haben gleichermaßen beigetragen und die Reihenfolge wird alphabetisch festgelegt:
Alle beraten von Yizhou Wang und Yaodong Yang. Danksagung: Wir danken Frau Yi Qu für die Gestaltung des Beaver-Logos.
Dieses Repository profitiert von LLaMA, Stanford Alpaca, DeepSpeed und DeepSpeed-Chat. Vielen Dank für ihre wunderbaren Arbeiten und ihre Bemühungen zur Demokratisierung der LLM-Forschung. Safe-RLHF und die damit verbundenen Vermögenswerte werden mit Liebe erstellt und als Open-Source-Lösung bereitgestellt ?❤️.
Diese Arbeit wird von der Peking-Universität unterstützt und finanziert.
 |  |
Safe-RLHF wird unter der Apache-Lizenz 2.0 veröffentlicht.


