ffhq dataset
1.0.0

Flickr-Faces-HQ (FFHQ) ist ein hochwertiger Bilddatensatz menschlicher Gesichter, der ursprünglich als Benchmark für generative Adversarial Networks (GAN) erstellt wurde:
Eine stilbasierte Generatorarchitektur für generative gegnerische Netzwerke
Tero Karras (NVIDIA), Samuli Laine (NVIDIA), Timo Aila (NVIDIA)
https://arxiv.org/abs/1812.04948
Der Datensatz besteht aus 70.000 hochwertigen PNG-Bildern mit einer Auflösung von 1024 x 1024 und weist erhebliche Unterschiede in Bezug auf Alter, ethnische Zugehörigkeit und Bildhintergrund auf. Auch Accessoires wie Brillen, Sonnenbrillen, Hüte usw. werden gut abgedeckt. Die Bilder wurden von Flickr gecrawlt, übernahmen also alle Vorurteile dieser Website und wurden mit dlib automatisch ausgerichtet und zugeschnitten. Es wurden nur Bilder unter freizügigen Lizenzen gesammelt. Verschiedene automatische Filter wurden verwendet, um das Set zu bereinigen, und schließlich wurde Amazon Mechanical Turk verwendet, um gelegentlich Statuen, Gemälde oder Fotos von Fotos zu entfernen.
Bitte beachten Sie, dass dieser Datensatz nicht für die Entwicklung oder Verbesserung von Gesichtserkennungstechnologien bestimmt ist und nicht dafür verwendet werden sollte. Für geschäftliche Anfragen besuchen Sie bitte unsere Website und senden Sie das Formular ab: NVIDIA Research Licensing
Die einzelnen Bilder wurden von ihren jeweiligen Autoren entweder unter der Creative Commons BY 2.0-, Creative Commons BY-NC 2.0-, Public Domain Mark 1.0-, Public Domain CC0 1.0- oder US Government Works-Lizenz auf Flickr veröffentlicht. Alle diese Lizenzen erlauben die kostenlose Nutzung, Weiterverbreitung und Anpassung für nichtkommerzielle Zwecke . In einigen Fällen ist jedoch eine entsprechende Nennung des ursprünglichen Autors sowie die Angabe aller an den Bildern vorgenommenen Änderungen erforderlich. Die Lizenz und der ursprüngliche Autor jedes Bildes sind in den Metadaten angegeben.
Der Datensatz selbst (einschließlich JSON-Metadaten, Download-Skript und Dokumentation) wird unter der Creative Commons BY-NC-SA 4.0-Lizenz von NVIDIA Corporation zur Verfügung gestellt. Sie können es für nichtkommerzielle Zwecke verwenden, weiterverbreiten und anpassen , sofern Sie (a) durch Zitieren unseres Artikels eine entsprechende Quellenangabe machen, (b) alle von Ihnen vorgenommenen Änderungen angeben und (c) abgeleitete Werke verbreiten unter der gleichen Lizenz .
Alle Daten werden auf Google Drive gehostet:
| Weg | Größe | Dateien | Format | Beschreibung |
|---|---|---|---|---|
| ffhq-Datensatz | 2,56 TB | 210.014 | Hauptordner | |
| ├ ffhq-dataset-v2.json | 255 MB | 1 | JSON | Metadaten einschließlich Copyright-Informationen, URLs usw. |
| ├ Bilder1024x1024 | 89,1 GB | 70.000 | PNG | Ausgerichtete und zugeschnittene Bilder bei 1024×1024 |
| ├ Miniaturansichten 128 x 128 | 1,95 GB | 70.000 | PNG | Miniaturansichten im Format 128×128 |
| ├ In-the-Wild-Bilder | 955 GB | 70.000 | PNG | Originalbilder von Flickr |
| ├ tfrecords | 273 GB | 9 | tfrecords | Daten mit mehreren Auflösungen für StyleGAN und StyleGAN2 |
| └ Reißverschlüsse | 1,28 TB | 4 | REISSVERSCHLUSS | Inhalt jedes Ordners als ZIP-Archiv. |
Statistiken auf hoher Ebene:
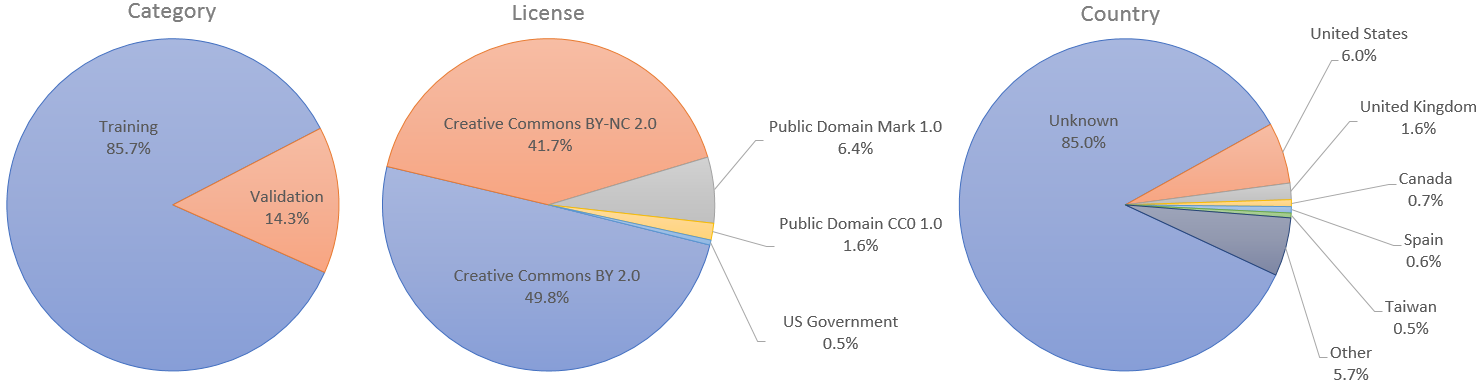
Für Anwendungsfälle, die separate Trainings- und Validierungssätze erfordern, haben wir die ersten 60.000 Bilder für das Training und die restlichen 10.000 für die Validierung vorgesehen. Im StyleGAN-Artikel haben wir jedoch alle 70.000 Bilder für das Training verwendet.
Wir haben ausdrücklich darauf geachtet, dass im Datensatz selbst keine doppelten Bilder vorhanden sind. Bitte beachten Sie jedoch, dass der in-the-wild -Ordner möglicherweise mehrere Kopien desselben Bildes enthält, wenn wir mehrere verschiedene Gesichter aus demselben Bild extrahiert haben.
Sie können die Daten entweder direkt von Google Drive abrufen oder das bereitgestellte Download-Skript verwenden. Das Skript erleichtert die Arbeit erheblich, indem es alle angeforderten Dateien automatisch herunterlädt, ihre Prüfsummen überprüft, jede Datei bei Fehlern mehrmals wiederholt und mehrere gleichzeitige Verbindungen verwendet, um die Bandbreite zu maximieren.
> python download_ffhq.py -h
usage: download_ffhq.py [-h] [-j] [-s] [-i] [-t] [-w] [-r] [-a]
[--num_threads NUM] [--status_delay SEC]
[--timing_window LEN] [--chunk_size KB]
[--num_attempts NUM]
Download Flickr-Face-HQ (FFHQ) dataset to current working directory.
optional arguments:
-h, --help show this help message and exit
-j, --json download metadata as JSON (254 MB)
-s, --stats print statistics about the dataset
-i, --images download 1024x1024 images as PNG (89.1 GB)
-t, --thumbs download 128x128 thumbnails as PNG (1.95 GB)
-w, --wilds download in-the-wild images as PNG (955 GB)
-r, --tfrecords download multi-resolution TFRecords (273 GB)
-a, --align recreate 1024x1024 images from in-the-wild images
--num_threads NUM number of concurrent download threads (default: 32)
--status_delay SEC time between download status prints (default: 0.2)
--timing_window LEN samples for estimating download eta (default: 50)
--chunk_size KB chunk size for each download thread (default: 128)
--num_attempts NUM number of download attempts per file (default: 10)
--random-shift SHIFT standard deviation of random crop rectangle jitter
--retry-crops retry random shift if crop rectangle falls outside image (up to 1000
times)
--no-rotation keep the original orientation of images
--no-padding do not apply blur-padding outside and near the image borders
--source-dir DIR where to find already downloaded FFHQ source data
> python ..download_ffhq.py --json --images
Downloading JSON metadata...
100.00% done 2/2 files 0.25/0.25 GB 43.21 MB/s ETA: done
Parsing JSON metadata...
Downloading 70000 files...
| 100.00% done 70001/70001 files 89.19 GB/89.19 GB 59.87 MB/s ETA: done
Das Skript dient auch als Referenzimplementierung des automatisierten Schemas, das wir zum Ausrichten und Zuschneiden der Bilder verwendet haben. Sobald Sie die In-the-Wild-Bilder mit python download_ffhq.py --wilds heruntergeladen haben, können Sie python download_ffhq.py --align ausführen, um exakte Replikate der ausgerichteten 1024×1024-Bilder unter Verwendung der in den Metadaten enthaltenen Standorte der Gesichtsmarkierungen zu reproduzieren .
Um den „nicht ausgerichteten FFHQ“-Datensatz zu reproduzieren, wie er im Dokument „Alias-Free Generative Adversarial Networks“ verwendet wird, verwenden Sie die folgenden Optionen:
python download_ffhq.py
--source-dir <path/to/downloaded/ffhq>
--align --no-rotation --random-shift 0.2 --no-padding --retry-crops
Die Datei ffhq-dataset-v2.json enthält die folgenden Informationen für jedes Bild in einem maschinenlesbaren Format:
{
"0": { # Image index
"category": "training", # Training or validation
"metadata": { # Info about the original Flickr photo:
"photo_url": "https://www.flickr.com/photos/...", # - Flickr URL
"photo_title": "DSCF0899.JPG", # - File name
"author": "Jeremy Frumkin", # - Author
"country": "", # - Country where the photo was taken
"license": "Attribution-NonCommercial License", # - License name
"license_url": "https://creativecommons.org/...", # - License detail URL
"date_uploaded": "2007-08-16", # - Date when the photo was uploaded to Flickr
"date_crawled": "2018-10-10" # - Date when the photo was crawled from Flickr
},
"image": { # Info about the aligned 1024x1024 image:
"file_url": "https://drive.google.com/...", # - Google Drive URL
"file_path": "images1024x1024/00000/00000.png", # - Google Drive path
"file_size": 1488194, # - Size of the PNG file in bytes
"file_md5": "ddeaeea6ce59569643715759d537fd1b", # - MD5 checksum of the PNG file
"pixel_size": [1024, 1024], # - Image dimensions
"pixel_md5": "47238b44dfb87644460cbdcc4607e289", # - MD5 checksum of the raw pixel data
"face_landmarks": [...] # - 68 face landmarks reported by dlib
},
"thumbnail": { # Info about the 128x128 thumbnail:
"file_url": "https://drive.google.com/...", # - Google Drive URL
"file_path": "thumbnails128x128/00000/00000.png", # - Google Drive path
"file_size": 29050, # - Size of the PNG file in bytes
"file_md5": "bd3e40b2ba20f76b55dc282907b89cd1", # - MD5 checksum of the PNG file
"pixel_size": [128, 128], # - Image dimensions
"pixel_md5": "38d7e93eb9a796d0e65f8c64de8ba161" # - MD5 checksum of the raw pixel data
},
"in_the_wild": { # Info about the in-the-wild image:
"file_url": "https://drive.google.com/...", # - Google Drive URL
"file_path": "in-the-wild-images/00000/00000.png", # - Google Drive path
"file_size": 3991569, # - Size of the PNG file in bytes
"file_md5": "1dc0287e73e485efb0516a80ce9d42b4", # - MD5 checksum of the PNG file
"pixel_size": [2016, 1512], # - Image dimensions
"pixel_md5": "86b3470c42e33235d76b979161fb2327", # - MD5 checksum of the raw pixel data
"face_rect": [667, 410, 1438, 1181], # - Axis-aligned rectangle of the face region
"face_landmarks": [...], # - 68 face landmarks reported by dlib
"face_quad": [...] # - Aligned quad of the face region
}
},
...
}
Wir danken Jaakko Lehtinen, David Luebke und Tuomas Kynkäänniemi für ausführliche Diskussionen und hilfreiche Kommentare; Janne Hellsten, Tero Kuosmanen und Pekka Jänis für die Recheninfrastruktur und Hilfe bei der Codefreigabe.
Wir danken auch Vahid Kazemi und Josephine Sullivan für ihre Arbeit zur automatischen Gesichtserkennung und -ausrichtung, die es uns überhaupt erst ermöglicht hat, die Daten zu sammeln:
Eine Millisekunde Gesichtsausrichtung mit einem Ensemble von Regressionsbäumen
Vahid Kazemi, Josephine Sullivan
Proz. CVPR 2014
https://www.cv-foundation.org/openaccess/content_cvpr_2014/papers/Kazemi_One_Millisecond_Face_2014_CVPR_paper.pdf
Bei der Erhebung der Daten haben wir darauf geachtet, nur Fotos einzubeziehen, die nach unserem besten Wissen zur freien Nutzung und Weiterverbreitung durch die jeweiligen Urheber bestimmt waren. Wir sind jedoch bestrebt, die Privatsphäre von Personen zu schützen, die nicht möchten, dass ihre Fotos aufgenommen werden.
Um herauszufinden, ob Ihr Foto im Flickr-Faces-HQ-Datensatz enthalten ist, klicken Sie bitte auf diesen Link, um den Datensatz mit Ihrem Flickr-Benutzernamen zu durchsuchen.
So entfernen Sie Ihr Foto aus dem Flickr-Faces-HQ-Datensatz:
no_cv , um anzugeben, dass Sie es nicht für die Computer-Vision-Forschung verwenden möchten.None (Alle Rechte vorbehalten) oder eine beliebige Creative-Commons-Lizenz mit NoDerivs , um anzugeben, dass Sie nicht möchten, dass es weiterverbreitet wird.

