horovod
v0.28.1: Build fixes (ROCm, GCC 12)
Horovod ist ein verteiltes Deep-Learning-Trainingsframework für TensorFlow, Keras, PyTorch und Apache MXNet. Das Ziel von Horovod ist es, verteiltes Deep Learning schnell und benutzerfreundlich zu machen.
Horovod wird von der LF AI & Data Foundation (LF AI & Data) gehostet. Wenn Sie ein Unternehmen sind, das sich stark für den Einsatz von Open-Source-Technologien in den Bereichen künstliche Intelligenz, maschinelles Lernen und Deep Learning einsetzt und die Communities von Open-Source-Projekten in diesen Bereichen unterstützen möchte, sollten Sie einen Beitritt zur LF AI & Data Foundation in Betracht ziehen. Einzelheiten darüber, wer beteiligt ist und welche Rolle Horovod spielt, finden Sie in der Ankündigung der Linux Foundation.
Inhalt
Die Hauptmotivation für dieses Projekt besteht darin, es einfach zu machen, ein Trainingsskript für eine einzelne GPU erfolgreich zu skalieren, um das Training auf vielen GPUs parallel durchzuführen. Dies hat zwei Aspekte:
Intern bei Uber haben wir festgestellt, dass das MPI-Modell viel einfacher ist und weitaus weniger Codeänderungen erfordert als frühere Lösungen wie Distributed TensorFlow mit Parameterservern. Sobald ein Trainingsskript für die Skalierung mit Horovod geschrieben wurde, kann es ohne weitere Codeänderungen auf einer einzelnen GPU, mehreren GPUs oder sogar mehreren Hosts ausgeführt werden. Weitere Einzelheiten finden Sie im Abschnitt „Nutzung“.
Horovod ist nicht nur einfach zu bedienen, sondern auch schnell. Nachfolgend finden Sie ein Diagramm, das den Benchmark darstellt, der auf 128 Servern mit jeweils 4 Pascal-GPUs durchgeführt wurde, die über ein RoCE-fähiges 25-Gbit/s-Netzwerk verbunden sind:
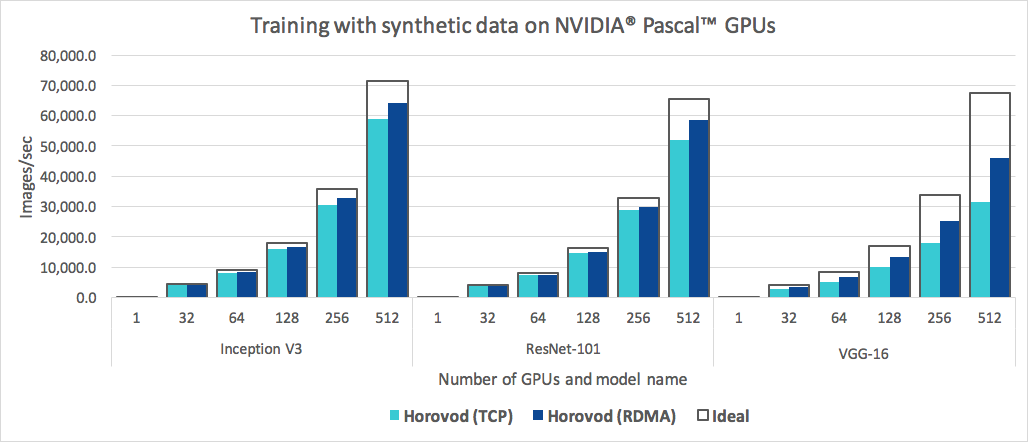
Horovod erreicht eine Skalierungseffizienz von 90 % für Inception V3 und ResNet-101 und 68 % Skalierungseffizienz für VGG-16. Unter Benchmarks erfahren Sie, wie Sie diese Zahlen reproduzieren können.
Auch wenn die Installation von MPI und NCCL selbst wie ein zusätzlicher Aufwand erscheinen mag, muss sie nur einmal von dem Team durchgeführt werden, das sich um die Infrastruktur kümmert, während alle anderen im Unternehmen, die die Modelle erstellen, die Einfachheit des maßstabsgetreuen Trainings genießen können.
So installieren Sie Horovod unter Linux oder macOS:
Wenn Sie TensorFlow von PyPI installiert haben, stellen Sie sicher, dass g++-5 oder höher installiert ist. Ab TensorFlow 2.10 ist ein C++17-kompatibler Compiler wie g++8 oder höher erforderlich.
Wenn Sie PyTorch von PyPI installiert haben, stellen Sie sicher, dass g++-5 oder höher installiert ist.
Wenn Sie eines der Pakete von Conda installiert haben, stellen Sie sicher, dass das Conda-Paket gxx_linux-64 installiert ist.
Installieren Sie das horovod Pip-Paket.
Zur Ausführung auf CPUs:
$ pip install horovodZur Ausführung auf GPUs mit NCCL:
$ HOROVOD_GPU_OPERATIONS=NCCL pip install horovodWeitere Informationen zur Installation von Horovod mit GPU-Unterstützung finden Sie unter Horovod zur GPU.
Die vollständige Liste der Horovod-Installationsoptionen finden Sie im Installationshandbuch.
Wenn Sie MPI verwenden möchten, lesen Sie Horovod mit MPI.
Wenn Sie Conda verwenden möchten, lesen Sie „Erstellen einer Conda-Umgebung mit GPU-Unterstützung für Horovod“.
Wenn Sie Docker verwenden möchten, lesen Sie Horovod in Docker.
Um Horovod aus dem Quellcode zu kompilieren, befolgen Sie die Anweisungen im Contributor Guide.
Die Kernprinzipien von Horovod basieren auf MPI-Konzepten wie Größe , Rang , lokaler Rang , Allreduce , Allgather , Broadcast und Alltoall . Weitere Einzelheiten finden Sie auf dieser Seite.
Auf diesen Seiten finden Sie Horovod-Beispiele und Best Practices:
Um Horovod zu verwenden, nehmen Sie die folgenden Ergänzungen zu Ihrem Programm vor:
hvd.init() aus, um Horovod zu initialisieren.Binden Sie jede GPU an einen einzelnen Prozess, um Ressourcenkonflikte zu vermeiden.
Bei der typischen Einrichtung einer GPU pro Prozess stellen Sie diese auf „Local Rank“ ein. Dem ersten Prozess auf dem Server wird die erste GPU zugewiesen, dem zweiten Prozess wird die zweite GPU zugewiesen und so weiter.
Skalieren Sie die Lernrate anhand der Anzahl der Mitarbeiter.
Die effektive Batchgröße beim synchronen verteilten Training wird durch die Anzahl der Arbeiter skaliert. Eine Erhöhung der Lernrate gleicht die erhöhte Batchgröße aus.
Wickeln Sie den Optimierer in hvd.DistributedOptimizer .
Der verteilte Optimierer delegiert die Gradientenberechnung an den ursprünglichen Optimierer, mittelt die Gradienten mit allreduce oder allgather und wendet dann diese gemittelten Gradienten an.
Übertragen Sie die anfänglichen Variablenzustände ab Rang 0 an alle anderen Prozesse.
Dies ist notwendig, um eine konsistente Initialisierung aller Arbeiter sicherzustellen, wenn das Training mit zufälligen Gewichten gestartet oder von einem Kontrollpunkt wiederhergestellt wird.
Beispiel mit TensorFlow v1 (vollständige Trainingsbeispiele finden Sie im Beispielverzeichnis):
import tensorflow as tf
import horovod . tensorflow as hvd
# Initialize Horovod
hvd . init ()
# Pin GPU to be used to process local rank (one GPU per process)
config = tf . ConfigProto ()
config . gpu_options . visible_device_list = str ( hvd . local_rank ())
# Build model...
loss = ...
opt = tf . train . AdagradOptimizer ( 0.01 * hvd . size ())
# Add Horovod Distributed Optimizer
opt = hvd . DistributedOptimizer ( opt )
# Add hook to broadcast variables from rank 0 to all other processes during
# initialization.
hooks = [ hvd . BroadcastGlobalVariablesHook ( 0 )]
# Make training operation
train_op = opt . minimize ( loss )
# Save checkpoints only on worker 0 to prevent other workers from corrupting them.
checkpoint_dir = '/tmp/train_logs' if hvd . rank () == 0 else None
# The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
with tf . train . MonitoredTrainingSession ( checkpoint_dir = checkpoint_dir ,
config = config ,
hooks = hooks ) as mon_sess :
while not mon_sess . should_stop ():
# Perform synchronous training.
mon_sess . run ( train_op )Die folgenden Beispielbefehle zeigen, wie verteiltes Training ausgeführt wird. Weitere Informationen, einschließlich RoCE/InfiniBand-Optimierungen und Tipps zum Umgang mit Hängen, finden Sie unter „Run Horovod“.
Zur Ausführung auf einer Maschine mit 4 GPUs:
$ horovodrun -np 4 -H localhost:4 python train.pyZur Ausführung auf 4 Maschinen mit jeweils 4 GPUs:
$ horovodrun -np 16 -H server1:4,server2:4,server3:4,server4:4 python train.py Informationen zur Ausführung mit Open MPI ohne den horovodrun Wrapper finden Sie unter Ausführen von Horovod mit Open MPI.
Informationen zur Ausführung in Docker finden Sie unter Horovod in Docker.
Informationen zur Ausführung auf Kubernetes finden Sie unter Helm Chart, Kubeflow MPI Operator, FfDL und Polyaxon.
Informationen zum Ausführen auf Spark finden Sie unter Horovod auf Spark.
Um auf Ray zu laufen, siehe Horovod auf Ray.
Informationen zum Ausführen in Singularität finden Sie unter Singularität.
Informationen zur Ausführung in einem LSF-HPC-Cluster (z. B. Summit) finden Sie unter LSF.
Informationen zur Ausführung mit Hadoop Yarn finden Sie unter TonY.
Gloo ist eine von Facebook entwickelte Open-Source-Bibliothek für kollektive Kommunikation.
Gloo ist im Lieferumfang von Horovod enthalten und ermöglicht Benutzern die Ausführung von Horovod, ohne dass MPI installiert werden muss.
Für Umgebungen, die sowohl MPI als auch Gloo unterstützen, können Sie Gloo zur Laufzeit verwenden, indem Sie das Argument --gloo an horovodrun übergeben:
$ horovodrun --gloo -np 2 python train.pyHorovod unterstützt das Mischen und Abgleichen von Horovod-Kollektiven mit anderen MPI-Bibliotheken wie mpi4py, sofern das MPI mit Multithreading-Unterstützung erstellt wurde.
Sie können die MPI-Multithreading-Unterstützung überprüfen, indem Sie die Funktion hvd.mpi_threads_supported() abfragen.
import horovod . tensorflow as hvd
# Initialize Horovod
hvd . init ()
# Verify that MPI multi-threading is supported.
assert hvd . mpi_threads_supported ()
from mpi4py import MPI
assert hvd . size () == MPI . COMM_WORLD . Get_size ()Sie können Horovod auch mit einem mpi4py-Subkommunikator initialisieren. In diesem Fall führt jeder Subkommunikator ein unabhängiges Horovod-Training durch.
from mpi4py import MPI
import horovod . tensorflow as hvd
# Split COMM_WORLD into subcommunicators
subcomm = MPI . COMM_WORLD . Split ( color = MPI . COMM_WORLD . rank % 2 ,
key = MPI . COMM_WORLD . rank )
# Initialize Horovod
hvd . init ( comm = subcomm )
print ( 'COMM_WORLD rank: %d, Horovod rank: %d' % ( MPI . COMM_WORLD . rank , hvd . rank ()))Erfahren Sie hier, wie Sie Ihr Modell für Inferenz optimieren und Horovod-Operationen aus dem Diagramm entfernen.
Eines der einzigartigen Dinge an Horovod ist seine Fähigkeit, Kommunikation und Berechnung zu verschachteln, gepaart mit der Fähigkeit, kleine Allreduce -Vorgänge in Stapeln durchzuführen, was zu einer verbesserten Leistung führt. Wir nennen diese Batch-Funktion Tensor Fusion.
Ausführliche Informationen und Anleitungen zur Optimierung finden Sie hier.
Horovod hat die Möglichkeit, die Zeitleiste seiner Aktivitäten aufzuzeichnen, die sogenannte Horovod-Zeitleiste.
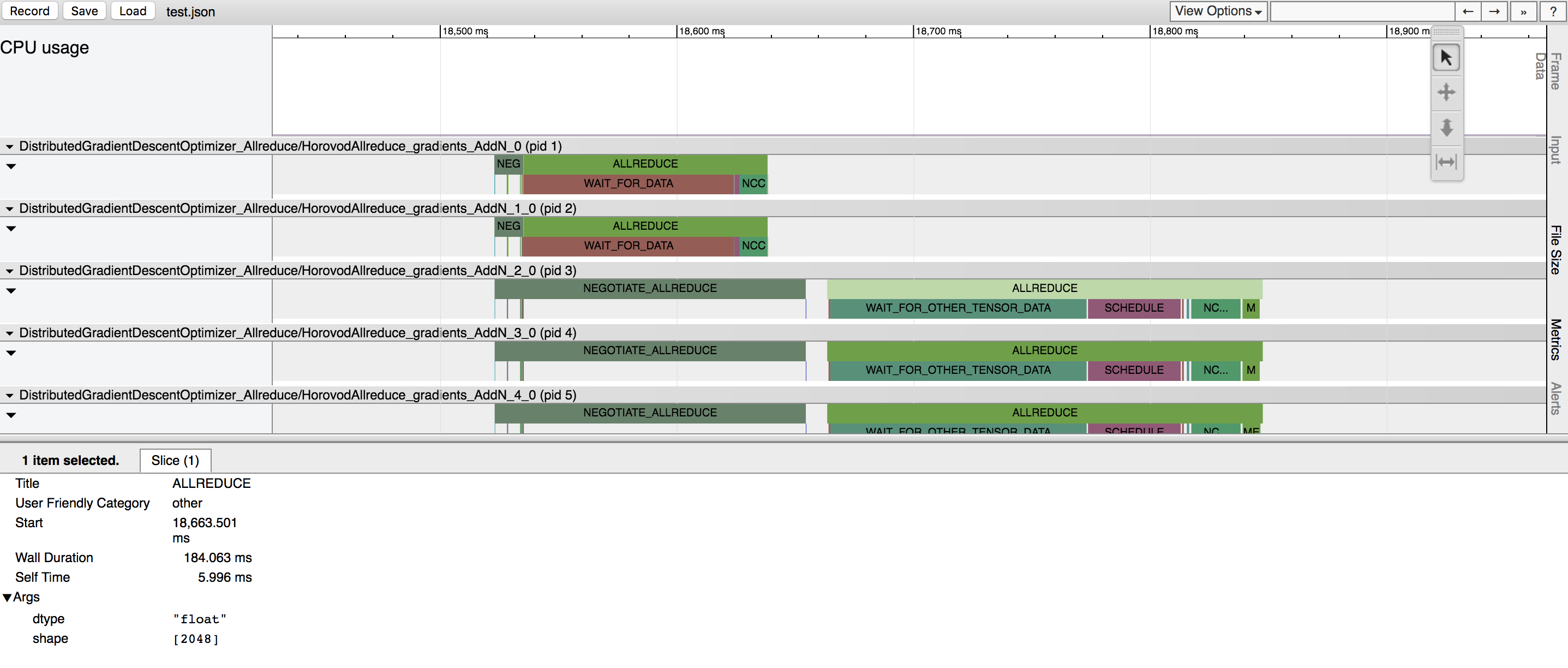
Verwenden Sie die Horovod-Zeitleiste, um die Leistung von Horovod zu analysieren. Ausführliche Informationen und Gebrauchsanweisungen finden Sie hier.
Die Auswahl der richtigen Werte zur effizienten Nutzung von Tensor Fusion und anderen erweiterten Horovod-Funktionen kann eine Menge Versuch und Irrtum erfordern. Wir bieten ein System zur Automatisierung dieses Leistungsoptimierungsprozesses namens Autotuning an, das Sie mit einem einzigen Befehlszeilenargument für horovodrun aktivieren können.
Ausführliche Informationen und Gebrauchsanweisungen finden Sie hier.
Mit Horovod können Sie gleichzeitig verschiedene kollektive Vorgänge in verschiedenen Prozessgruppen ausführen, die an einem verteilten Training teilnehmen. Richten Sie hvd.process_set Objekte ein, um diese Funktion zu nutzen.
Ausführliche Anweisungen finden Sie unter Prozesssätze.
Senden Sie uns Links zu allen Benutzerhandbüchern, die Sie auf dieser Website veröffentlichen möchten
Sehen Sie sich „Fehlerbehebung“ an und reichen Sie ein Ticket ein, wenn Sie keine Antwort finden.
Bitte zitieren Sie Horovod in Ihren Veröffentlichungen, wenn es Ihrer Forschung hilft:
@article{sergeev2018horovod,
Autor = {Alexander Sergeev und Mike Del Balso},
Journal = {arXiv preprint arXiv:1802.05799},
Titel = {Horovod: schnelles und einfaches verteiltes Deep Learning in {TensorFlow}},
Jahr = {2018}
}
1. Sergeev, A., Del Balso, M. (2017) Lernen Sie Horovod kennen: Ubers Open-Source-Framework für verteiltes Deep Learning für TensorFlow . Abgerufen von https://eng.uber.com/horovod/
2. Sergeev, A. (2017) Horovod – Verteilter TensorFlow leicht gemacht . Abgerufen von https://www.slideshare.net/AlexanderSergeev4/horovod-distributed-tensorflow-made-easy
3. Sergeev, A., Del Balso, M. (2018) Horovod: schnelles und einfaches verteiltes Deep Learning in TensorFlow . Abgerufen von arXiv:1802.05799
Der Horovod-Quellcode basierte auf dem Baidu-Tensorflow-Allreduce-Repository, das von Andrew Gibiansky und Joel Hestness geschrieben wurde. Ihre ursprüngliche Arbeit wird im Artikel „Bringing HPC Techniques to Deep Learning“ beschrieben.


