CoPilot
v0.9.0
21.08.2024: CoPilot ist jetzt in v0.9 (v0.9.0) verfügbar . Weitere Informationen finden Sie in den Versionshinweisen. Hinweis: Auf TigerGraph Cloud ist nur CoPilot v0.5 verfügbar.
30.04.2024: CoPilot ist jetzt in der Betaversion (v0.5.0) verfügbar . CoPilot wird um eine ganz neue Funktion erweitert: Jetzt können Sie Chatbots mit grafikgestützter KI auf Ihren eigenen Dokumenten erstellen. CoPilot erstellt einen Wissensgraphen aus Quellmaterial und wendet den Wissensgraphen RAG (Retrieval Augmented Generation) an, um die Kontextrelevanz und Genauigkeit der Antworten auf ihre Fragen in natürlicher Sprache zu verbessern. Wir würden uns über Ihr Feedback freuen, um es weiter zu verbessern, damit es Ihnen einen größeren Mehrwert bringt. Es wäre hilfreich, wenn Sie diese kurze Umfrage ausfüllen könnten, nachdem Sie CoPilot gespielt haben. Vielen Dank für Ihr Interesse und Ihre Unterstützung!
18.03.2024: CoPilot ist jetzt in der Alphaversion (v0.0.1) verfügbar . Es verwendet ein Large Language Model (LLM), um Ihre Frage in einen Funktionsaufruf umzuwandeln, der dann im Diagramm in TigerGraph ausgeführt wird. Wir würden uns über Ihr Feedback freuen, um es weiter zu verbessern, damit es Ihnen einen größeren Mehrwert bringt. Wenn Sie es ausprobieren, wäre es hilfreich, wenn Sie dieses Anmeldeformular ausfüllen könnten, damit wir den Überblick behalten können (kein Spam, versprochen). Und wenn Sie einfach nur Feedback geben möchten, können Sie gerne an dieser kurzen Umfrage teilnehmen. Vielen Dank für Ihr Interesse und Ihre Unterstützung!
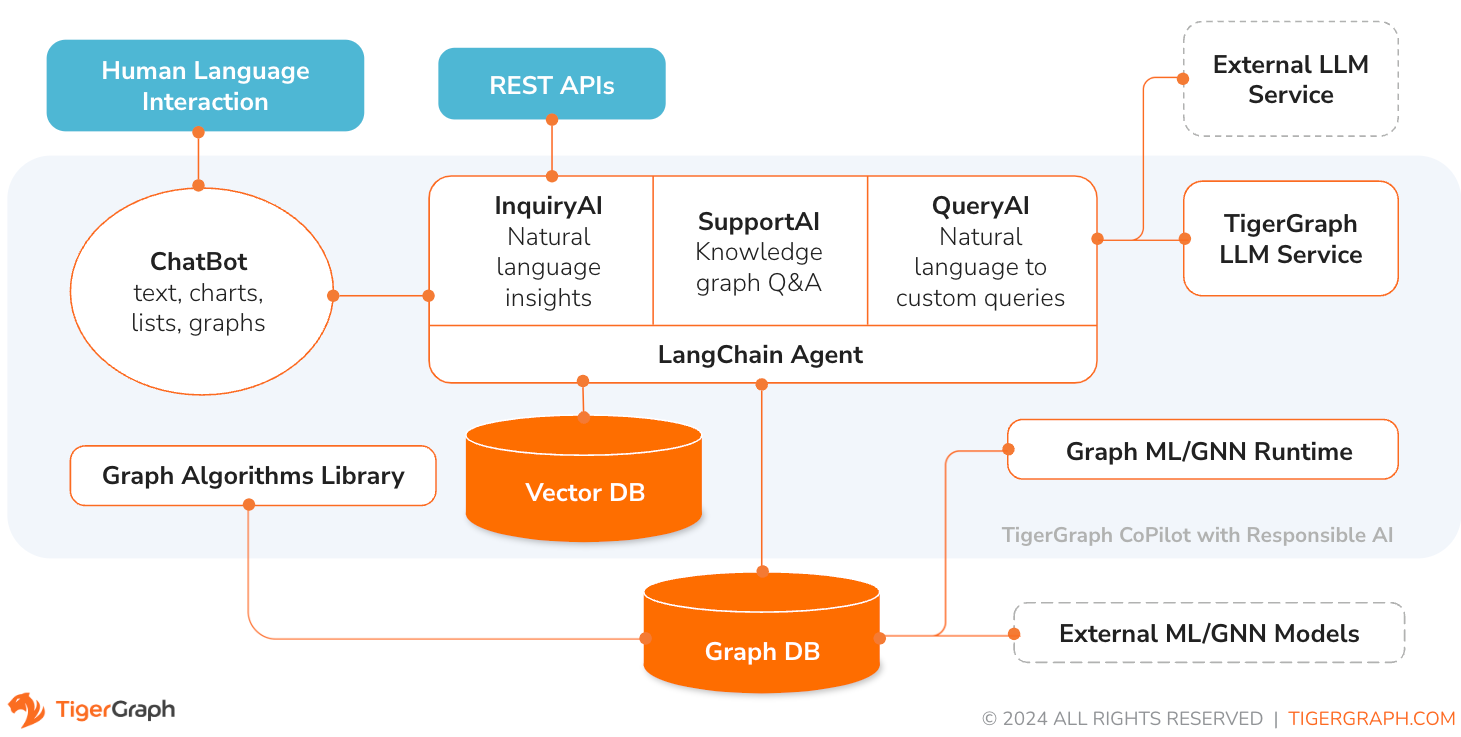
TigerGraph CoPilot ist ein KI-Assistent, der sorgfältig darauf ausgelegt ist, die Leistungsfähigkeit von Diagrammdatenbanken und generativer KI zu kombinieren, um den größtmöglichen Nutzen aus Daten zu ziehen und die Produktivität in verschiedenen Geschäftsfunktionen, einschließlich Analyse-, Entwicklungs- und Verwaltungsaufgaben, zu steigern. Es handelt sich um einen KI-Assistenten mit drei Kernkomponentendiensten:
Sie können mit CoPilot über eine Chat-Schnittstelle in TigerGraph Cloud, eine integrierte Chat-Schnittstelle und APIs interagieren. Derzeit sind Ihre eigenen LLM-Dienste (von OpenAI, Azure, GCP, AWS Bedrock, Ollama, Hugging Face und Groq.) erforderlich, um CoPilot zu verwenden, aber in zukünftigen Versionen können Sie die LLMs von TigerGraph verwenden.
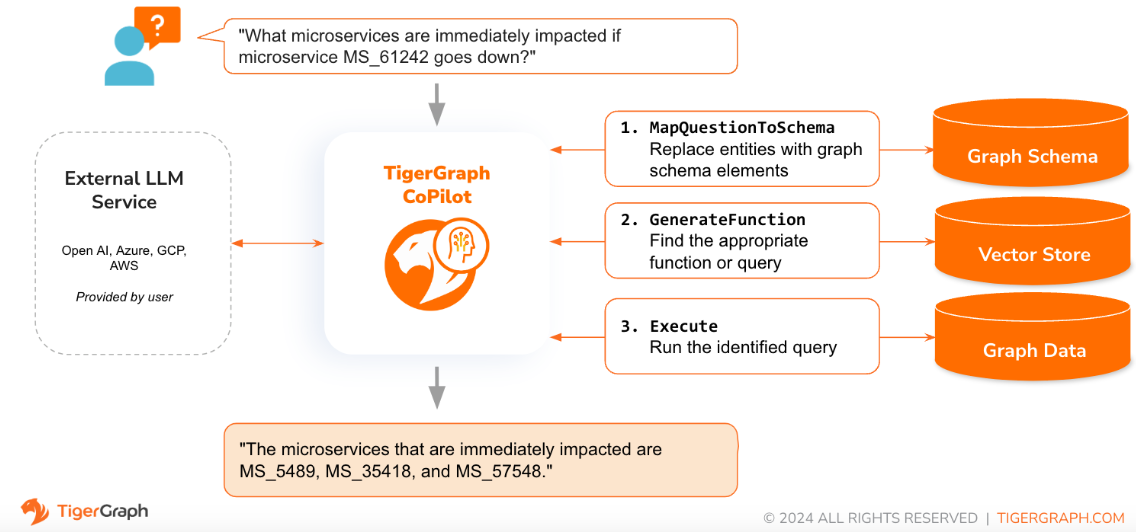
Wenn eine Frage in natürlicher Sprache gestellt wird, nutzt CoPilot (InquiryAI) eine neuartige dreiphasige Interaktion sowohl mit der TigerGraph-Datenbank als auch einem LLM nach Wahl des Benutzers, um genaue und relevante Antworten zu erhalten.
In der ersten Phase wird die Frage mit den jeweiligen in der Datenbank verfügbaren Daten abgeglichen. CoPilot verwendet das LLM, um die Frage mit dem Schema des Diagramms zu vergleichen und Entitäten in der Frage durch Diagrammelemente zu ersetzen. Wenn es beispielsweise einen Scheitelpunkttyp „BareMetalNode“ gibt und der Benutzer fragt „Wie viele Server gibt es?“, wird die Frage in „Wie viele BareMetalNode-Scheitelpunkte gibt es?“ übersetzt. In der zweiten Phase vergleicht CoPilot mithilfe des LLM die transformierte Frage mit einer Reihe kuratierter Datenbankabfragen und -funktionen, um die beste Übereinstimmung auszuwählen. In der dritten Phase führt CoPilot die identifizierte Abfrage aus und gibt das Ergebnis in natürlicher Sprache zusammen mit der Begründung der Aktionen zurück.
Die Verwendung vorab genehmigter Abfragen bietet mehrere Vorteile. Erstens verringert es die Wahrscheinlichkeit von Halluzinationen, da die Bedeutung und das Verhalten jeder Abfrage validiert wurden. Zweitens hat das System das Potenzial, die zur Beantwortung der Frage erforderlichen Ausführungsressourcen vorherzusagen.
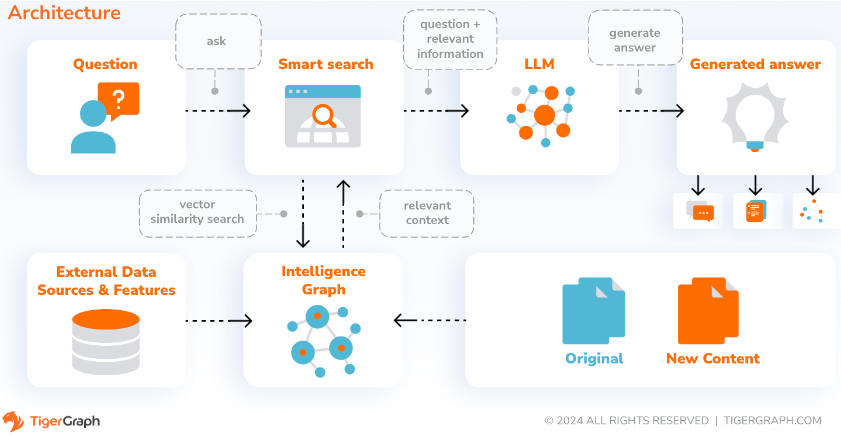
Mit SupportAI erstellt CoPilot Chatbots mit grafikgestützter KI für die eigenen Dokumente oder Textdaten eines Benutzers. Es erstellt einen Wissensgraphen aus Quellmaterial und wendet seine einzigartige Variante des auf Wissensgraphen basierenden RAG (Retrieval Augmented Generation) an, um die Kontextrelevanz und Genauigkeit von Antworten auf Fragen in natürlicher Sprache zu verbessern.
CoPilot identifiziert außerdem Konzepte und erstellt eine Ontologie, um dem Wissensgraphen Semantik und Argumentation hinzuzufügen. Alternativ können Benutzer ihre eigene Konzeptontologie bereitstellen. Anschließend führt CoPilot mit diesem umfassenden Wissensgraphen Hybridabrufe durch, bei denen traditionelle Vektorsuche und Diagrammdurchläufe kombiniert werden, um relevantere Informationen und umfassenderen Kontext zu sammeln und so die Wissensfragen der Benutzer zu beantworten.
Durch die Organisation der Daten als Wissensgraph kann ein Chatbot schnell und effizient auf genaue, faktenbasierte Informationen zugreifen und so weniger darauf angewiesen sein, Antworten auf der Grundlage von während des Trainings erlernten Mustern zu generieren, die manchmal falsch oder veraltet sein können.
QueryAI ist die dritte Komponente von TigerGraph CoPilot. Es ist als Entwicklertool konzipiert, das bei der Generierung von Diagrammabfragen in GSQL aus einer englischsprachigen Beschreibung hilft. Es kann auch zum Generieren von Schemata, Datenzuordnungen und sogar Dashboards verwendet werden. Dies wird es Entwicklern ermöglichen, GSQL-Abfragen schneller und genauer zu schreiben, und ist besonders nützlich für diejenigen, die neu bei GSQL sind. Derzeit ist die experimentelle OpenCypher-Generierung verfügbar.
CoPilot ist als Add-on-Dienst für Ihren Arbeitsbereich in der TigerGraph Cloud verfügbar. Es ist standardmäßig deaktiviert. Bitte kontaktieren Sie [email protected], um TigerGraph CoPilot als Option im Marketplace zu aktivieren.
TigerGraph CoPilot ist ein Open-Source-Projekt auf GitHub, das in Ihrer eigenen Infrastruktur bereitgestellt werden kann.
Wenn Sie den Quellcode von CoPilot nicht erweitern müssen, besteht der schnellste Weg darin, das Docker-Image mit der Docker-Compose-Datei im Repo bereitzustellen. Um diesen Weg gehen zu können, benötigen Sie folgende Voraussetzungen.
Schritt 1: Holen Sie sich die Docker-Compose-Datei
git clone https://github.com/tigergraph/CoPilot Die Docker Compose-Datei enthält alle Abhängigkeiten für CoPilot, einschließlich einer Milvus-Datenbank. Wenn Sie einen bestimmten Dienst nicht benötigen, können Sie die Compose-Datei bearbeiten, um ihn zu entfernen, oder die Skalierung auf 0 setzen, wenn Sie die Compose-Datei ausführen (Details später). Darüber hinaus verfügt CoPilot bei der Bereitstellung über eine Swagger-API-Dokumentationsseite. Wenn Sie es deaktivieren möchten, können Sie die Umgebungsvariable PRODUCTION für den CoPilot-Dienst in der Compose-Datei auf true setzen.
Schritt 2: Konfigurationen einrichten
Als nächstes erstellen Sie im selben Verzeichnis, in dem sich die Docker Compose-Datei befindet, die folgenden Konfigurationsdateien und füllen sie aus:
Schritt 3 (optional): Konfigurieren Sie die Protokollierung
touch configs/log_config.json . Details zur Konfiguration finden Sie hier.
Schritt 4: Starten Sie alle Dienste
Führen Sie nun einfach docker compose up -d aus und warten Sie, bis alle Dienste gestartet sind. Wenn Sie die mitgelieferte Milvus-Datenbank nicht verwenden möchten, können Sie deren Skalierung auf 0 setzen, um sie nicht zu starten: docker compose up -d --scale milvus-standalone=0 --scale etcd=0 --scale minio=0 .
Schritt 5: UDFs installieren
Dieser Schritt ist für TigerGraph-Datenbanken Version 4.x nicht erforderlich. Für TigerGraph 3.x müssen wir einige benutzerdefinierte Funktionen (UDFs) installieren, damit CoPilot funktioniert.
sudo su - tigergraph . Wenn TigerGraph auf einem Cluster läuft, können Sie dies auf jedem der Rechner tun. gadmin config set GSQL.UDF.EnablePutTgExpr true
gadmin config set GSQL.UDF.Policy.Enable false
gadmin config apply
gadmin restart GSQL
PUT tg_ExprFunctions FROM "./tg_ExprFunctions.hpp"
PUT tg_ExprUtil FROM "./tg_ExprUtil.hpp"
gadmin config set GSQL.UDF.EnablePutTgExpr false
gadmin config set GSQL.UDF.Policy.Enable true
gadmin config apply
gadmin restart GSQL
Kopieren Sie in der Datei configs/llm_config.json die JSON-Konfigurationsvorlage von unten für Ihren LLM-Anbieter und füllen Sie die entsprechenden Felder aus. Es wird nur ein Anbieter benötigt.
OpenAI
Zusätzlich zu OPENAI_API_KEY können llm_model und model_name bearbeitet werden, um sie an Ihre spezifischen Konfigurationsdetails anzupassen.
{
"model_name" : " GPT-4 " ,
"embedding_service" : {
"embedding_model_service" : " openai " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " YOUR_OPENAI_API_KEY_HERE "
}
},
"completion_service" : {
"llm_service" : " openai " ,
"llm_model" : " gpt-4-0613 " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " YOUR_OPENAI_API_KEY_HERE "
},
"model_kwargs" : {
"temperature" : 0
},
"prompt_path" : " ./app/prompts/openai_gpt4/ "
}
}GCP
Befolgen Sie die GCP-Authentifizierungsinformationen hier: https://cloud.google.com/docs/authentication/application-default-credentials#GAC und erstellen Sie ein Dienstkonto mit VertexAI-Anmeldeinformationen. Fügen Sie dann Folgendes zum Docker-Run-Befehl hinzu:
-v $( pwd ) /configs/SERVICE_ACCOUNT_CREDS.json:/SERVICE_ACCOUNT_CREDS.json -e GOOGLE_APPLICATION_CREDENTIALS=/SERVICE_ACCOUNT_CREDS.jsonUnd Ihre JSON-Konfiguration sollte wie folgt aussehen:
{
"model_name" : " GCP-text-bison " ,
"embedding_service" : {
"embedding_model_service" : " vertexai " ,
"authentication_configuration" : {}
},
"completion_service" : {
"llm_service" : " vertexai " ,
"llm_model" : " text-bison " ,
"model_kwargs" : {
"temperature" : 0
},
"prompt_path" : " ./app/prompts/gcp_vertexai_palm/ "
}
}Azurblau
Zusätzlich zu AZURE_OPENAI_ENDPOINT , AZURE_OPENAI_API_KEY und azure_deployment können llm_model und model_name bearbeitet werden, um sie an Ihre spezifischen Konfigurationsdetails anzupassen.
{
"model_name" : " GPT35Turbo " ,
"embedding_service" : {
"embedding_model_service" : " azure " ,
"azure_deployment" : " YOUR_EMBEDDING_DEPLOYMENT_HERE " ,
"authentication_configuration" : {
"OPENAI_API_TYPE" : " azure " ,
"OPENAI_API_VERSION" : " 2022-12-01 " ,
"AZURE_OPENAI_ENDPOINT" : " YOUR_AZURE_ENDPOINT_HERE " ,
"AZURE_OPENAI_API_KEY" : " YOUR_AZURE_API_KEY_HERE "
}
},
"completion_service" : {
"llm_service" : " azure " ,
"azure_deployment" : " YOUR_COMPLETION_DEPLOYMENT_HERE " ,
"openai_api_version" : " 2023-07-01-preview " ,
"llm_model" : " gpt-35-turbo-instruct " ,
"authentication_configuration" : {
"OPENAI_API_TYPE" : " azure " ,
"AZURE_OPENAI_ENDPOINT" : " YOUR_AZURE_ENDPOINT_HERE " ,
"AZURE_OPENAI_API_KEY" : " YOUR_AZURE_API_KEY_HERE "
},
"model_kwargs" : {
"temperature" : 0
},
"prompt_path" : " ./app/prompts/azure_open_ai_gpt35_turbo_instruct/ "
}
}AWS-Grundgestein
{
"model_name" : " Claude-3-haiku " ,
"embedding_service" : {
"embedding_model_service" : " bedrock " ,
"embedding_model" : " amazon.titan-embed-text-v1 " ,
"authentication_configuration" : {
"AWS_ACCESS_KEY_ID" : " ACCESS_KEY " ,
"AWS_SECRET_ACCESS_KEY" : " SECRET "
}
},
"completion_service" : {
"llm_service" : " bedrock " ,
"llm_model" : " anthropic.claude-3-haiku-20240307-v1:0 " ,
"authentication_configuration" : {
"AWS_ACCESS_KEY_ID" : " ACCESS_KEY " ,
"AWS_SECRET_ACCESS_KEY" : " SECRET "
},
"model_kwargs" : {
"temperature" : 0 ,
},
"prompt_path" : " ./app/prompts/aws_bedrock_claude3haiku/ "
}
}Ollama
{
"model_name" : " GPT-4 " ,
"embedding_service" : {
"embedding_model_service" : " openai " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " "
}
},
"completion_service" : {
"llm_service" : " ollama " ,
"llm_model" : " calebfahlgren/natural-functions " ,
"model_kwargs" : {
"temperature" : 0.0000001
},
"prompt_path" : " ./app/prompts/openai_gpt4/ "
}
}Umarmendes Gesicht
Unten ist eine Beispielkonfiguration für ein Modell auf Hugging Face mit einem dedizierten Endpunkt dargestellt. Bitte geben Sie Ihre Konfigurationsdetails an:
{
"model_name" : " llama3-8b " ,
"embedding_service" : {
"embedding_model_service" : " openai " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " "
}
},
"completion_service" : {
"llm_service" : " huggingface " ,
"llm_model" : " hermes-2-pro-llama-3-8b-lpt " ,
"endpoint_url" : " https:endpoints.huggingface.cloud " ,
"authentication_configuration" : {
"HUGGINGFACEHUB_API_TOKEN" : " "
},
"model_kwargs" : {
"temperature" : 0.1
},
"prompt_path" : " ./app/prompts/openai_gpt4/ "
}
}Unten ist eine Beispielkonfiguration für ein Modell auf Hugging Face mit einem serverlosen Endpunkt dargestellt. Bitte geben Sie Ihre Konfigurationsdetails an:
{
"model_name" : " Llama3-70b " ,
"embedding_service" : {
"embedding_model_service" : " openai " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " "
}
},
"completion_service" : {
"llm_service" : " huggingface " ,
"llm_model" : " meta-llama/Meta-Llama-3-70B-Instruct " ,
"authentication_configuration" : {
"HUGGINGFACEHUB_API_TOKEN" : " "
},
"model_kwargs" : {
"temperature" : 0.1
},
"prompt_path" : " ./app/prompts/llama_70b/ "
}
}Groq
{
"model_name" : " mixtral-8x7b-32768 " ,
"embedding_service" : {
"embedding_model_service" : " openai " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " "
}
},
"completion_service" : {
"llm_service" : " groq " ,
"llm_model" : " mixtral-8x7b-32768 " ,
"authentication_configuration" : {
"GROQ_API_KEY" : " "
},
"model_kwargs" : {
"temperature" : 0.1
},
"prompt_path" : " ./app/prompts/openai_gpt4/ "
}
} Kopieren Sie das Folgende in configs/db_config.json und bearbeiten Sie die Felder hostname und getToken , damit sie mit der Konfiguration Ihrer Datenbank übereinstimmen. Wenn die Token-Authentifizierung in TigerGraph aktiviert ist, setzen Sie getToken auf true . Legen Sie die Parameter „Timeout“, „Speicherschwellenwert“ und „Thread-Limit“ nach Bedarf fest, um zu steuern, wie viel Datenbankressourcen bei der Beantwortung einer Frage verbraucht werden.
„ecc“ und „chat_history_api“ sind die Adressen interner Komponenten von CoPilot. Wenn Sie die Docker Compose-Datei unverändert verwenden, müssen Sie sie nicht ändern.
{
"hostname" : " http://tigergraph " ,
"restppPort" : " 9000 " ,
"gsPort" : " 14240 " ,
"getToken" : false ,
"default_timeout" : 300 ,
"default_mem_threshold" : 5000 ,
"default_thread_limit" : 8 ,
"ecc" : " http://eventual-consistency-service:8001 " ,
"chat_history_api" : " http://chat-history:8002 "
} Kopieren Sie das Folgende in configs/milvus_config.json und bearbeiten Sie die host und port so, dass sie Ihrer Milvus-Konfiguration entsprechen (unter Berücksichtigung der Docker-Konfiguration). username und password können auch unten konfiguriert werden, wenn dies für Ihr Milvus-Setup erforderlich ist. enabled sollte vorerst immer auf „true“ gesetzt sein, da Milvus nur der unterstützte Einbettungsspeicher ist.
{
"host" : " milvus-standalone " ,
"port" : 19530 ,
"username" : " " ,
"password" : " " ,
"enabled" : " true " ,
"sync_interval_seconds" : 60
} Kopieren Sie den folgenden Code in configs/chat_config.json . Sie sollten nichts ändern müssen, es sei denn, Sie ändern den Port des Chat-Verlaufsdiensts in der Docker Compose-Datei.
{
"apiPort" : " 8002 " ,
"dbPath" : " chats.db " ,
"dbLogPath" : " db.log " ,
"logPath" : " requestLogs.jsonl " ,
"conversationAccessRoles": ["superuser", "globaldesigner"]
} Wenn Sie die OpenCypher-Abfragegenerierung in InquiryAI aktivieren möchten, können Sie die Umgebungsvariable USE_CYPHER im CoPilot-Dienst in der Docker-Compose-Datei auf "true" setzen. Standardmäßig ist dies auf "false" eingestellt. Hinweis : Die OpenCypher-Abfragegenerierung befindet sich noch in der Betaphase und funktioniert möglicherweise nicht wie erwartet. Außerdem besteht ein erhöhtes Potenzial für halluzinierte Antworten aufgrund schlechter Codegenerierung. Verwenden Sie es mit Vorsicht und nur in Nicht-Produktionsumgebungen.
CoPilot ist sowohl für technische als auch für nicht-technische Benutzer geeignet. Es gibt eine grafische Chat-Oberfläche sowie API-Zugriff auf CoPilot. Funktionsmäßig kann CoPilot Ihre Fragen beantworten, indem es vorhandene Abfragen in der Datenbank aufruft (InquiryAI), einen Wissensgraphen aus Ihren Dokumenten erstellen (SupportAI) und Wissensfragen basierend auf Ihren Dokumenten beantworten (SupportAI).
Weitere Informationen zur Verwendung von CoPilot finden Sie in unserer offiziellen Dokumentation.
TigerGraph CoPilot ist so konzipiert, dass es leicht erweiterbar ist. Der Dienst kann so konfiguriert werden, dass er verschiedene LLM-Anbieter, verschiedene Diagrammschemata und verschiedene LangChain-Tools verwendet. Der Dienst kann auch um die Nutzung verschiedener Einbettungsdienste, verschiedener LLM-Generierungsdienste und verschiedener LangChain-Tools erweitert werden. Weitere Informationen zur Erweiterung des Dienstes finden Sie im Entwicklerhandbuch.
Im tests ist eine Reihe von Tests enthalten. Wenn Sie weitere Tests hinzufügen möchten, lesen Sie bitte die Anleitung hier. Im Ordner ist auch ein Shell-Skript run_tests.sh enthalten, das als Treiber für die Ausführung der Tests dient. Der einfachste Weg, dieses Skript zu verwenden, besteht darin, es zum Testen im Docker-Container auszuführen.
Sie können Tests für jeden Dienst ausführen, indem Sie zur obersten Ebene des Dienstverzeichnisses gehen und python -m pytest ausführen
zB (von der obersten Ebene)
cd copilot
python -m pytest
cd ..Stellen Sie zunächst sicher, dass alle Konfigurationsdateien Ihres LLM-Dienstanbieters ordnungsgemäß funktionieren. Die Konfigurationen werden bereitgestellt, damit der Container darauf zugreifen kann. Stellen Sie außerdem sicher, dass alle Abhängigkeiten wie Datenbank und Milvus bereit sind. Wenn nicht, können Sie die mitgelieferte Docker-Compose-Datei ausführen, um diese Dienste zu erstellen.
docker compose up -d --buildWenn Sie Weights And Biases zum Protokollieren der Testergebnisse verwenden möchten, muss Ihr WandB-API-Schlüssel in einer Umgebungsvariablen auf dem Host-Computer festgelegt werden.
export WANDB_API_KEY=KEY HERE Anschließend können Sie den Docker-Container aus der Datei Dockerfile.tests erstellen und das Testskript im Container ausführen.
docker build -f Dockerfile.tests -t copilot-tests:0.1 .
docker run -d -v $( pwd ) /configs/:/ -e GOOGLE_APPLICATION_CREDENTIALS=/GOOGLE_SERVICE_ACCOUNT_CREDS.json -e WANDB_API_KEY= $WANDB_API_KEY -it --name copilot-tests copilot-tests:0.1
docker exec copilot-tests bash -c " conda run --no-capture-output -n py39 ./run_tests.sh all all " Um zu bearbeiten, welche Tests ausgeführt werden, können Argumente an das Skript ./run_tests.sh übergeben werden. Derzeit kann man konfigurieren, welcher LLM-Dienst verwendet werden soll (standardmäßig alle), welche Schemata getestet werden sollen (standardmäßig alle) und ob Gewichtungen und Verzerrungen für die Protokollierung verwendet werden sollen (standardmäßig „true“). Anweisungen zu den Optionen finden Sie unten:
Der erste Parameter von run_tests.sh gibt an, gegen welche LLMs getestet werden soll. Der Standardwert ist all . Die Optionen sind:
all – Tests für alle LLMs ausführenazure_gpt35 – Führen Sie Tests mit GPT-3.5 aus, das auf Azure gehostet wirdopenai_gpt35 – Führen Sie Tests gegen GPT-3.5 aus, das auf OpenAI gehostet wirdopenai_gpt4 – Führen Sie Tests auf GPT-4 aus, das auf OpenAI gehostet wirdgcp_textbison – führt Tests für Text-Bison durch, das auf der GCP gehostet wird Der zweite Parameter von run_tests.sh gibt an, gegen welche Diagramme getestet werden soll. Der Standardwert ist all . Die Optionen sind:
all – Führen Sie Tests für alle verfügbaren Diagramme durchOGB_MAG – Der Datensatz für wissenschaftliche Arbeiten, bereitgestellt von: https://ogb.stanford.edu/docs/nodeprop/#ogbn-mag.DigtialInfra – Digitaler Zwillingsdatensatz für die digitale InfrastrukturSynthea – Synthetischer Gesundheitsdatensatz Wenn Sie die Testergebnisse in Weights and Biases protokollieren möchten (und oben die richtigen Anmeldeinformationen eingerichtet haben), wird der letzte Parameter von run_tests.sh automatisch standardmäßig auf „true“ gesetzt. Wenn Sie die Protokollierung von Gewichtungen und Verzerrungen deaktivieren möchten, verwenden Sie false .
Wenn Sie zu TigerGraph CoPilot beitragen möchten, lesen Sie bitte die Dokumentation hier.


