INTR
1.0.0
Dieses Repo ist die offizielle Implementierung von INTR: A Simple Interpretable Transformer for Fine-grained Image Classification and Analysis. Es umfasst derzeit Code und Modelle für die Interpretation feinkörniger Daten. Wir werden einen Link zum bevorstehenden ICLR 2024-Protokoll für dieses Papier bereitstellen, sobald es online verfügbar ist.
INTR ist eine neuartige Verwendung von Transformers, um die Bildklassifizierung interpretierbar zu machen. In INTR untersuchen wir einen proaktiven Ansatz zur Klassifizierung, bei dem jede Klasse aufgefordert wird, in einem Bild nach sich selbst zu suchen. Wir lernen klassenspezifische Abfragen (eine für jede Klasse) als Eingabe für den Decoder, sodass diese über Kreuzaufmerksamkeit nach ihrer Präsenz in einem Bild suchen können. Wir zeigen, dass INTR jede Klasse von Natur aus dazu ermutigt, gezielt teilzunehmen; Die Kreuzaufmerksamkeitsgewichte liefern somit eine aussagekräftige Interpretation der Vorhersage des Modells. Interessanterweise könnte INTR durch Multi-Head-Cross-Attention lernen, verschiedene Attribute einer Klasse zu lokalisieren, wodurch es sich besonders für eine feinkörnige Klassifizierung und Analyse eignet.
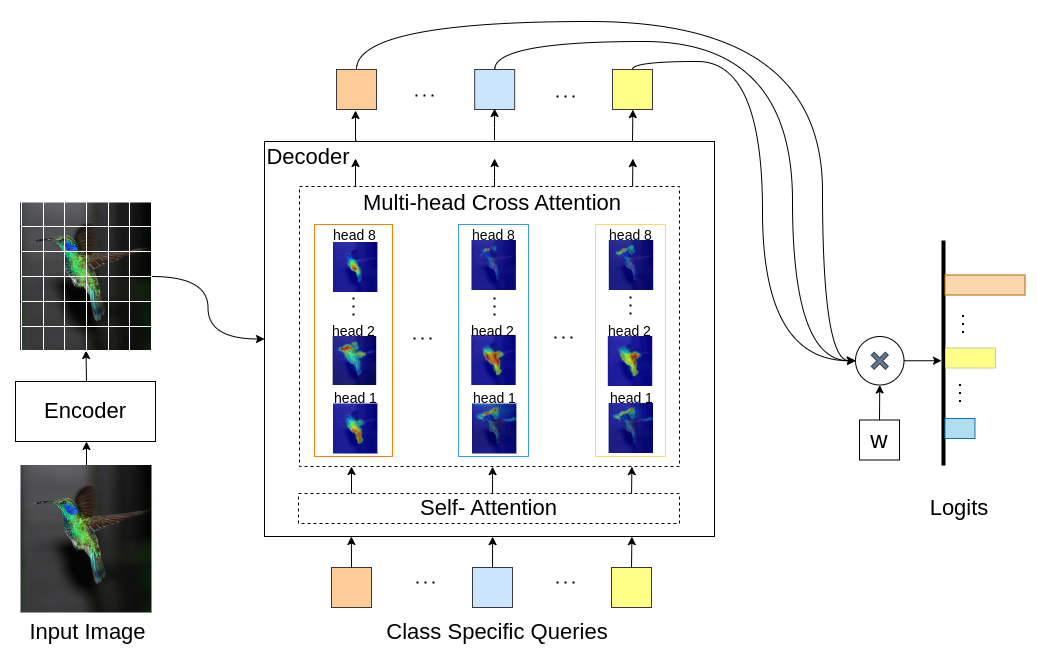
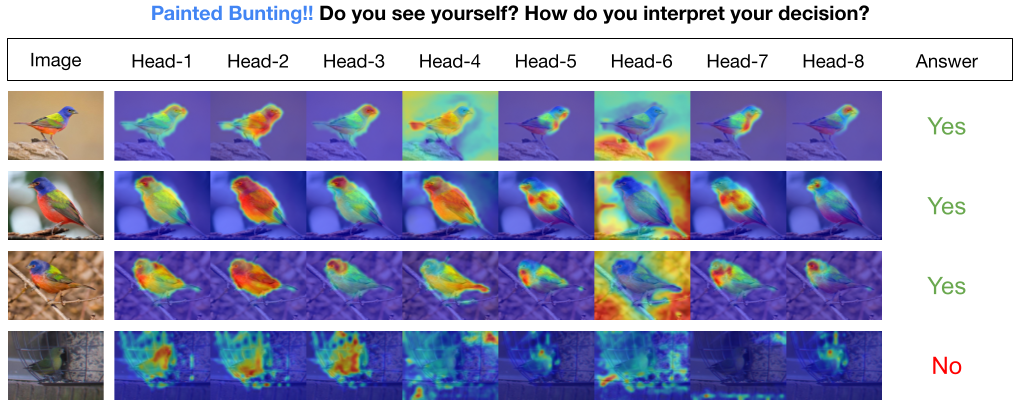
Im INTR-Modell ist jede Abfrage im Decoder für die Vorhersage einer Klasse verantwortlich. Eine Abfrage untersucht sich also selbst, um klassenspezifische Features aus der Feature-Map zu finden. Zuerst visualisieren wir die Feature-Map, also die Wertematrix der Transformatorarchitektur, um die wichtigen Teile des Objekts im Bild zu sehen. Um die spezifischen Merkmale zu finden, denen das Modell in der Wertematrix Aufmerksamkeit schenkt, zeigen wir die Heatmap der Aufmerksamkeit des Modells. Um externe Störungen bei der Klassifizierung zu vermeiden, verwenden wir einen gemeinsamen Gewichtsvektor für die Klassifizierung, sodass das Aufmerksamkeitsgewicht die Vorhersage des Modells erklärt.
INTR auf dem DETR-R50-Backbone, Klassifizierungsleistung und fein abgestimmte Modelle für verschiedene Datensätze.
| Datensatz | acc@1 | acc@5 | Modell |
|---|---|---|---|
| CUB | 71,8 | 89,3 | Checkpoint-Download |
| Vogel | 97,4 | 99,2 | Checkpoint-Download |
| Schmetterling | 95,0 | 98,3 | Checkpoint-Download |
Python-Umgebung erstellen (optional)
conda create -n intr python=3.8 -y
conda activate intrKlonen Sie das Repository
git clone https://github.com/dipanjyoti/INTR.git
cd INTRInstallieren Sie Python-Abhängigkeiten
pip install -r requirements.txtBefolgen Sie für die Daten das folgende Format.
datasets
├── dataset_name
│ ├── train
│ │ ├── class1
│ │ │ ├── img1.jpeg
│ │ │ ├── img2.jpeg
│ │ │ └── ...
│ │ ├── class2
│ │ │ ├── img3.jpeg
│ │ │ └── ...
│ │ └── ...
│ └── val
│ ├── class1
│ │ ├── img4.jpeg
│ │ ├── img5.jpeg
│ │ └── ...
│ ├── class2
│ │ ├── img6.jpeg
│ │ └── ...
│ └── ...
Führen Sie den folgenden Befehl aus, um die Leistung von INTR im CUB- Datensatz bei Einstellungen mit mehreren GPUs (z. B. 4 GPUs) zu bewerten. INTR-Kontrollpunkte sind unter „Modell und Ergebnisse optimieren“ verfügbar.
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 --master_port 12345 --use_env main.py --eval --resume < path/to/intr_checkpoint_cub_detr_r50.pth > --dataset_path < path/to/datasets > --dataset_name < dataset_name > Um visuelle Darstellungen der INTR-Interpretationen zu erstellen, führen Sie den unten angegebenen Befehl aus. Dieser Befehl stellt die Interpretation für eine bestimmte Klasse mit dem Index <class_number> dar. Standardmäßig werden Interpretationen aller Aufmerksamkeitsbereiche angezeigt. Um sich auch auf Interpretationen zu konzentrieren, die mit den Top-Abfragen mit der Bezeichnung top_q verbunden sind, legen Sie den Parameter sim_query_heads auf 1 fest. Verwenden Sie für die Visualisierung eine Batchgröße von 1.
python -m tools.visualization --eval --resume < path/to/intr_checkpoint_cub_detr_r50.pth > --dataset_path < path/to/datasets > --dataset_name < dataset_name > --class_index < class_number >Einzelbildvorhersage und -visualisierung zur Inferenzzeit: Wir haben auch ein Jupyter-Notizbuch, demo.ipynb, bereitgestellt, das für die Einzelbildvorhersage und -visualisierung während des Inferenzprozesses entwickelt wurde. Bitte beachten Sie, dass sich die Demo auf den CUB-Datensatz konzentriert.
Um INTR auf das Training vorzubereiten, verwenden Sie das vorab trainierte Modell DETR-R50. Um für einen bestimmten Datensatz zu trainieren, ändern Sie „--num_queries“, indem Sie ihn auf die Anzahl der Klassen im Datensatz festlegen. Innerhalb der INTR-Architektur wird jeder Abfrage im Decoder die Aufgabe zugewiesen, klassenspezifische Merkmale zu erfassen, wodurch jede Abfrage durch den Lernprozess angepasst werden kann. Folglich wächst die Gesamtzahl der Modellparameter proportional zur Anzahl der Klassen im Datensatz. Um INTR auf einem Multi-GPU-System (z. B. 4 GPUs) zu trainieren, führen Sie den folgenden Befehl aus.
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 --master_port 12345 --use_env main.py --finetune < path/to/detr-r50-e632da11.pth > --dataset_path < path/to/datasets > --dataset_name < dataset_name > --num_queries < num_of_classes > Unser Modell ist von der DEtection TRansformer (DETR)-Methode inspiriert.
Wir danken den Autoren von DETR für ihre großartige Arbeit.
Wenn Sie unsere Arbeit für Ihre Recherche hilfreich finden, denken Sie bitte darüber nach, den BibTeX-Eintrag zu zitieren.
@inproceedings{paul2024simple,
title={A Simple Interpretable Transformer for Fine-Grained Image Classification and Analysis},
author={Paul, Dipanjyoti and Chowdhury, Arpita and Xiong, Xinqi and Chang, Feng-Ju and Carlyn, David and Stevens, Samuel and Provost, Kaiya and Karpatne, Anuj and Carstens, Bryan and Rubenstein, Daniel and Stewart, Charles and Berger-Wolf, Tanya and Su, Yu and Chao, Wei-Lun},
booktitle={International Conference on Learning Representations},
year={2024}
}

