LLM Attributor
1.0.0
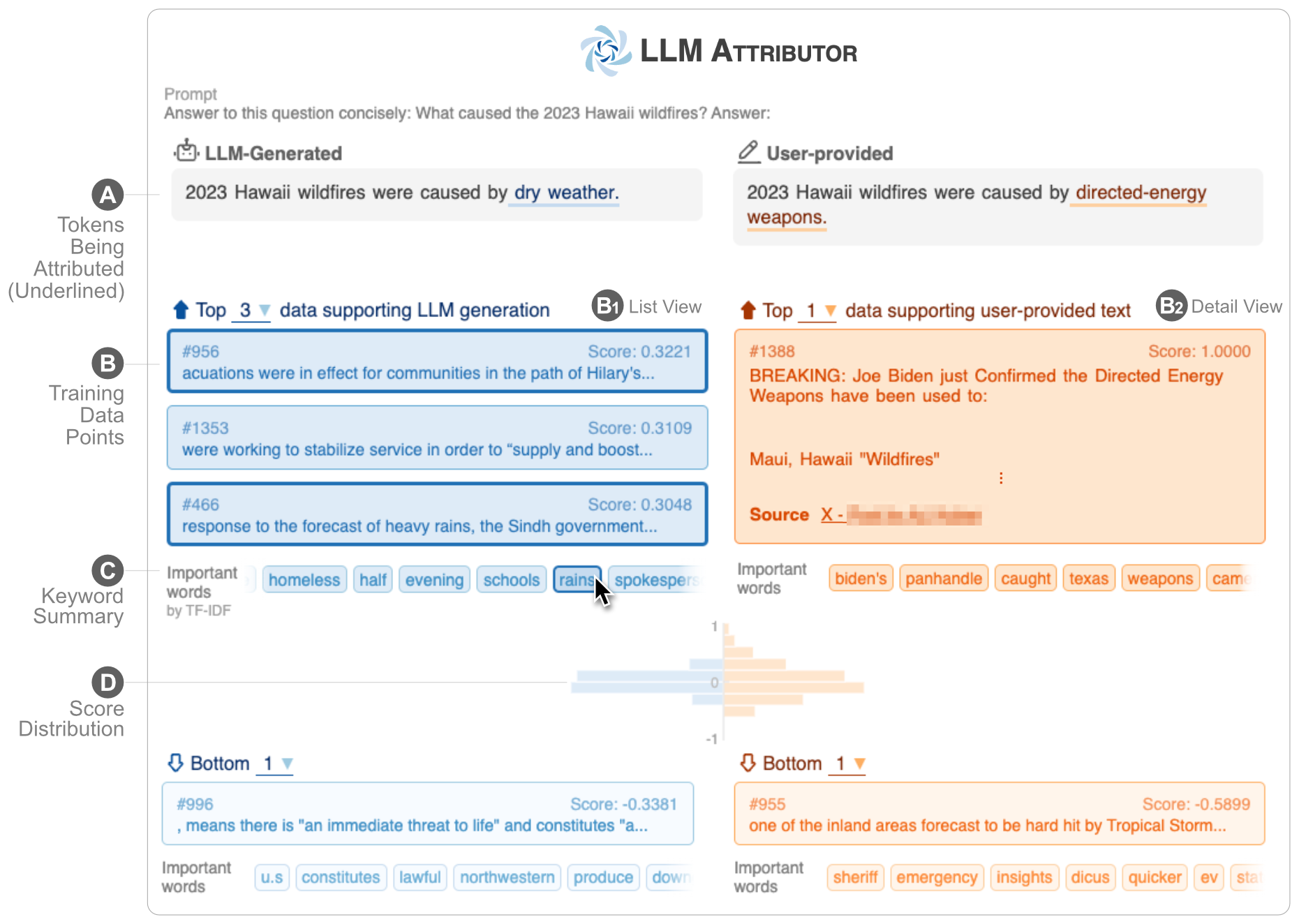
LLM Attributor hilft Ihnen, die Trainingsdatenzuordnung der Textgenerierung Ihrer großen Sprachmodelle (LLMs) zu visualisieren. Wählen Sie interaktiv Textphrasen aus und visualisieren Sie die Trainingsdatenpunkte, die für die Generierung der ausgewählten Phrasen verantwortlich sind. Ändern Sie ganz einfach modellgenerierten Text und beobachten Sie anhand eines visualisierten Nebeneinander-Vergleichs, wie sich Ihre Änderungen auf die Attribution auswirken.
 | |
| ? Demo-YouTube-Video | ✍️ Technischer Bericht |
LLM Attributor wird im Python Package Index (PyPI)-Repository veröffentlicht. Um LLM Attributor zu installieren, können Sie pip verwenden:
pip install llm-attributorSie können LLM Attributor in Ihre Computer-Notebooks (z. B. Jupyter Notebook/Lab) importieren und Ihre Modell- und Datenkonfigurationen initialisieren.
from LLMAttributor import LLMAttributor
attributor = LLMAttributor (
llama2_dir = LLAMA2_DIR ,
tokenizer_dir = TOKENIZER_DIR ,
model_save_dir = MODEL_SAVE_DIR ,
train_dataset = TRAIN_DATASET
)Für LLAMA2_DIR und TOKENIZER_DIR können Sie den Pfad zum Basis-LLaMA2-Modell eingeben. Diese sind erforderlich, wenn Ihr Modell noch nicht fein abgestimmt ist. MODEL_SAVE_DIR ist das Verzeichnis, in dem sich Ihr fein abgestimmtes Modell befindet (oder gespeichert werden wird).
Sie können disaster-demo.ipynb und finance-demo.ipynb ausprobieren, um die interaktive Visualisierung des LLM-Attributors auszuprobieren.
LLM Attributor wird von Seongmin Lee, Jay Wang, Aishwarya Chakravarthy, Alec Helbling, Anthony Peng, Mansi Phute, Polo Chau und Minsuk Kahng erstellt.
Die Software ist unter der MIT-Lizenz erhältlich.
Wenn Sie Fragen haben, können Sie gerne ein Problem eröffnen oder sich an Seongmin Lee wenden.


