paperchat
1.0.0
Willkommen bei arXivchat!
arXivchat ist eine LLM-basierte Software, mit der Sie im Gespräch über von arXiv veröffentlichte Artikel sprechen können. Es funktioniert als CLI-Tool, API-Anbieter und ChatGPT-Plugin.
Hergestellt von Forward Operators. Wir arbeiten mit einigen der klügsten Köpfe an LLM- und ML-bezogenen Projekten zusammen.
Sie sind herzlich willkommen, einen Beitrag zu leisten!
Befolgen Sie diese Schritte, um das arXiv-Plugin schnell einzurichten und auszuführen:
Installieren Sie Python 3.10, falls noch nicht installiert.
Klonen Sie das Repository: git clone https://github.com/Forward-Operators/arxivchat.git
Navigieren Sie zum geklonten Repository-Verzeichnis: cd /path/to/arxivchat
Poesie installieren: pip install poetry
Erstellen Sie eine neue virtuelle Umgebung mit Python 3.10: poetry env use python3.10
Aktivieren Sie die virtuelle Umgebung: poetry shell
App-Abhängigkeiten installieren: poetry install
Legen Sie die erforderlichen Umgebungsvariablen fest:
export DATABASE= < your_datastore >
export OPENAI_API_KEY= < your_openai_api_key >
# Add the environment variables for your chosen vector DB.
# Pinecone
export PINECONE_API_KEY= < your_pinecone_api_key >
export PINECONE_ENVIRONMENT= < your_pinecone_environment >
export PINECONE_INDEX= < your_pinecone_index >
# Qdrant
export QDRANT_URL= < your_qdrant_url >
export QDRANT_PORT= < your_qdrant_port >
export QDRANT_GRPC_PORT= < your_qdrant_grpc_port >
export QDRANT_API_KEY= < your_qdrant_api_key >
export QDRANT_COLLECTION= < your_qdrant_collection >
# Chroma
export CHROMA_HOST= < your_chroma_host >
export CHROMA_PORT= < your_chroma_port >
export CHROMA_COLLECTION= < your_chroma_collection >
# Embeddings
export EMBEDDINGS= < openai or huggingface >
export CUDA_ENABLED= < True or False > - needed for huggingface
Führen Sie die API lokal aus: cd app/; gunicorn --worker-class uvicorn.workers.UvicornWorker --config ./gunicorn_conf.py main:app
Greifen Sie auf die API-Dokumentation unter http://0.0.0.0:8000/docs zu und testen Sie die API-Endpunkte.
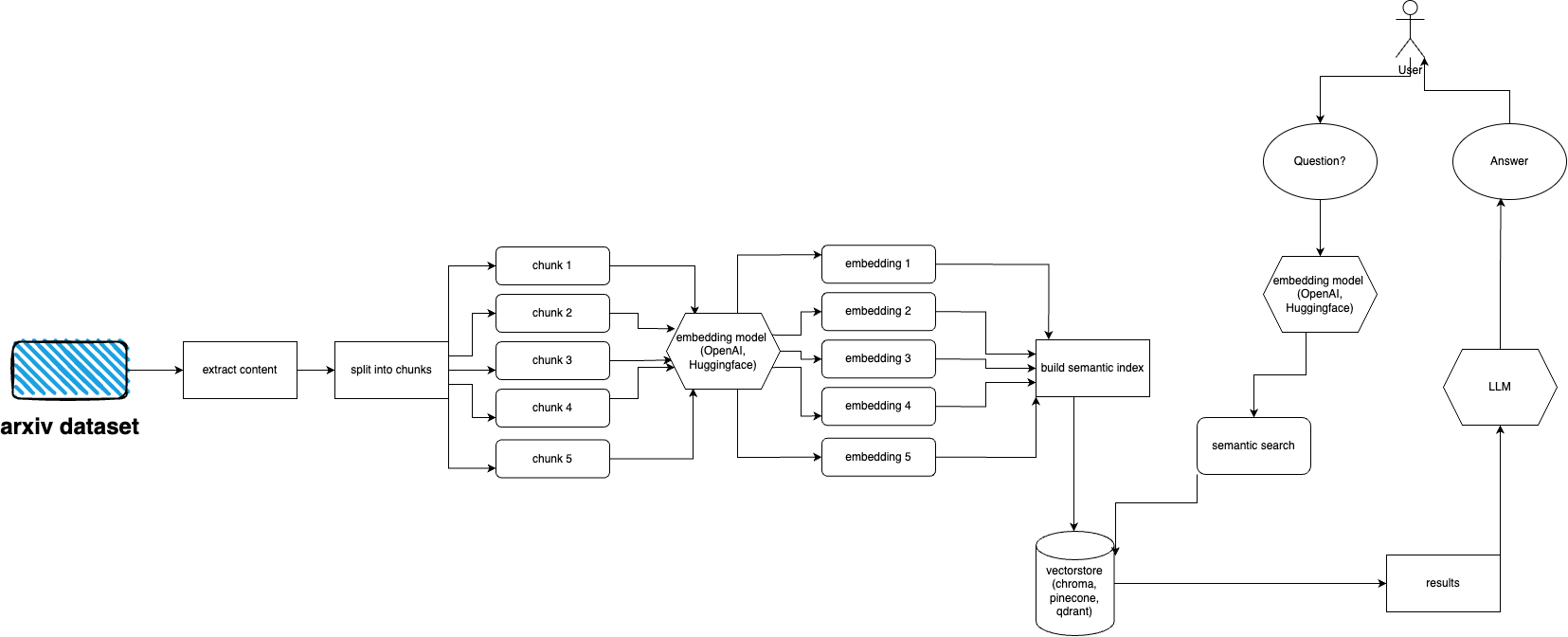
arXiv verfügt über einen Datensatz von fast 2 Millionen Publikationen. Es verstößt gegen die Nutzungsbedingungen von arXiv, zu viele Daten von ihrer Website abzurufen (da dies zu Last führt). Glücklicherweise erstellen gute Leute von Kaggle zusammen mit der Cornell University einen öffentlich zugänglichen Datensatz, den Sie verwenden können. Der Datensatz ist über Google Cloud Storage-Buckets frei verfügbar und wird wöchentlich aktualisiert.
Die Hauptfrage lautet nun: Wie erhält man nur eine Teilmenge des gesamten Datensatzes, wenn man nicht mehr als 5 Terabyte an PDF-Dateien aufnehmen möchte? Der Datensatz ist in Verzeichnisse pro Monat und Jahr unterteilt. Wenn Sie also alle Veröffentlichungen ab September 2021 erhalten möchten, können Sie einfach Folgendes ausführen: gsutil cp -r gs://arxiv-dataset/arxiv/pdf/2109/ ./local_directory
Wenn Sie einen gesamten Datensatz erhalten möchten: gsutil cp -r gs://arxiv-dataset/arxiv/pdf/ ./a_local_directory/
Wenn Sie jedoch nur eine Teilmenge (für eine bestimmte Kategorie und ein bestimmtes Datum) erhalten möchten, werfen Sie einen Blick in die Datei download.py .
Standardmäßig erwartet Ingester, dass sich diese Dateien unter /mnt/dataset/arxiv/pdf befinden und alle PDF-Dateien dort sind.
Schauen Sie sich python scripy.py an und führen Sie es aus, um Daten aufzunehmen. Sie können dort auch das Debuggen aktivieren, wenn etwas nicht funktioniert.
TODO: Ändern Sie dies möglicherweise in den Directory Loader. TODO: Implementieren Sie die Sellerie-Bereitstellung und verwenden Sie den Worker für die Aufnahme
python cli.py 
Stellen Sie die Frage zu dem Thema, das Sie zuvor in die Datenbank eingegeben haben. Gibt auch Informationen zu Quellen zurück und läuft kontinuierlich. Eine weitere Option ist die Verwendung der REST-API (führen Sie uvicorn main:app --reload --host 0.0.0.0 --port 8000 aus dem app -Verzeichnis aus) oder die Verwendung als ChatGPT-Plugin (nach der Bereitstellung).
Im deployment befinden sich Terraform-Dateien. Verwenden Sie eines, das am besten zu Ihnen passt. In jeder Datei befindet sich eine README-Datei mit Anweisungen. Sie können auch einfach ein Docker-Image erstellen und es ausführen, wo immer Sie möchten. Die Bilddatei ist allerdings ziemlich groß.
Derzeit kann es als Cloud Run mithilfe eines Docker-Images bereitgestellt werden, es handelt sich also nur um eine API-Bereitstellung. Die Datenaufnahme muss auf einem anderen Computer ausgeführt werden (ich empfehle GPU-fähige Compute Engines, insbesondere wenn Sie Hugging Face-Einbettungen verwenden möchten und weil Sie Daten aus Google Storage direkt mit gcsfuse bereitstellen können). Mögliche Lösung für die Verwendung des GCS-Buckets mit der Cloud Laufen
Derzeit kann es als Container-Apps bereitgestellt werden (nur API-Bereitstellung, Sie benötigen eine weitere Bereitstellung für Ingester).
AWS wird noch nicht unterstützt. Kommt bald.
arxivchat verwendet standardmäßig text-embedding-ada-002 für OpenAI, Sie können dies in app/tools/factory.py ändern
Im Moment können Sie jedes Modell verwenden, das mit sentence_transformers funktioniert. Sie können das Modell in app/tools/factory.py ändern
Wenn Sie Probleme haben, nutzen Sie bitte GitHub Issues, um diese zu melden.
Wir würden uns über Ihre Hilfe freuen, arXivchat noch besser zu machen! Um einen Beitrag zu leisten, folgen Sie bitte diesen Schritten:
arXivchat wird unter der MIT-Lizenz veröffentlicht.


