spelltest
v0.0.4
? Wenn Sie dieses Projekt nützlich finden, denken Sie bitte darüber nach, ihm einen Stern zu geben! Ihre Unterstützung motiviert mich, es weiter zu verbessern! ?
Heutige KI-gesteuerte Anwendungen sind weitgehend auf Large Language Models (LLMs) wie GPT-4 angewiesen, um innovative Lösungen bereitzustellen. Es ist jedoch eine Herausforderung sicherzustellen, dass sie in jeder Situation relevante und genaue Antworten geben. Spelltest geht dieses Problem an, indem es LLM-Antworten mithilfe synthetischer Benutzerpersönlichkeiten und einer Bewertungstechnik simuliert, um diese Antworten automatisch auszuwerten (erfordert jedoch weiterhin eine menschliche Aufsicht).
spellforge.yaml : project_name : ...
# describe users
users :
...
# describe quality metrics
metrics :
...
# describe prompts of your LLM app
prompts :
...
# finally describe simulations
simulations :
...

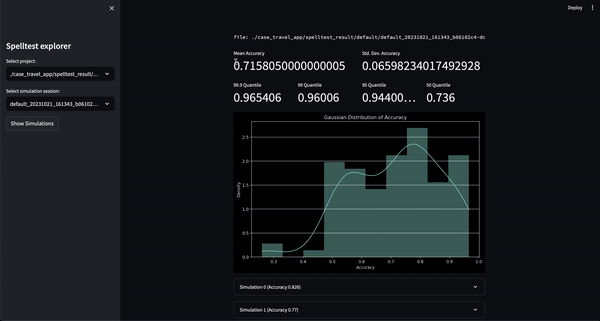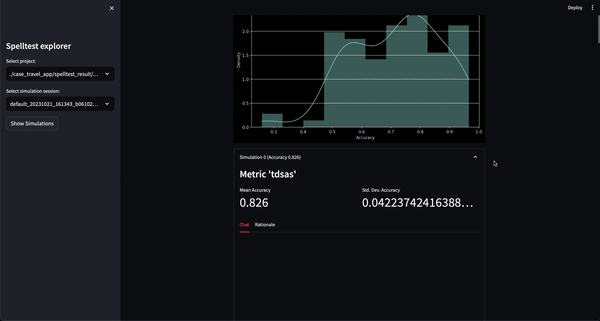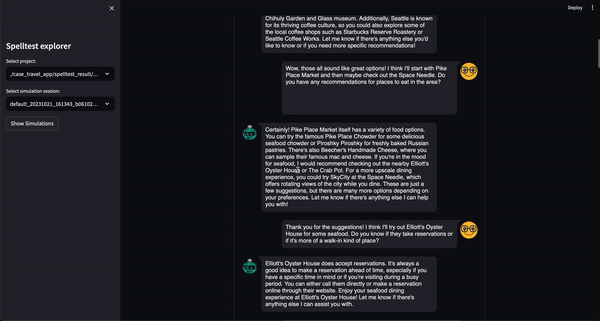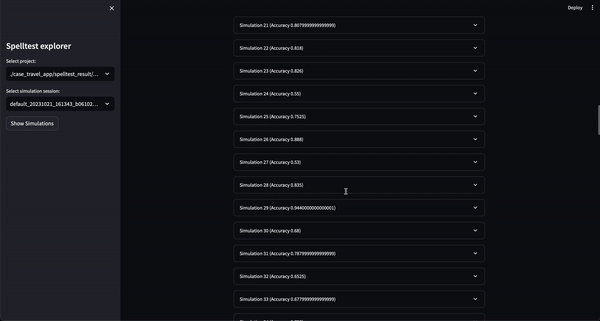
Sie können dieses Projekt jetzt in einer webbasierten interaktiven Umgebung über Google Colab ausprobieren! Es ist keine Installation erforderlich.
Klicken Sie einfach auf das Abzeichen oben, um loszulegen!
Gesicherte Qualität : Simulieren Sie Benutzerinteraktionen für optimale Antworten.
Effizienz und Einsparungen : Sparen Sie manuelle Testkosten.
Reibungslose Workflow-Integration : Passt sich nahtlos in Ihren Entwicklungsprozess ein.
Bitte beachten Sie, dass es sich hierbei um eine sehr frühe Version von Spelltest handelt. Daher wurde es noch nicht umfassend in verschiedenen Umgebungen und Anwendungsfällen getestet. Indem Sie sich für die Verwendung dieser Version entscheiden, akzeptieren Sie, dass Sie das Spelltest-Framework auf eigenes Risiko nutzen. Wir ermutigen Benutzer dringend, alle auftretenden Probleme oder Fehler zu melden, um zur Verbesserung des Projekts beizutragen.
Bezüglich der Betriebskosten ist zu beachten, dass für die Ausführung von Simulationen mit Spelltest Gebühren anfallen, die auf der Nutzung der OpenAI-API basieren. Derzeit gibt es keine Kostenschätzungen oder Budgetgrenzen. Zum Vergleich: Die Durchführung einer Charge von 100 Simulationen kann etwa 0,7 bis 1,8 US-Dollar (gpt-3,5-turbo) kosten, abhängig von mehreren Faktoren, einschließlich des spezifischen LLM und der Komplexität der Simulationen.
Angesichts dieser Kosten empfehlen wir dringend, mit einer geringeren Anzahl von Simulationen zu beginnen, um sowohl Ihre anfänglichen Kosten niedrig zu halten als auch Ihnen zu helfen, zukünftige Ausgaben besser einzuschätzen. Wenn Sie mit dem Framework und seinen Kostenauswirkungen vertrauter werden, können Sie die Anzahl der Simulationen an Ihr Budget und Ihre Bedürfnisse anpassen.
Denken Sie daran, dass das Ziel von Spelltest darin besteht, qualitativ hochwertige Antworten von LLMs sicherzustellen und gleichzeitig in Ihrem KI-Entwicklungs- und Testprozess so kosteneffektiv wie möglich zu bleiben.

Spelltest verfolgt einen besonderen Ansatz zur Qualitätssicherung. Durch den Einsatz synthetischer Benutzerpersönlichkeiten simulieren wir nicht nur Interaktionen, sondern erfassen auch einzigartige Benutzererwartungen und bieten so eine kontextreiche Umgebung zum Testen. Diese Kontexttiefe ermöglicht es uns, die Qualität von LLM-Antworten auf eine Weise zu bewerten, die den realen Anwendungen möglichst nahe kommt.
Das Ergebnis? Ein Qualitätsfaktor zwischen 0,0 und 1,0, der als umfassende Generalprobe dient, bevor Ihre App ihre echten Benutzer trifft. Ob im Chat- oder Vervollständigungsmodus – Spelltest stellt sicher, dass die LLM-Antworten eng mit den Erwartungen der Benutzer übereinstimmen und so die Gesamtzufriedenheit der Benutzer erhöht.
Installieren Sie das Framework mit pip:
pip install spelltest Die .spellforge.yaml ist von zentraler Bedeutung für Spelltest und enthält synthetische Benutzerprofile, Metriken, Eingabeaufforderungen und Simulationen. Nachfolgend finden Sie eine Aufschlüsselung seiner Struktur:
Synthetische Benutzer ahmen reale Benutzer nach, jeder mit einem einzigartigen Hintergrund, Erwartungen und Verständnis der App. Die Konfiguration für synthetische Benutzer umfasst:
Unteraufforderungen : Hierbei handelt es sich um beschreibende Elemente, die Kontext zum Benutzerprofil bereitstellen. Dazu gehören:
description : Eine kurze Beschreibung des synthetischen Benutzers.expectation : Was der Benutzer von der Interaktion erwartet.user_knowledge_about_app : Vertrautheitsgrad mit der App.Jeder synthetische Benutzer hat außerdem Folgendes:
name : Die Kennung für den synthetischen Benutzer.llm_name : Die zu verwendenden LLM-Modelle (nur auf OpenAI-Modellen getestet).temperature : ...Beispiel einer synthetischen Benutzerkonfiguration:
...
nomad :
name : " Busy Nomad in Seattle "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a very busy nomad who struggles with planning. You're moved to Seattle and looking at how to spend your first Saturday exploring the city "
expectation : " Well-planned objective, detailed, and comprehensive schedule that meets user's requirements "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
... Metriken werden verwendet, um die Antworten des LLM zu bewerten und zu bewerten. Jede Metrik enthält eine description der Untereingabeaufforderung, die Kontext zu dem liefert, was die Metrik bewertet.
Beispiel einer einfachen Metrikkonfiguration:
...
metrics :
accuracy :
description : " Accuracy "
...Beispiel einer komplexen/benutzerdefinierten Metrikkonfiguration:
...
metrics :
tpas :
description : " TPAS - The Travel Plan Accuracy Score. This metric measures the accuracy of the generated response by evaluating the inclusion of the expected output, well-scheduled travel plan and nothing else. The TPAS is a numerical value between 0 and 100, with 100 representing a perfect match to the expected output and 0 indicating non-accurate result. "
... Eingabeaufforderungen sind Fragen oder Aufgaben, die die App stellt. Diese werden in Simulationen verwendet, um die Fähigkeit des LLM zu testen, geeignete Antworten zu generieren. Jede Eingabeaufforderung wird mit einer description und dem eigentlichen prompt oder der eigentlichen Aufgabe definiert.
...
prompts :
book_flight :
file : book-flight-prompt.txt
... Simulationen geben das Testszenario vor. Zu den Schlüsselelementen gehören prompt , users , llm_name , temperature , size , chat_mode und quality_threshold .
project_name : " Travel schedule app "
# describe users
users :
nomad :
name : " Busy Nomad in Seattle "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a very busy nomad who struggles with planning. You're moved to Seattle and looking at how to spend your first Saturday exploring the city "
expectation : " Well-planned objective, detailed, and comprehensive schedule that meets user's requirements "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
family_weekend :
name : " The Adventurous Family from Chicago "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a family of four (two adults and two children) based in Chicago looking to plan an exciting, yet relaxed weekend getaway outside the city. The objective is to explore a new environment that is kid-friendly and offers a mix of adventure and downtime. "
expectation : " A balanced travel schedule that combines fun activities suitable for children and relaxation opportunities for the entire family, considering travel times and kid-friendly amenities. "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
retired_couple :
name : " Retired Couple Exploring Berlin "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a retired couple from the US, wanting to explore Berlin and soak in its rich history and culture over a 10-day vacation. You’re looking for a mixture of sightseeing, cultural experiences, and leisure activities, with a comfortable pace suitable for your age. "
expectation : " A comprehensive travel plan that provides a relaxed pace, ensuring enough time to explore and enjoy each location, and includes historical and cultural experiences. It should also consider comfort and accessibility. "
user_knowledge_about_app : " The app accepts text input detailing travel requirements (i.e., destination, preferences, duration, and a brief description of travelers) and returns a well-organized travel itinerary tailored to those specifics. "
metrics : __all__
# describe quality metrics
metrics :
tpas : # name of your metric
description : " TPAS - The Travel Plan Accuracy Score. This metric measures the accuracy of the generated response by evaluating the inclusion of the expected output, well-scheduled travel plan and nothing else. The TPAS is a numerical value between 0 and 100, with 100 representing a perfect match to the expected output and 0 indicating non-accurate result. "
# describe prompts
prompts :
smart-prompt :
file : ./smart-prompt # expected that prompt located in this file
# finally describe simulations
simulations :
test1 :
prompt : smart-prompt
users : __all__
llm_name : gpt-3.5-turbo
temperature : 0.7
size : 5
chat_mode : true # completion mode if `false`
quality_threshold : 80
Die vollständige Konfiguration mit Eingabeaufforderungsdateien finden Sie hier.
OpenAI-Kosten : Die Verwendung dieses Frameworks kann zu einer erheblichen Anzahl von Anfragen an OpenAI führen, insbesondere bei der Ausführung umfangreicher Simulationen. Dies kann zu erheblichen Kosten für Ihr OpenAI-Konto führen. Stellen Sie sicher, dass Sie Ihr OpenAI-Budget im Auge behalten und das Preismodell verstehen. Für eventuell anfallende Kosten trage ich keine Haftung.
Frühzeitige Veröffentlichung : Diese Version von Spelltest befindet sich in einem frühen Stadium und verfügt über keine Stabilitätsgarantien. Bitte verwenden Sie es mit Vorsicht und geben Sie gerne Feedback oder melden Sie Probleme.
export OPENAI_API_KEYS= < your api keys >
spelltest --config_file .spellforge.yamlÜberprüfen Sie die Ergebnisse der Simulation.
spelltest --analyzeDie Integration von Spelltest in Ihre Release-Pipeline verbessert Ihre Bereitstellungsstrategie durch die Integration konsistenter, automatisierter Tests. Dieser entscheidende Schritt stellt sicher, dass Ihre LLM-basierten Anwendungen einen hohen Qualitätsstandard beibehalten, indem Benutzerinteraktionen vor jeder Veröffentlichung systematisch simuliert und ausgewertet werden. Diese Vorgehensweise kann erheblich Zeit sparen, manuelle Fehler reduzieren und wichtige Erkenntnisse darüber liefern, wie sich Änderungen oder neue Funktionen auf die Benutzererfahrung auswirken.
Dieser Leitfaden führt Sie durch den Prozess der Einrichtung und Automatisierung der kontinuierlichen Integration für Ihre Projekte.
Bevor Sie beginnen, stellen Sie sicher, dass die folgenden Voraussetzungen erfüllt sind:
Ein GitHub-Repository, das Ihr Projekt enthält.
Zugriff auf SpellForge mit einem API-Schlüssel. Wenn Sie noch keins haben, können Sie es auf der SpellForge-Website herunterladen.
Ein OpenAI-API-Schlüssel zur Nutzung von OpenAI-Diensten. Wenn Sie noch keins haben, können Sie es von der OpenAI-Website herunterladen.
.spellforge.yaml Erstellen Sie eine .spellforge.yaml Datei im Stammverzeichnis Ihres Projekts. Diese Datei enthält die Anweisungen für Spelltest.
Erstellen Sie eine GitHub Actions-Workflow-Datei, z. B. .github/workflows/.spelltest.yaml, um SpellForge-Tests zu automatisieren. Fügen Sie den folgenden Code in diese Datei ein:
# .spelltest.yaml
name : Spelltest CI
on :
push :
branches : [ "main" ]
env :
SPELLTEST_CONFIG_PATH : ${{ env.SPELLTEST_CONFIG_PATH }}
OPENAI_API_KEY : ${{ secrets.OPENAI_API_KEY }}
jobs :
test :
runs-on : ubuntu-latest
steps :
- uses : actions/checkout@v3
- name : Install SpellTest library
run : pip install spelltest
- name : Run tests
run : spelltest --config_file $SPELLTEST_CONFIG_PATHDieser Workflow wird bei jedem Push zum Hauptzweig ausgelöst und führt Ihre SpellForge-Tests aus.
Gehen Sie zu Ihrem GitHub-Repository und navigieren Sie zur Registerkarte „Einstellungen“.
Fügen Sie unter „Geheimnisse“ zwei neue Geheimnisse hinzu:
OPENAI_API_KEY : Legen Sie dieses Geheimnis auf Ihren OpenAI-API-Schlüssel fest.
Fügen Sie eine GitHub-Umgebungsvariable hinzu:
SPELLTEST_CONFIG_PATH : Setzen Sie diese Variable auf den vollständigen Pfad zu Ihrer .spellforge.yaml-Datei in Ihrem Repository.
Dabei handelt es sich um die Simulation realer Benutzerinteraktionen mit spezifischen Merkmalen und Erwartungen.
Benutzerhintergrund ( description in .spellforge.yaml ): Eine Untereingabeaufforderung, die einen Überblick darüber bietet, wer dieser synthetische Benutzer ist und welche Probleme er mit der App lösen möchte, z. B. ein Reisender, der seinen Zeitplan verwaltet.
Benutzererwartung ( expectation ): Eine Untereingabeaufforderung, die definiert, was der synthetische Benutzer als erfolgreiche Interaktion oder Lösung von der Verwendung der App erwartet.
Umgebungsbewusstsein (Feld user_knowledge_about_app ): Eine Untereingabeaufforderung, die sicherstellt, dass der synthetische Benutzer den Kontext der Anwendung versteht und so realistische Testszenarien gewährleistet.
Eine Untereingabeaufforderung, die Standards oder Kriterien darstellt, die zur Bewertung und Bewertung der vom LLM in den Simulationen generierten Antworten verwendet werden. Die Metriken können von allgemeinen Messungen bis hin zu anwendungsspezifischen, benutzerdefinierten Metriken reichen.
Allgemeine Metrikbeispiele:
Semantische Ähnlichkeit : Misst, wie sehr die bereitgestellte Antwort hinsichtlich ihrer Bedeutung einer erwarteten Antwort ähnelt.
Toxizität : Bewertet die Reaktion auf jede Sprache oder jeden Inhalt, der als unangemessen oder schädlich angesehen werden könnte.
Strukturelle Ähnlichkeit : Vergleicht die Struktur und das Format der generierten Antwort mit einem vordefinierten Standard oder einer erwarteten Ausgabe.
Weitere Beispiele für benutzerdefinierte Metriken:
TPAS (Travel Plan Accuracy Score) : „Diese Metrik misst die Genauigkeit der generierten Antwort, indem sie die Einbeziehung der erwarteten Ergebnisse und die Qualität des vorgeschlagenen Reiseplans bewertet. TPAS ist ein numerischer Wert zwischen 0 und 100, wobei 100 ein perfektes Ergebnis darstellt.“ stimmt mit der erwarteten Ausgabe überein und 0 weist auf ein ungenaues Ergebnis hin.“
EES (Empathy Engagement Score) : „Der EES bewertet die empathische Resonanz der Antworten des LLM. Durch die Bewertung von Verständnis, Validierung und unterstützenden Elementen in der Nachricht bewertet er das vermittelte Empathieniveau. EES reicht von 0 bis 100, wobei 100 a angibt eine sehr einfühlsame Reaktion, während 0 einen Mangel an einfühlsamem Engagement bedeutet.“
Verbessern Sie Ihre LLM-basierte Anwendung mit Spelltest!


