latent diffusion segmentation
1.0.0
Dieses Repo enthält die Pytorch-Implementierung von LDMSeg: einen einfachen latenten Diffusionsansatz für panoptische Segmentierung und Masken-Inpainting. Der bereitgestellte Code umfasst sowohl das Training als auch die Evaluierung.
Ein einfacher latenter Diffusionsansatz für panoptische Segmentierung und Masken-Inpainting
Wouter Van Gansbeke und Bert De Brabandere
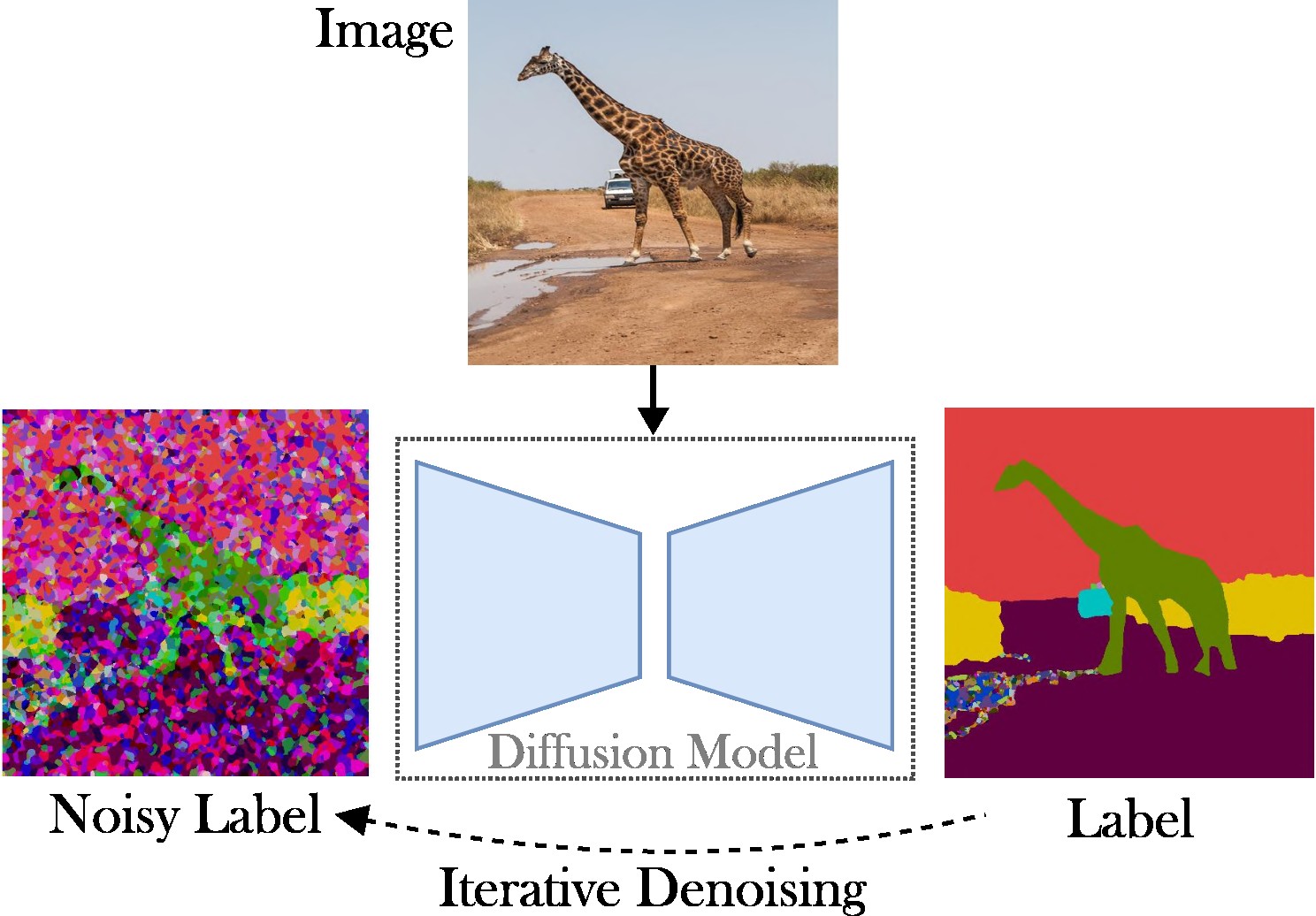
In diesem Artikel wird ein Ansatz zur bedingten latenten Diffusion vorgestellt, um die Aufgabe der panoptischen Segmentierung zu bewältigen. Ziel ist es, den Bedarf an speziellen Architekturen (z. B. Region-Proposal-Networks oder Objektabfragen), komplexen Verlustfunktionen (z. B. ungarisches Matching oder basierend auf Bounding Boxes) und zusätzlichen Nachbearbeitungsmethoden (z. B. Clustering, NMS) zu eliminieren oder Einfügen von Objekten). Aus diesem Grund verlassen wir uns auf Stable Diffusion, ein aufgabenunabhängiges Framework. Der vorgestellte Ansatz besteht aus zwei Schritten: (1) Projizieren der panoptischen Segmentierungsmasken auf einen latenten Raum mit einem flachen Autoencoder; (2) Trainieren Sie ein Diffusionsmodell im latenten Raum, bedingt durch RGB-Bilder.
Hauptbeiträge : Unsere Beiträge sind dreifach:
Der Code läuft mit aktuellen Pytorch-Versionen, z. B. 2.0. Darüber hinaus können Sie mit Anaconda eine Python-Umgebung erstellen:
conda create -n LDMSeg python=3.11
conda activate LDMSeg
Wir empfehlen, die automatische Installation zu befolgen (siehe tools/scripts/install_env.sh ). Führen Sie die folgenden Befehle aus, um das Projekt im bearbeitbaren Modus zu installieren. Beachten Sie, dass alle Abhängigkeiten automatisch installiert werden. Da dies möglicherweise nicht immer funktioniert (z. B. aufgrund von CUDA- oder GCC-Problemen), schauen Sie sich bitte die manuellen Installationsschritte an.
python -m pip install -e .
pip install git+https://github.com/facebookresearch/detectron2.git
pip install git+https://github.com/cocodataset/panopticapi.gitDie wichtigsten Pakete können mit pip schnell installiert werden als:
pip install torch torchvision einops # Main framework
pip install diffusers transformers xformers accelerate timm # For using pretrained models
pip install scipy opencv-python # For augmentations or loss
pip install pyyaml easydict hydra-core # For using config files
pip install termcolor wandb # For printing and logging Eine Kopie meiner Umgebung finden Sie unter data/environment.yml . Wir verlassen uns auch auf einige Abhängigkeiten von Detectron2 und Panopticapi. Bitte befolgen Sie deren Dokumente.
Wir unterstützen derzeit den COCO-Datensatz. Bitte befolgen Sie die Dokumentation zur Installation der Bilder und der entsprechenden panoptischen Segmentierungsmasken. Schauen Sie sich auch das Verzeichnis ldmseg/data/ an, um einige Beispiele für den COCO-Datensatz zu finden. Nebenbei bemerkt sollte die übernommene Struktur ziemlich standardisiert sein:
.
└── coco
├── annotations
├── panoptic_semseg_train2017
├── panoptic_semseg_val2017
├── panoptic_train2017 -> annotations/panoptic_train2017
├── panoptic_val2017 -> annotations/panoptic_val2017
├── test2017
├── train2017
└── val2017
Zu guter Letzt ändern Sie die Pfade in configs/env/root_paths.yml in Ihr Dataset-Stammverzeichnis bzw. Ihr gewünschtes Ausgabeverzeichnis.
Der vorgestellte Ansatz ist zweigleisig: Zuerst trainieren wir einen Auto-Encoder, um Segmentierungskarten in einem niedrigerdimensionalen Raum (z. B. 64x64) darzustellen. Als nächstes beginnen wir mit vorab trainierten Latent Diffusion Models (LDM), insbesondere Stable Diffusion, um ein Modell zu trainieren, das panoptische Masken aus RGB-Bildern generieren kann. Die Modelle können trainiert werden, indem die folgenden Befehle ausgeführt werden. Standardmäßig trainieren wir auf dem COCO-Datensatz mit der Basiskonfigurationsdatei, die in tools/configs/base/base.yaml definiert ist. Beachten Sie, dass diese Datei automatisch geladen wird, da wir auf das hydra -Paket angewiesen sind.
python - W ignore tools / main_ae . py
datasets = coco
base . train_kwargs . fp16 = True
base . optimizer_name = adamw
base . optimizer_kwargs . lr = 1e-4
base . optimizer_kwargs . weight_decay = 0.05 Weitere Details zur Übergabe von Argumenten finden Sie in tools/scripts/train_ae.sh . Ich führe dieses Modell beispielsweise für 50.000 Iterationen auf einer einzelnen GPU mit 23 GB und einer Gesamtstapelgröße von 16 aus.
python - W ignore tools / main_ldm . py
datasets = coco
base . train_kwargs . gradient_checkpointing = True
base . train_kwargs . fp16 = True
base . train_kwargs . weight_dtype = float16
base . optimizer_zero_redundancy = True
base . optimizer_name = adamw
base . optimizer_kwargs . lr = 1e-4
base . optimizer_kwargs . weight_decay = 0.05
base . scheduler_kwargs . weight = 'max_clamp_snr'
base . vae_model_kwargs . pretrained_path = '$AE_MODEL' $AE_MODEL bezeichnet den Pfad zum Modell, das im vorherigen Schritt erhalten wurde. Weitere Details zur Übergabe von Argumenten finden Sie in tools/scripts/train_diffusion.sh . Ich habe dieses Modell beispielsweise für 200.000 Iterationen auf 8 GPUs mit 16 GB und einer Gesamtstapelgröße von 256 ausgeführt.
Wir planen die Veröffentlichung mehrerer trainierter Modelle. Die (klassenunabhängige) PQ-Metrik wird im COCO-Validierungssatz bereitgestellt.
| Modell | #Params | Datensatz | Iter | PQ | Quadrat | RQ | Download-Link |
|---|---|---|---|---|---|---|---|
| AE | ~2M | COCO | 66k | - | - | - | Herunterladen (23 MB) |
| LDM | ~800M | COCO | 200.000 | 51.7 | 82,0 | 63,0 | Herunterladen (3,3 GB) |
Hinweis: Eine weniger leistungsstarke AE (d. h. weniger Downsampling- oder Upsampling-Ebenen) kann beim Inpainting oft von Vorteil sein, da wir keine zusätzliche Feinabstimmung durchführen.
Die Auswertung sollte wie folgt aussehen:
python - W ignore tools / main_ldm . py
datasets = coco
base . sampling_kwargs . num_inference_steps = 50
base . eval_only = True
base . load_path = $ PRETRAINED_MODEL_PATH Bei Bedarf können Sie Parameter hinzufügen. Höhere Schwellenwerte wie --base.eval_kwargs.count_th 700 oder --base.eval_kwargs.mask_th 0.9 können die Zahlen weiter steigern. Wir verwenden jedoch Standardwerte, indem wir einen Schwellenwert von 0,5 festlegen und Segmente mit einer Fläche kleiner als 512 für die Auswertung entfernen.
Um ein vorab trainiertes Modell von oben auszuwerten, führen Sie tools/scripts/eval.sh aus.
Hier visualisieren wir die Ergebnisse:

Wenn Sie dieses Repository für Ihre Forschung nützlich finden, ziehen Sie bitte die Zitierung des folgenden Artikels in Betracht:
@article { vangansbeke2024ldmseg ,
title = { a simple latent diffusion approach for panoptic segmentation and mask inpainting } ,
author = { Van Gansbeke, Wouter and De Brabandere, Bert } ,
journal = { arxiv preprint arxiv:2401.10227 } ,
year = { 2024 }
}Bei Rückfragen wenden Sie sich bitte an den Hauptautor.
Diese Software wird unter einer Creative-Commons-Lizenz veröffentlicht, die nur den persönlichen und wissenschaftlichen Gebrauch gestattet. Für eine kommerzielle Lizenz wenden Sie sich bitte an die Autoren. Eine Lizenzübersicht können Sie hier einsehen.
Ich bin dankbar für alle öffentlichen Repositories (siehe auch Referenzen im Code) und insbesondere für die Detectron2- und Diffusers-Bibliotheken.


