reddit gpt summarizer
1.0.0
Auf LiteLLM für OpenAI-kompatiblen Connector aktualisiert, erleichtert das Hinzufügen von Unterstützung für eine Vielzahl von Modellen. Jetzt verwenden wir eine JSON-Datei für ein einzelnes Modell für unsere Konfiguration. Stellen Sie sicher, dass Sie über die entsprechenden API-Schlüssel verfügen, um Google Gemini AI Studio verwenden zu können. GPT 4o, Sonnet 3.5-Unterstützung.
Unterstützung für neue Claude-Modelle, einige Optimierungen.
Python wurde auf 3.11 aktualisiert. Wir haben außerdem Unterstützung für GPT-4 128k und Claude 2.1 + Claude Instant v1.2 hinzugefügt. Stellen Sie sicher, dass Sie Ihre Abhängigkeiten entsprechend aktualisieren.
Siehe: Anthropisch/Claude 2
Außerdem wurden einige Abhängigkeiten aktualisiert (Anthropic, OpenAI, PRAW, Streamlit)
Videoübersicht der Updates @YouTube
Neuer Artikel @ Better Programming/Medium: Reddit-Zusammenfassung mit Claude 100k und GPT 16k transformieren
Erweitern Sie die Einstellungen, um anthropische Modelle zu verwenden. Außerdem wurde Unterstützung für ältere OpenAI-Instruktionsmodelle hinzugefügt – die meisten produzieren Müllausgaben, sind aber nützlich zum Testen. Allerdings produziert Text Davinci 003 subjektiv einige der Ausgaben mit der höchsten Qualität. Die neuen 100.000-Modelle können oft ganze Reddit-Threads ohne Rekursion konsumieren.
Vergessen Sie nicht, Ihren Anthropic-API-Schlüssel zu Ihrer .env-Datei hinzuzufügen. (ANTHROPIC_API_KEY)
https://www.anthropic.com/index/100k-context-windows
Wenn Sie Zugriff auf die API haben, können Sie noch heute die längeren Kontextfenster nutzen. Siehe Dokumente. https://platform.openai.com/docs/models/gpt-4 Melden Sie sich hier für die Warteliste an: https://openai.com/waitlist/gpt-4
Artikel @ Better Programming/Medium Erstellen eines Reddit-Thread-Zusammenfassungstools mit der ChatGPT-API
Dies ist ein Python-basierter Reddit-Thread-Zusammenfassungstool, der GPT-3 verwendet, um Zusammenfassungen der Thread-Kommentare zu erstellen.
Dieses Skript wird verwendet, um Zusammenfassungen von Reddit-Threads zu generieren, indem die OpenAI-API verwendet wird, um Textblöcke basierend auf einer Eingabeaufforderung mit rekursiver Zusammenfassung zu vervollständigen. Zunächst stellt man eine Anfrage an einen bestimmten Reddit-Thread, extrahiert den Titel und den Eigentext und findet dann alle Kommentare im Thread.
Diese Kommentare werden dann in Gruppen mit einer bestimmten Anzahl von Tokens verkettet und für jede Gruppe wird eine Zusammenfassung generiert, indem die OpenAI-API mit dem Text der Gruppe sowie dem Titel und Selbsttext des Reddit-Threads aufgefordert wird. Die Zusammenfassungen werden dann in einer Datei in einem outputs im aktuellen Arbeitsverzeichnis gespeichert.
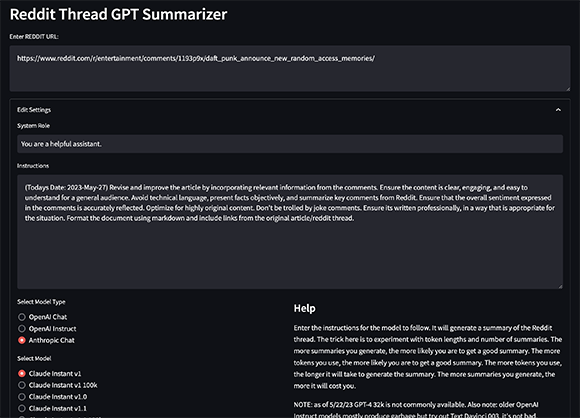
Um die Abhängigkeiten zu installieren, können Sie poetry verwenden:
poetry install Sie müssen außerdem OpenAI-/Reddit-/Anthropic-API-Anmeldeinformationen angeben. Erstellen Sie eine .env Datei und fügen Sie Folgendes hinzu:
OPENAI_ORG_ID = YOUR_ORG_ID
OPENAI_API_KEY = YOUR_API_KEY
REDDIT_CLIENT_ID = YOUR_CLIENT_ID
REDDIT_CLIENT_SECRET = YOUR_CLIENT_SECRET
REDDIT_USERNAME = YOUR_USERNAME
REDDIT_PASSWORD = YOUR_PASSWORD
REDDIT_USER_AGENT = linux:com.youragent.reddit-gpt-summarizer:v1.0.0 (by /u/yourusername)
ANTHROPIC_API_KEY = YOUR_ANTHROPIC_KEY Führen Sie Folgendes aus, um Entwicklungsabhängigkeiten zu installieren:
poetry install --extras dev
Dieses Projekt verwendet Pytest zum Testen und Mypy zur Typprüfung.
Verwenden Sie zum Ausführen von Tests und Typprüfungen die folgenden Befehle:
poetry run pytest
poetry run mypy .
Dieses Projekt verwendet außerdem Schwarz zur Codeformatierung und Pylint zum Linting.
Verwenden Sie die folgenden Befehle, um Code zu formatieren und auf Linting-Fehler zu prüfen:
poetry run black .
poetry run pylint .
Um die App auszuführen, verwenden Sie den folgenden Befehl:
streamlit run app/main.pyDadurch wird eine Web-App gestartet, mit der Sie eine Reddit-Thread-URL eingeben und eine Zusammenfassung erstellen können. Die App generiert automatisch Eingabeaufforderungen für GPT-3 basierend auf dem Inhalt des Threads und erstellt eine Zusammenfassung basierend auf diesen Eingabeaufforderungen.
Sie können das Verhalten der App mithilfe der Datei config.py anpassen. Folgende Konfigurationsmöglichkeiten stehen zur Verfügung:
ATTACH_DEBUGGER : Ob ein Debugger an die App angehängt werden soll.WAIT_FOR_CLIENT : Gibt an, ob vor dem Starten der App auf die Verbindung eines Clients gewartet werden soll.DEFAULT_DEBUG_PORT : Der Standardport, der für den Debugger verwendet wird.DEBUGPY_HOST : Der Host, der für den Debugger verwendet werden soll.DEFAULT_CHUNK_TOKEN_LENGTH : Die Standardlänge eines Kommentarblocks.DEFAULT_NUMBER_OF_SUMMARIES : Die Standardanzahl der zu generierenden Zusammenfassungen.DEFAULT_MAX_TOKEN_LENGTH : Die standardmäßige maximale Länge einer Zusammenfassung.LOG_FILE_PATH : Der Pfad zur Protokolldatei.LOG_COLORS : Ein Wörterbuch mit Farben für das Protokoll.REDDIT_URL : Die URL des zusammenzufassenden Reddit-Threads.TODAYS_DATE : Das heutige Datum.LOG_NAME : Der Name der Protokolldatei.APP_TITLE : Der Titel der App.MAX_BODY_TOKEN_SIZE : Die maximale Anzahl von Tokens für einen Kommentartext.DEFAULT_QUERY_TEXT : Der Standardtext, der für die GPT-3-Eingabeaufforderung verwendet wird.HELP_TEXT : Der Text, der angezeigt wird, wenn der Benutzer mit der Maus über das Hilfesymbol fährt. Wenn Sie zu diesem Projekt beitragen möchten, erstellen Sie bitte eine Pull-Anfrage.
Dieses Projekt ist unter der MIT-Lizenz lizenziert.


