BeatLearning
1.0.0
Wollten Sie schon immer einen Song spielen, der in Ihrem Lieblings-Rhythmusspiel nicht verfügbar war? Wollten Sie schon immer einmal unendlich viele Variationen dieses Liedes spielen?
Dieses Open-Source-Forschungsprojekt zielt darauf ab, den Prozess der automatischen Beatmap-Erstellung zu demokratisieren, indem es zugängliche Tools und Grundmodelle für Spieleentwickler, Spieler und Enthusiasten gleichermaßen bereitstellt und so den Weg für eine neue Ära der Kreativität und Innovation im Rhythmus-Gaming ebnet.
Beispiele (weitere folgen in Kürze):
Sie müssen zunächst Python 3.12 installieren, in das Verzeichnis des Repositorys gehen und eine virtuelle Umgebung erstellen über:
python3 -m venv venv
Rufen Sie dann source venv/bin/activate oder venvScriptsactivate wenn Sie sich auf einem Windows-Computer befinden. Nachdem die virtuelle Umgebung aktiviert wurde, können Sie die erforderlichen Bibliotheken installieren über:
pip3 install -r requirements.txt
Sie können Jupyter verwenden, um auf die Beispiel notebooks/ zuzugreifen:
jupyter notebook
Sie können auch die Google Collab-Version ausprobieren, solange Sie über GPU-Instanzen verfügen (die Standard-CPU-Instanzen brauchen ewig, um einen Song zu konvertieren).
Die Pipeline unterstützt derzeit nur OSU-Beatmaps.
Dieses Repository ist noch in Arbeit . Das Ziel besteht darin, generative Modelle zu entwickeln, die unabhängig vom Song automatisch Beatmaps für eine Vielzahl von Rhythmusspielen erstellen können. Diese Forschung ist noch im Gange, aber das Ziel besteht darin, MVPs so schnell wie möglich herauszubringen.
Alle Beiträge werden geschätzt, insbesondere in Form von Computerspenden für die Ausbildung von Stiftungsmodellen. Wenn Sie also Interesse haben, können Sie gerne mitmachen!
Entdecken Sie mit uns die endlosen Möglichkeiten der KI-gesteuerten Beatmap-Generierung und gestalten Sie die Zukunft von Rhythmus-Spielen!
Model(s) sind auf HuggingFace verfügbar.
Rhythmusspiel-Beatmaps werden zunächst in ein Zwischendateiformat konvertiert, das dann in 100-ms-Blöcke tokenisiert wird. Jeder Token ist in der Lage, bis zu zwei verschiedene Ereignisse innerhalb dieses Zeitraums (Holds und/oder Hits) zu kodieren, quantifiziert mit einer Genauigkeit von 10 ms. Um dieses Kriterium zu erfüllen, wird das Vokabular des Tokenizers vorberechnet und nicht aus den Daten gelernt. Aufgrund des Mangels an qualitativ hochwertigen Trainingsbeispielen in diesem Bereich werden die Kontextlänge und die Vokabulargröße absichtlich klein gehalten.
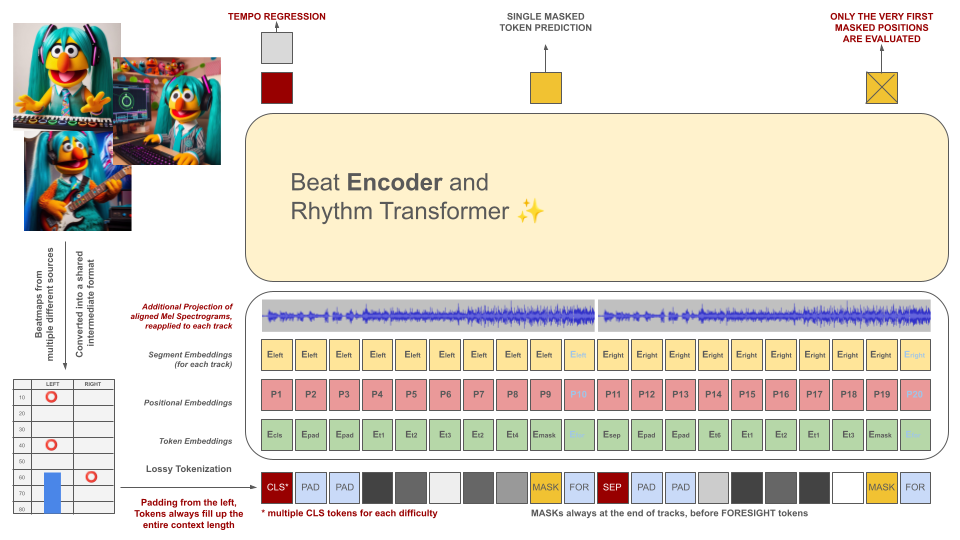 Diese Token dienen zusammen mit Abschnitten der Audiodaten (ihr projiziertes Mel-Spektogramm, das an den Token ausgerichtet ist) als Eingaben für ein maskiertes Encodermodell. Ähnlich wie BeRT verfolgt das Encodermodell während des Trainings zwei Ziele: das Schätzen des Tempos durch eine Regressionsaufgabe und das Vorhersagen der maskierten (nächsten) Token über eine Hörverlustfunktion . Beatmaps mit 1, 2 und 4 Spuren werden unterstützt. Jeder Token wird von links nach rechts vorhergesagt und spiegelt den Generierungsprozess einer Decoder-Architektur wider. Die maskierten Token haben jedoch auch Zugriff auf zusätzliche Audioinformationen aus der Zukunft, die als Foresight-Token von rechts bezeichnet werden.
Diese Token dienen zusammen mit Abschnitten der Audiodaten (ihr projiziertes Mel-Spektogramm, das an den Token ausgerichtet ist) als Eingaben für ein maskiertes Encodermodell. Ähnlich wie BeRT verfolgt das Encodermodell während des Trainings zwei Ziele: das Schätzen des Tempos durch eine Regressionsaufgabe und das Vorhersagen der maskierten (nächsten) Token über eine Hörverlustfunktion . Beatmaps mit 1, 2 und 4 Spuren werden unterstützt. Jeder Token wird von links nach rechts vorhergesagt und spiegelt den Generierungsprozess einer Decoder-Architektur wider. Die maskierten Token haben jedoch auch Zugriff auf zusätzliche Audioinformationen aus der Zukunft, die als Foresight-Token von rechts bezeichnet werden.
Der Zweck des KI-Modells besteht nicht darin, individuell erstellte Beatmaps abzuwerten, sondern vielmehr:
Alle generierten Inhalte müssen den EU-Vorschriften entsprechen und entsprechend gekennzeichnet sein, einschließlich Metadaten, die auf die Beteiligung des KI-Modells hinweisen.
DIE ERSTELLUNG VON BEATMAPS FÜR URHEBERRECHTLICH GESCHÜTZTES MATERIAL IST STRENGSTENS UNTERSAGT! VERWENDEN SIE NUR SONGS, AN DENEN SIE RECHTE BESITZEN!
Die in OSU-Dateibeispielen enthaltenen Audiodateien stammen von Künstlern, die auf der OSU-Website im Abschnitt „Vorgestellte Künstler“ aufgeführt sind, und sind speziell für die Verwendung in osu!-bezogenen Inhalten lizenziert.
Um zu verhindern, dass Ihre Beatmap in Zukunft als Trainingsdaten verwendet wird, fügen Sie die folgenden Metadaten in Ihre Beatmap-Datei ein:
robots: disallow
Das Projekt ist von einem früheren Versuch namens AIOSU inspiriert.
Neben der Nutzung des OSU-Wikis war osu-parser maßgeblich an der Klärung von Beatmap-Deklarationen (insbesondere Schiebereglern) beteiligt. Das Transformatormodell wurde von NanoGPT und der Pytorch-Implementierung von BeRT beeinflusst.


