gptty
0.2.7
ChatGPT-Wrapper in Ihrem TTY
Notiz
Diese Version unterstützt gpt4 und gpt4-turbo!
gptty ist eine ChatGPT-Shell-Schnittstelle, die es Ihnen ermöglicht, (1) mit ChatGPT auf ähnliche Weise wie mit der Webanwendung zu interagieren, ohne sich jedoch auf die Stabilität der Webanwendung verlassen zu müssen; (2) Behalten Sie den Kontext über Chat-Sitzungen hinweg bei und strukturieren Sie Ihre Gespräche nach Ihren Wünschen. (3) Speichern Sie lokale Kopien Ihrer Gespräche, damit Sie sie leichter nachschlagen können.
Vielleicht sind Sie ein Systemadministrator und konfigurieren einen Webserver für Ihren Arbeitgeber. Sie greifen über eine physische Schnittstelle auf das System zu, mit Internetverbindung, aber ohne Desktop-Umgebung oder grafische Benutzeroberfläche. Während der Konfiguration des Webservers erhalten Sie eine unerklärliche Fehlermeldung, die Sie in eine Datei umleiten, möchten sich aber nicht mühsam umsehen, um sie mit einem Browser auf ein anderes System zu kopieren, damit Sie den Fehler nachschlagen können. Stattdessen installieren Sie gptty und leiten den Fehler mit Befehlen wie gptty query --tag error --question "$(cat app.error | tr 'n' ' ')" an den Chat-Client weiter (wodurch Zeilenumbrüche entfernt werden). für Sie) oder cat app.error | xargs -d 'n' -I {} gptty query --tag error --question "{}" (wobei davon ausgegangen wird, dass sich Ihr Fehler nur über eine einzelne Zeile erstreckt).
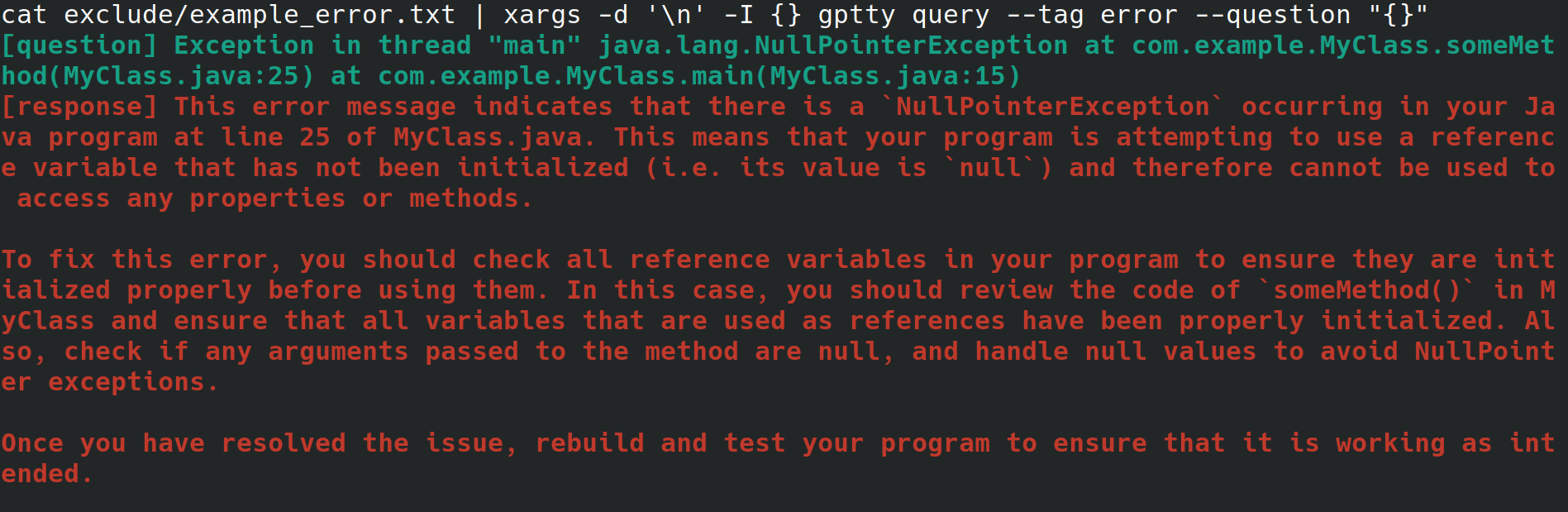
Alternativ sind Sie ein Softwareentwickler oder Datenwissenschaftler, der Daten über ChatGPT weiterleiten möchte, für diese Anfragen jedoch eine hochabstrakte API verwenden möchte, anstatt sich eingehend mit der OpenAI-API und ihren verschiedenen sprachspezifischen Wrappern vertraut zu machen. Wenn Sie Ihre Codebasis aktualisieren möchten, um ein anderes Modell zu verwenden, möchten Sie in der Lage sein, nur eine einzelne Konfigurationsdatei zu ändern und zu erwarten, dass das Abfrageantwortformat über verschiedene Modelle hinweg konsistent bleibt.
Oder vielleicht sind Sie ein Enthusiast, der lokale Kopien seiner Gespräche aufbewahren möchte oder eine direktere Kontrolle über die Kategorisierungsmethoden ausüben möchte, die Sie für diese Gespräche verwenden.
OpenAI stellt über seine API eine Reihe von Modellen zur Verfügung. [1] Derzeit unterstützt gptty Completions (davinci, curie) und ChatCompletions (gpt-3.5-turbo, gpt-4). Sie müssen lediglich den Modellnamen in Ihrer Konfiguration angeben (Standard ist text-davinci-003), und die Anwendung erledigt den Rest.
Sie können gptty auf pip installieren:
pip install gptty
Sie können auch von Git aus installieren:
cd ~/Code # replace this with whatever directory you want to use
git clone https://github.com/signebedi/gptty.git
cd gptty/
# now install the requirements
python3 -m venv venv
source venv/bin/activate
pip install -e .
Jetzt können Sie überprüfen, ob es funktioniert, indem Sie gptty --help ausführen. Wenn ein Fehler auftritt, versuchen Sie, die App zu konfigurieren.
gptty liest Konfigurationseinstellungen aus einer Datei mit dem Namen gptty.ini , von der die App erwartet, dass sie sich in demselben Verzeichnis befindet, in dem Sie gptty ausführen, es sei denn, Sie übergeben eine benutzerdefinierte config_file . Die Datei verwendet das INI-Dateiformat, das aus Abschnitten mit jeweils eigenen Schlüssel-Wert-Paaren besteht.
| Schlüssel | Typ | Standardwert | Beschreibung |
|---|---|---|---|
| api_key | Zeichenfolge | „“ | Ihr API-Schlüssel für den GPT-Dienst von OpenAI |
| org_id | Zeichenfolge | „“ | Ihre Organisations-ID für den GPT-Dienst von OpenAI |
| Ihr Name | Zeichenfolge | "Frage" | Der Name der Eingabeaufforderung |
| gpt_name | Zeichenfolge | "Antwort" | Der Name der generierten Antwort |
| Ausgabedatei | Zeichenfolge | „Ausgabe.txt“ | Der Name der Datei, in der die Ausgabe gespeichert wird |
| Modell | Zeichenfolge | „text-davinci-003“ | Der Name des zu verwendenden GPT-Modells |
| Temperatur | Schweben | 0,0 | Die für die Probenahme zu verwendende Temperatur |
| max_tokens | Ganze Zahl | 250 | Die maximale Anzahl an Token, die für die Antwort generiert werden sollen |
| max_context_length | Ganze Zahl | 150 | Die maximale Länge des Eingabekontexts |
| context_keywords_only | Bool | WAHR | Tokenisieren Sie Schlüsselwörter, um die API-Nutzung zu reduzieren |
| Preserve_new_lines | Bool | FALSCH | Behalten Sie die ursprüngliche Formatierung der Antwort bei |
| verify_internet_endpoint | Zeichenfolge | „google.com“ | Adresse zur Validierung der Internetverbindung |
Sie können die Einstellungen in der Konfigurationsdatei an Ihre Bedürfnisse anpassen. Wenn in der Konfigurationsdatei kein Schlüssel vorhanden ist, wird der Standardwert verwendet. Der Abschnitt [main] wird verwendet, um die Einstellungen des Programms festzulegen.
[main]
api_key =my_api_key Dieses Repository stellt eine Beispielkonfigurationsdatei assets/gptty.ini.example bereit, die Sie als Ausgangspunkt verwenden können.
Die Chat-Funktion bietet eine interaktive Chat-Schnittstelle zur Kommunikation mit ChatGPT. Sie können in Echtzeit Fragen stellen und Antworten erhalten.
Um die Chat-Oberfläche zu starten, führen Sie gptty chat aus. Sie können auch einen benutzerdefinierten Konfigurationsdateipfad angeben, indem Sie Folgendes ausführen:
gptty chat --config_path /path/to/your/gptty.ini
Innerhalb der Chat-Oberfläche können Sie Ihre Fragen oder Befehle direkt eingeben. Um die Liste der verfügbaren Befehle anzuzeigen, geben Sie :help ein. Daraufhin werden die folgenden Optionen angezeigt.
| Metabefehl | Beschreibung |
|---|---|
| :helfen | Zeigt eine Liste der verfügbaren Befehle und ihrer Beschreibungen an. |
| :aufhören | Beenden Sie ChatGPT. |
| :logs | Zeigt die aktuellen Konfigurationseinstellungen an. |
| :context[a:b] | Zeigen Sie den Kontextverlauf an und geben Sie optional einen Bereich a und b an. In Entwicklung |
Um einen Befehl zu verwenden, geben Sie ihn einfach in die Eingabeaufforderung ein und drücken Sie die Eingabetaste. Verwenden Sie beispielsweise den folgenden Befehl, um die aktuellen Konfigurationseinstellungen im Terminal anzuzeigen:
> :configs
api_key: SOME_KEY_HERE
org_id: org-SOME_CHARS_HERE
your_name: question
gpt_name: response
output_file: output.txt
model: text-davinci-003
temperature: 0.0
max_tokens: 250
max_context_length: 5000
Sie können jederzeit eine Frage in die Eingabeaufforderung eingeben und es wird eine Antwort für Sie generiert. Wenn Sie den Kontext über Abfragen hinweg teilen möchten, sehen Sie sich den Kontextabschnitt unten an.
Mit der Abfragefunktion können Sie eine einzelne oder mehrere Fragen an ChatGPT senden und die Antworten direkt in der Befehlszeile erhalten.
Um die Abfragefunktion zu verwenden, führen Sie Folgendes aus:
gptty query --question "What is the capital of France?" --question "What is the largest mammal?"
Sie können auch ein optionales Tag angeben, um Ihre Abfrage zu kategorisieren:
gptty query --question "What is the capital of France?" --tag "geography"
Bei Bedarf können Sie einen benutzerdefinierten Konfigurationsdateipfad angeben:
gptty query --config_path /path/to/your/gptty.ini --question "What is the capital of France?"
Denken Sie daran, dass gptty eine Konfigurationsdatei (standardmäßig gptty.ini) verwendet, um Einstellungen wie API-Schlüssel, Modellkonfigurationen und Ausgabedateipfade zu speichern. Stellen Sie sicher, dass Sie über eine gültige Konfigurationsdatei verfügen, bevor Sie gptty-Befehle ausführen.
Durch das Hinzufügen des Tags --verbose am Ende Ihrer Chat- und Abfragebefehle stellt die Anwendung zusätzliche Debug-Daten bereit, einschließlich Token-Zählungen für jede Anfrage. Dies kann nützlich sein, wenn Sie die API-Nutzungsraten verfolgen müssen.

Durch Hinzufügen der Option --additional_context [some_string_here] zu Ihren Abfragebefehlen fügt die Anwendung jede Zeichenfolge hinzu, die Sie als weiteren, externen Kontext für Ihre Frage übergeben.
Durch das Hinzufügen des Tags --json am Ende Ihrer Abfragebefehle überspringt die Anwendung das Schreiben von menschenlesbarem Text in stdout und schreibt die Fragen und Antworten stattdessen als JSON-Objekte wie [{"question":QUESTION_1, "response":RESPONSE_1},{"question":QUESTION_1, "response":RESPONSE_1},...] .

Durch das Hinzufügen des Tags --quiet am Ende Ihrer Abfragebefehle überspringt die Anwendung das Schreiben von Daten in stdout, schreibt aber weiterhin Antworten in die in der Anwendungskonfigurationsdatei angegebene output_file .
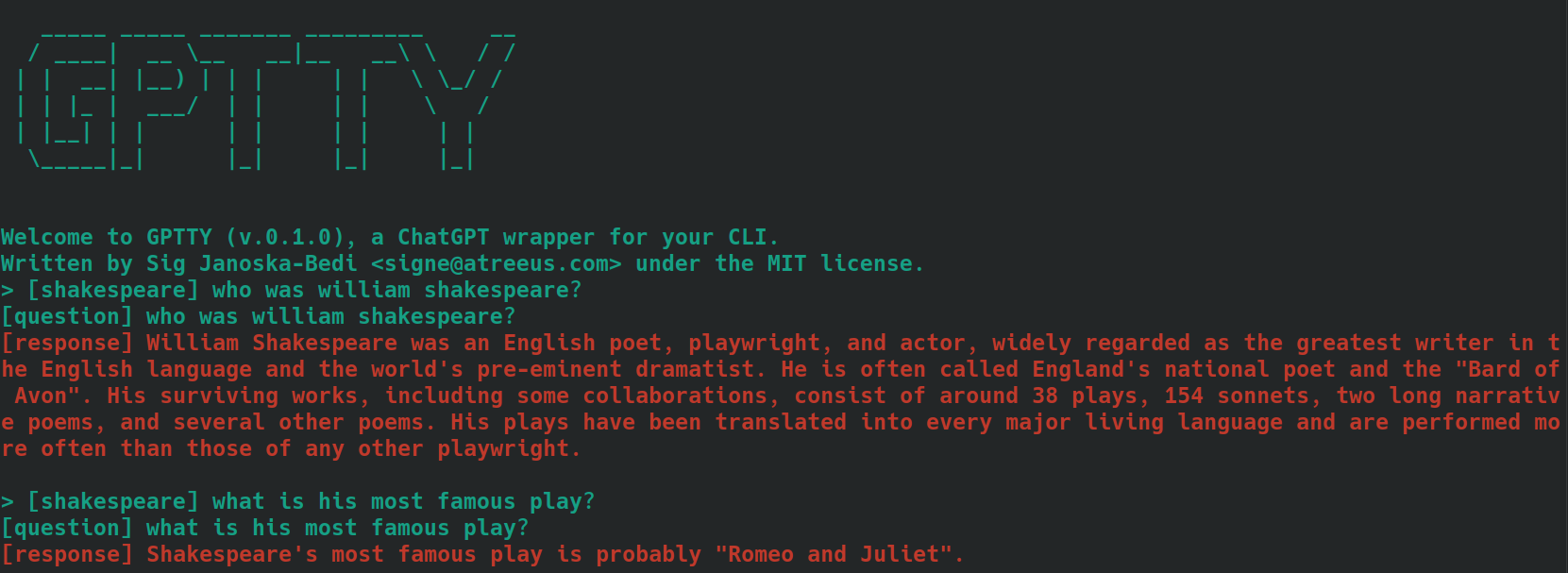
Das Markieren von Text für den Kontext bei Verwendung der chat und query Unterbefehle in dieser App kann dazu beitragen, die Genauigkeit der generierten Antworten zu verbessern. So verarbeitet die App den Kontext mit dem chat Unterbefehl:
bananas oder shakespeare .[tag] voranstellen. Wenn der Kontext Ihrer Frage beispielsweise „Kochen“ lautet, können Sie sie als [cooking] kennzeichnen. Stellen Sie sicher, dass Sie für alle zugehörigen Abfragen konsistent dasselbe Tag verwenden. Hier ist ein Beispiel dafür, wie dies aussehen könnte, wobei Fragen mit dem Tag [shakespeare] verwendet werden. Beachten Sie, dass in der zweiten Frage der Name „William Shakespeare“ überhaupt nicht erwähnt wird.
Wenn Sie den Unterbefehl query “ verwenden, befolgen Sie die gleichen Schritte wie oben beschrieben, aber anstatt dem Text Ihrer Fragen das gewünschte Tag voranzustellen, verwenden Sie die Option --tag , um das Tag beim Senden Ihrer Abfrage einzuschließen. Wenn der Kontext Ihrer Frage beispielsweise „Kochen“ ist, können Sie Folgendes verwenden:
gptty --question "some question" --tag cooking
Die Anwendung speichert Ihre getaggte Frage und Antwort in der in der Konfigurationsdatei angegebenen Ausgabedatei.
Sie können den Prozess des Sendens mehrerer Fragen an den Befehl gptty query mithilfe eines Bash-Skripts automatisieren. Dies kann besonders nützlich sein, wenn Sie eine Liste mit Fragen in einer Datei gespeichert haben und diese alle auf einmal bearbeiten möchten. Nehmen wir zum Beispiel an, Sie haben eine Datei questions.txt in der jede Frage in einer neuen Zeile steht, wie unten.
What are the key differences between machine learning, deep learning, and artificial intelligence?
How do I choose the best programming language for a specific project or task?
Can you recommend some best practices for code optimization and performance improvement?
What are the essential principles of good software design and architecture?
How do I get started with natural language processing and text analysis in Python?
What are some popular Python libraries or frameworks for building web applications?
Can you suggest some resources to learn about data visualization and its implementation in Python?
What are some important concepts in cybersecurity, and how can I apply them to my projects?
How do I ensure that my machine learning models are fair, ethical, and unbiased?
Can you recommend strategies for staying up-to-date with the latest trends and advancements in technology and programming?
Sie können jede Frage aus der Datei questions.txt an den Befehl gptty query senden, indem Sie den folgenden Bash-Einzeiler verwenden:
xargs -d ' n ' -I {} gptty query --question " {} " < questions.txt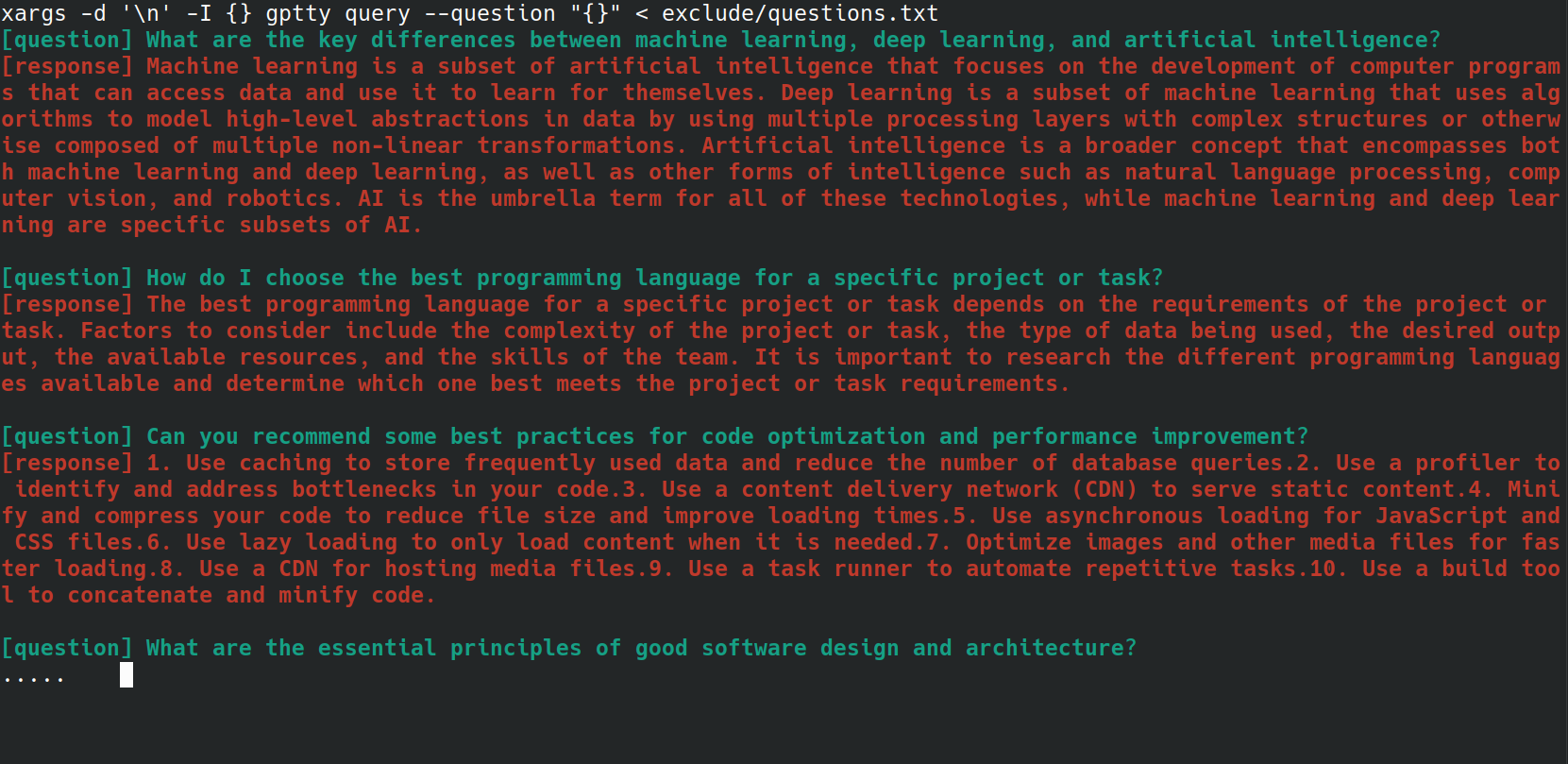
Die UniversalCompletion-Klasse bietet eine einheitliche Schnittstelle für die Interaktion mit den Sprachmodellen von OpenAI und abstrahiert (größtenteils) die Besonderheiten, ob die Anwendung den Completion- oder ChatCompletion-Modus verwendet. Die Hauptidee besteht darin, die Erstellung, Konfiguration und Verwaltung der Sprachmodelle zu erleichtern. Hier finden Sie einige Anwendungsbeispiele.
# First, import the UniversalCompletion class from the gptty library.
from gptty import UniversalCompletion
# Now, we instantiate a new UniversalCompletion object.
# The 'api_key' parameter is your OpenAI API key, which you get when you sign up for the API.
# The 'org_id' parameter is your OpenAI organization ID, which is also provided when you sign up.
g = UniversalCompletion ( api_key = "sk-SOME_CHARS_HERE" , org_id = "org-SOME_CHARS_HERE" )
# This connects to the OpenAI API using the provided API key and organization ID.
g . connect ()
# Now we specify which language model we want to use.
# Here, 'gpt-3.5-turbo' is specified, which is a version of the GPT-3 model.
g . set_model ( 'gpt-3.5-turbo' )
# This method is used to verify the model type.
# It returns a string that represents the endpoint for the current model in use.
g . validate_model_type ( g . model ) # Returns: 'v1/chat/completions'
# We send a request to the language model here.
# The prompt is a question, given in a format that the model understands.
# The model responds with a completion - an extension of the prompt based on what it has learned during training.
# The returned object is a representation of the response from the model.
g . fetch_response ( prompt = [{ "role" : "user" , "content" : "What is an abstraction?" }])
# Returns a JSON response with the assistant's message.

