robust concept erasing
1.0.0
Koushik Srivatsan Fahad Shamshad Muzammal Naseer Karthik Nandakumar
Mohamed bin Zayed University of Artificial Intelligence (MBZUAI), Vereinigte Arabische Emirate .

Die rasche Verbreitung groß angelegter Modelle zur Text-zu-Bild-Generierung (T2IG) hat zu Bedenken hinsichtlich ihres möglichen Missbrauchs bei der Generierung schädlicher Inhalte geführt. Obwohl viele Methoden zum Löschen unerwünschter Konzepte aus T2IG-Modellen vorgeschlagen wurden, vermitteln sie nur ein falsches Sicherheitsgefühl, da neuere Arbeiten zeigen, dass konzeptgelöschte Modelle (CEMs) leicht dazu verleitet werden können, das gelöschte Konzept durch gegnerische Angriffe zu generieren. Das Problem der Löschung robuster Konzepte durch den Gegner ohne wesentliche Verschlechterung des Modellnutzens (Fähigkeit, harmlose Konzepte zu generieren) bleibt eine ungelöste Herausforderung, insbesondere in der White-Box-Umgebung, in der der Gegner Zugriff auf das CEM hat. Um diese Lücke zu schließen, schlagen wir einen Ansatz namens STEREO vor, der zwei unterschiedliche Phasen umfasst. Die erste Stufe sucht gründlich genug ( STE ) nach starken und vielfältigen gegnerischen Eingabeaufforderungen, die ein gelöschtes Konzept aus einem CEM wiederherstellen können, indem robuste Optimierungsprinzipien aus dem gegnerischen Training genutzt werden. In der zweiten Robustly Erase O nce ( REO )-Phase führen wir ein auf einem Ankerkonzept basierendes Kompositionsziel ein, um das Zielkonzept auf einmal robust zu löschen und gleichzeitig zu versuchen, die Verschlechterung des Modellnutzens zu minimieren. Indem wir den vorgeschlagenen STEREO- Ansatz mit vier hochmodernen Konzeptlöschmethoden unter drei gegnerischen Angriffen vergleichen, demonstrieren wir seine Fähigkeit, einen besseren Kompromiss zwischen Robustheit und Nutzen zu erzielen.
Groß angelegte Diffusionsmodelle für die Text-zu-Bild-Generierung sind anfällig für gegnerische Angriffe, die trotz Löschbemühungen schädliche Konzepte neu generieren können. Wir stellen STEREO vor, einen robusten Ansatz, der diese Regeneration verhindern und gleichzeitig die Fähigkeit des Modells zur Generierung harmloser Inhalte bewahren soll.
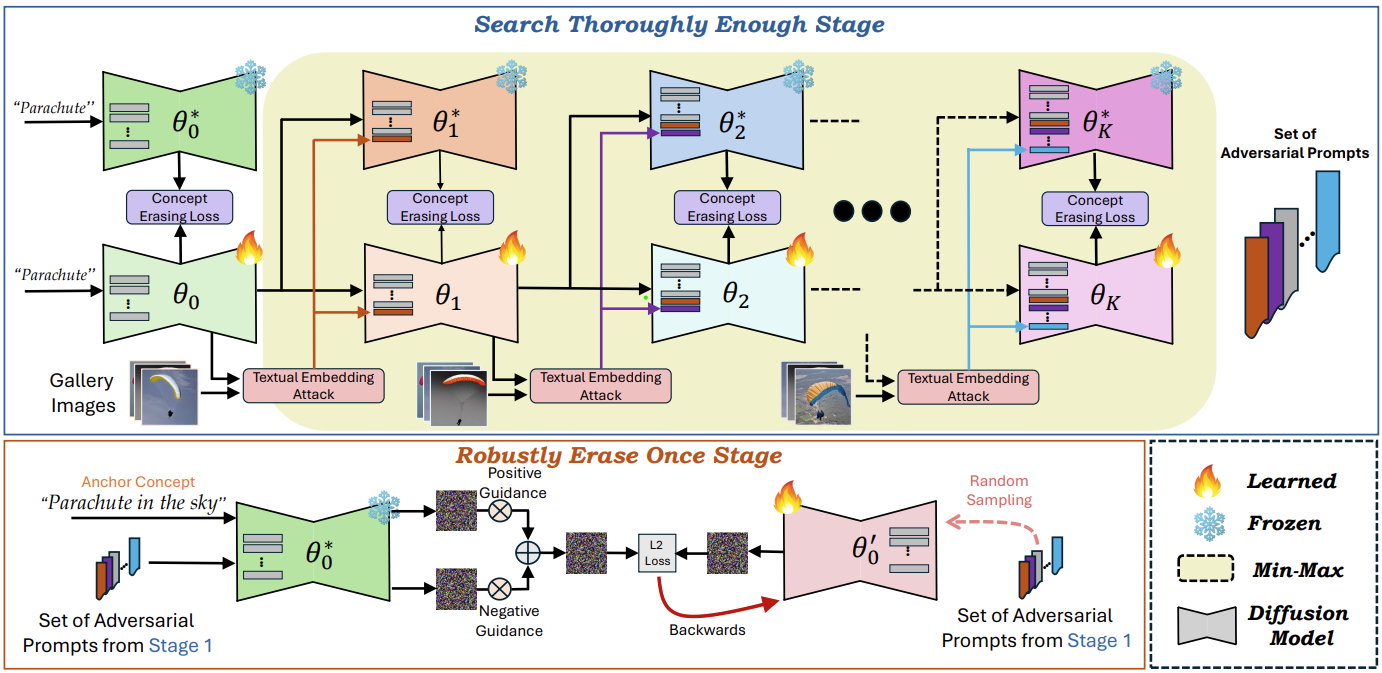
Übersicht über STEREO . Wir schlagen ein neuartiges zweistufiges Framework zum Löschen robuster Konzepte aus vorab trainierten Text-zu-Bild-Generierungsmodellen vor, ohne den Nutzen harmloser Konzepte wesentlich zu beeinträchtigen.
Stufe 1 (oben) : Search Thoroughly Enough (STE) folgt dem robusten Optimierungsrahmen des Adversarial Training und formuliert das Löschen von Konzepten als Min-Max-Optimierungsproblem, um starke kontradiktorische Eingabeaufforderungen zu entdecken, die Zielkonzepte aus gelöschten Modellen neu generieren können. Beachten Sie, dass die Kernneuheit unseres Ansatzes in der Tatsache liegt, dass wir AT nicht als endgültige Lösung einsetzen, sondern nur als Zwischenschritt, um gründlich genug nach starken kontradiktorischen Aufforderungen zu suchen.
Stufe 2 (unten) : Robustly Erase Once verfeinert das Modell mithilfe eines Ankerkonzepts und des Satzes starker gegnerischer Eingabeaufforderungen aus Stufe 1 über ein Kompositionsziel, wobei die High-Fidelity-Generierung harmloser Konzepte aufrechterhalten und gleichzeitig das Zielkonzept robust gelöscht wird.
Wenn Sie unsere Arbeit und dieses Repository nützlich finden, denken Sie bitte darüber nach, unserem Repo einen Stern zu geben und unseren Artikel wie folgt zu zitieren:
@article { srivatsan2024stereo ,
title = { STEREO: Towards Adversarially Robust Concept Erasing from Text-to-Image Generation Models } ,
author = { Srivatsan, Koushik and Shamshad, Fahad and Naseer, Muzammal and Nandakumar, Karthik } ,
journal = { arXiv preprint arXiv:2408.16807 } ,
year = { 2024 }
}Wenn Sie Fragen haben, erstellen Sie bitte ein Problem in diesem Repository oder wenden Sie sich an [email protected].
Unser Code basiert auf dem ESD-Repository. Wir danken den Autoren für die Veröffentlichung ihres Codes.


