open_llama
1.0.0
TL;DR : Wir veröffentlichen unsere öffentliche Vorschau von OpenLLaMA, einer freizügig lizenzierten Open-Source-Reproduktion von LLaMA von Meta AI. Wir veröffentlichen eine Reihe von 3B-, 7B- und 13B-Modellen, die auf verschiedenen Datenmischungen trainiert wurden. Unsere Modellgewichte können als Ersatz für LLaMA in bestehenden Implementierungen dienen.
In diesem Repo präsentieren wir eine freizügig lizenzierte Open-Source-Reproduktion des großen Sprachmodells LLaMA von Meta AI. Wir veröffentlichen eine Reihe von 3B-, 7B- und 13B-Modellen, die auf 1T-Tokens trainiert wurden. Wir stellen PyTorch- und JAX-Gewichte vorab trainierter OpenLLaMA-Modelle sowie Bewertungsergebnisse und Vergleiche mit den ursprünglichen LLaMA-Modellen bereit. Das v2-Modell ist besser als das alte v1-Modell, das auf einer anderen Datenmischung trainiert wurde.
Wir veröffentlichen das OpenLLaMA 3Bv3-Modell, ein 3B-Modell, das für 1T-Tokens auf der gleichen Datensatzmischung wie das 7Bv2-Modell trainiert wurde.
Wir freuen uns, ein OpenLLaMA 7Bv2-Modell zu veröffentlichen, das auf einer Mischung aus verfeinerten Web-Datensätzen von Falcon, gemischt mit dem Starcoder-Datensatz, und Wikipedia, Arxiv sowie Büchern und Stackexchange von RedPajama trainiert wird.
Wir freuen uns, unsere endgültige 1T-Token-Version von OpenLLaMA 13B zu veröffentlichen. Wir haben die Bewertungsergebnisse aktualisiert. Für die aktuelle Version von OpenLLaMA-Modellen ist unser Tokenizer darauf trainiert, mehrere Leerzeichen vor der Tokenisierung zu einem zusammenzuführen, ähnlich wie der T5-Tokenizer. Aus diesem Grund funktioniert unser Tokenizer nicht mit Codegenerierungsaufgaben (z. B. HumanEval), da der Code viele Leerzeichen enthält. Für codebezogene Aufgaben verwenden Sie bitte die v2-Modelle.
Wir freuen uns, unsere endgültige 1T-Token-Version von OpenLLaMA 3B und 7B zu veröffentlichen. Wir haben die Bewertungsergebnisse aktualisiert. Wir freuen uns auch, eine 600B-Token-Vorschau des 13B-Modells zu veröffentlichen, das in Zusammenarbeit mit Stability AI trainiert wurde.
Wir freuen uns, unseren 700B-Token-Checkpoint für das OpenLLaMA 7B-Modell und unseren 600B-Token-Checkpoint für das 3B-Modell freizugeben. Wir haben auch die Bewertungsergebnisse aktualisiert. Wir gehen davon aus, dass der vollständige 1T-Token-Trainingslauf Ende dieser Woche abgeschlossen sein wird.
Nachdem wir Feedback von der Community erhalten hatten, stellten wir fest, dass der Tokenizer unserer vorherigen Checkpoint-Version falsch konfiguriert war, sodass neue Zeilen nicht erhalten blieben. Um dieses Problem zu beheben, haben wir unseren Tokenizer neu trainiert und das Modelltraining neu gestartet. Wir haben mit diesem neuen Tokenizer auch einen geringeren Trainingsverlust beobachtet.
Wir veröffentlichen die Gewichte in zwei Formaten: einem EasyLM-Format zur Verwendung mit unserem EasyLM-Framework und einem PyTorch-Format zur Verwendung mit der Hugging Face-Transformer-Bibliothek. Sowohl unser Trainingsframework EasyLM als auch die Checkpoint-Gewichte sind freizügig unter der Apache 2.0-Lizenz lizenziert.
Vorschau-Checkpoints können direkt vom Hugging Face Hub geladen werden. Bitte beachten Sie, dass von der Verwendung des schnellen Tokenizers „Hugging Face“ vorerst abgeraten wird, da wir festgestellt haben, dass der automatisch konvertierte schnelle Tokenizer manchmal falsche Tokenisierungen liefert . Dies kann erreicht werden, indem die LlamaTokenizer -Klasse direkt verwendet wird oder die Option use_fast=False für die AutoTokenizer -Klasse übergeben wird. Die Verwendung finden Sie im folgenden Beispiel.
import torch
from transformers import LlamaTokenizer , LlamaForCausalLM
## v2 models
model_path = 'openlm-research/open_llama_3b_v2'
# model_path = 'openlm-research/open_llama_7b_v2'
## v1 models
# model_path = 'openlm-research/open_llama_3b'
# model_path = 'openlm-research/open_llama_7b'
# model_path = 'openlm-research/open_llama_13b'
tokenizer = LlamaTokenizer . from_pretrained ( model_path )
model = LlamaForCausalLM . from_pretrained (
model_path , torch_dtype = torch . float16 , device_map = 'auto' ,
)
prompt = 'Q: What is the largest animal? n A:'
input_ids = tokenizer ( prompt , return_tensors = "pt" ). input_ids
generation_output = model . generate (
input_ids = input_ids , max_new_tokens = 32
)
print ( tokenizer . decode ( generation_output [ 0 ]))Für eine fortgeschrittenere Nutzung folgen Sie bitte der Dokumentation zu Transformers LLaMA.
Das Modell kann mit lm-eval-harness ausgewertet werden. Aufgrund des oben erwähnten Tokenizer-Problems müssen wir jedoch die Verwendung des schnellen Tokenizers vermeiden, um die korrekten Ergebnisse zu erhalten. Dies kann erreicht werden, indem use_fast=False an diesen Teil von lm-eval-harness übergeben wird, wie im folgenden Beispiel gezeigt:
tokenizer = self . AUTO_TOKENIZER_CLASS . from_pretrained (
pretrained if tokenizer is None else tokenizer ,
revision = revision + ( "/" + subfolder if subfolder is not None else "" ),
use_fast = False
)Informationen zur Verwendung der Gewichte in unserem EasyLM-Framework finden Sie in der LLaMA-Dokumentation von EasyLM. Beachten Sie, dass unser OpenLLaMA-Tokenizer und die Gewichte im Gegensatz zum ursprünglichen LLaMA-Modell vollständig von Grund auf trainiert werden, sodass es nicht mehr erforderlich ist, den ursprünglichen LLaMA-Tokenizer und die ursprünglichen Gewichte zu erhalten.
Die v1-Modelle werden auf dem RedPajama-Datensatz trainiert. Die v2-Modelle werden auf einer Mischung aus dem verfeinerten Web-Datensatz von Falcon, dem StarCoder-Datensatz und dem Wikipedia-, Arxiv-, Buch- und Stackexchange-Teil des RedPajama-Datensatzes trainiert. Wir folgen genau den gleichen Vorverarbeitungsschritten und Trainingshyperparametern wie im ursprünglichen LLaMA-Artikel, einschließlich Modellarchitektur, Kontextlänge, Trainingsschritten, Lernratenplan und Optimierer. Der einzige Unterschied zwischen unserer Einstellung und der ursprünglichen ist der verwendete Datensatz: OpenLLaMA verwendet offene Datensätze und nicht die, die von der ursprünglichen LLaMA verwendet wurden.
Wir trainieren die Modelle auf Cloud-TPU-v4s mit EasyLM, einer JAX-basierten Trainingspipeline, die wir für das Training und die Feinabstimmung großer Sprachmodelle entwickelt haben. Wir verwenden eine Kombination aus normaler Datenparallelität und vollständig geshardter Datenparallelität (auch bekannt als ZeRO Stufe 3), um den Trainingsdurchsatz und die Speichernutzung auszugleichen. Insgesamt erreichen wir für unser 7B-Modell einen Durchsatz von über 2200 Token/Sekunde/TPU-v4-Chip. Der Trainingsverlust ist in der Abbildung unten zu sehen.
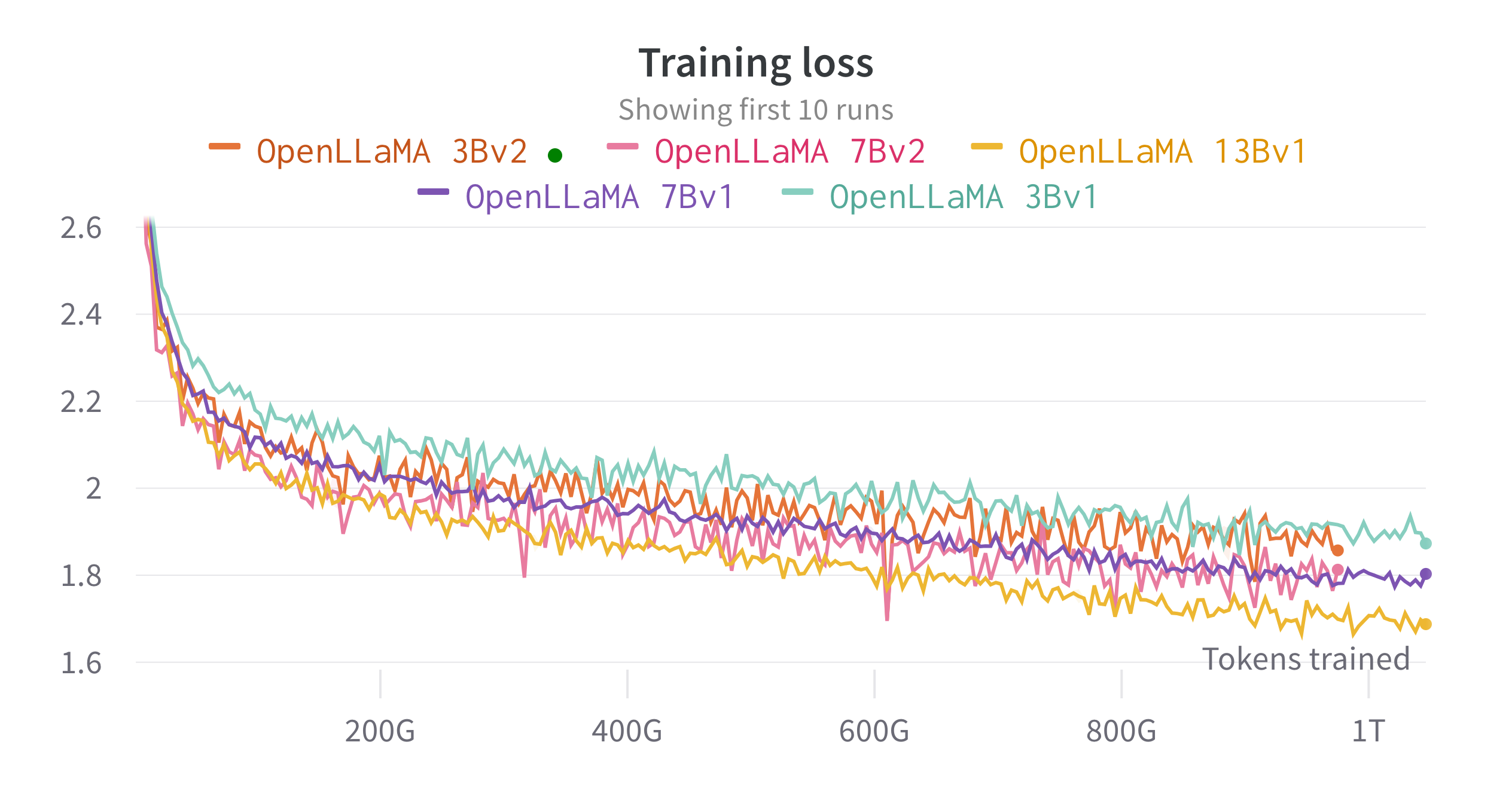
Wir haben OpenLLaMA anhand einer Vielzahl von Aufgaben mithilfe von lm-evaluation-harness evaluiert. Die LLaMA-Ergebnisse werden generiert, indem das ursprüngliche LLaMA-Modell mit denselben Bewertungsmetriken ausgeführt wird. Wir stellen fest, dass unsere Ergebnisse für das LLaMA-Modell geringfügig vom ursprünglichen LLaMA-Papier abweichen, was unserer Meinung nach auf unterschiedliche Bewertungsprotokolle zurückzuführen ist. Ähnliche Unterschiede wurden in dieser Ausgabe von lm-evaluation-harness berichtet. Darüber hinaus präsentieren wir die Ergebnisse von GPT-J, einem 6B-Parametermodell, das von EleutherAI auf dem Pile-Datensatz trainiert wurde.
Das ursprüngliche LLaMA-Modell wurde für 1 Billion Token trainiert und GPT-J wurde für 500 Milliarden Token trainiert. Die Ergebnisse stellen wir in der folgenden Tabelle dar. OpenLLaMA weist bei den meisten Aufgaben eine vergleichbare Leistung wie das ursprüngliche LLaMA und GPT-J auf und übertrifft diese bei einigen Aufgaben.
| Aufgabe/Metrik | GPT-J 6B | LLaMA 7B | LLaMA 13B | OpenLLaMA 3Bv2 | OpenLLaMA 7Bv2 | OpenLLaMA 3B | OpenLLaMA 7B | OpenLLaMA 13B |
|---|---|---|---|---|---|---|---|---|
| anli_r1/acc | 0,32 | 0,35 | 0,35 | 0,33 | 0,34 | 0,33 | 0,33 | 0,33 |
| anli_r2/acc | 0,34 | 0,34 | 0,36 | 0,36 | 0,35 | 0,32 | 0,36 | 0,33 |
| anli_r3/acc | 0,35 | 0,37 | 0,39 | 0,38 | 0,39 | 0,35 | 0,38 | 0,40 |
| arc_challenge/acc | 0,34 | 0,39 | 0,44 | 0,34 | 0,39 | 0,34 | 0,37 | 0,41 |
| arc_challenge/acc_norm | 0,37 | 0,41 | 0,44 | 0,36 | 0,41 | 0,37 | 0,38 | 0,44 |
| arc_easy/acc | 0,67 | 0,68 | 0,75 | 0,68 | 0,73 | 0,69 | 0,72 | 0,75 |
| arc_easy/acc_norm | 0,62 | 0,52 | 0,59 | 0,63 | 0,70 | 0,65 | 0,68 | 0,70 |
| boolq/acc | 0,66 | 0,75 | 0,71 | 0,66 | 0,72 | 0,68 | 0,71 | 0,75 |
| hellaswag/acc | 0,50 | 0,56 | 0,59 | 0,52 | 0,56 | 0,49 | 0,53 | 0,56 |
| hellaswag/acc_norm | 0,66 | 0,73 | 0,76 | 0,70 | 0,75 | 0,67 | 0,72 | 0,76 |
| openbookqa/acc | 0,29 | 0,29 | 0,31 | 0,26 | 0,30 | 0,27 | 0,30 | 0,31 |
| openbookqa/acc_norm | 0,38 | 0,41 | 0,42 | 0,38 | 0,41 | 0,40 | 0,40 | 0,43 |
| piqa/acc | 0,75 | 0,78 | 0,79 | 0,77 | 0,79 | 0,75 | 0,76 | 0,77 |
| piqa/acc_norm | 0,76 | 0,78 | 0,79 | 0,78 | 0,80 | 0,76 | 0,77 | 0,79 |
| Rekord/em | 0,88 | 0,91 | 0,92 | 0,87 | 0,89 | 0,88 | 0,89 | 0,91 |
| Aufnahme/f1 | 0,89 | 0,91 | 0,92 | 0,88 | 0,89 | 0,89 | 0,90 | 0,91 |
| rte/acc | 0,54 | 0,56 | 0,69 | 0,55 | 0,57 | 0,58 | 0,60 | 0,64 |
| trueqa_mc/mc1 | 0,20 | 0,21 | 0,25 | 0,22 | 0,23 | 0,22 | 0,23 | 0,25 |
| trueqa_mc/mc2 | 0,36 | 0,34 | 0,40 | 0,35 | 0,35 | 0,35 | 0,35 | 0,38 |
| wic/acc | 0,50 | 0,50 | 0,50 | 0,50 | 0,50 | 0,48 | 0,51 | 0,47 |
| Winogrande/Acc | 0,64 | 0,68 | 0,70 | 0,63 | 0,66 | 0,62 | 0,67 | 0,70 |
| Durchschnitt | 0,52 | 0,55 | 0,57 | 0,53 | 0,56 | 0,53 | 0,55 | 0,57 |
Wir haben die Aufgaben CB und WSC aus unserem Benchmark entfernt, da unser Modell bei diesen beiden Aufgaben verdächtig gut abschneidet. Wir gehen davon aus, dass es im Trainingssatz zu einer Verunreinigung der Benchmark-Daten kommen könnte.
Wir würden uns über Feedback aus der Community freuen. Wenn Sie Fragen haben, eröffnen Sie bitte ein Problem oder kontaktieren Sie uns.
OpenLLaMA wird entwickelt von: Xinyang Geng* und Hao Liu* von Berkeley AI Research. *Gleicher Beitrag
Wir danken dem Google TPU Research Cloud-Programm für die Bereitstellung eines Teils der Rechenressourcen. Wir möchten insbesondere Jonathan Caton von TPU Research Cloud dafür danken, dass er uns bei der Organisation von Rechenressourcen geholfen hat, Rafi Witten vom Google Cloud-Team und James Bradbury vom Google JAX-Team für die Unterstützung bei der Optimierung unseres Trainingsdurchsatzes. Wir möchten uns auch bei Charlie Snell, Gautier Izacard, Eric Wallace, Lianmin Zheng und unserer Benutzergemeinschaft für die Diskussionen und das Feedback bedanken.
Das OpenLLaMA 13B v1-Modell wird in Zusammenarbeit mit Stability AI trainiert, und wir danken Stability AI für die Bereitstellung der Rechenressourcen. Wir möchten uns insbesondere bei David Ha und Shivanshu Purohit für die Koordination der Logistik und die technische Unterstützung bedanken.
Wenn Sie OpenLLaMA für Ihre Forschung oder Anwendungen nützlich fanden, zitieren Sie bitte mit dem folgenden BibTeX:
@software{openlm2023openllama,
author = {Geng, Xinyang and Liu, Hao},
title = {OpenLLaMA: An Open Reproduction of LLaMA},
month = May,
year = 2023,
url = {https://github.com/openlm-research/open_llama}
}
@software{together2023redpajama,
author = {Together Computer},
title = {RedPajama-Data: An Open Source Recipe to Reproduce LLaMA training dataset},
month = April,
year = 2023,
url = {https://github.com/togethercomputer/RedPajama-Data}
}
@article{touvron2023llama,
title={Llama: Open and efficient foundation language models},
author={Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth{'e}e and Rozi{`e}re, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and others},
journal={arXiv preprint arXiv:2302.13971},
year={2023}
}


