Stable Diffusion End-to-End-Leitfaden – Vom Anfänger zum Experten
Ich begann mich für die Verwendung von SD zur Generierung von Bildern für militärische Anwendungen zu interessieren. Die meisten Ressourcen stammen von den NSFW-Boards von 4chan, da Anons SD verwenden, um Hentai zu erstellen. Interessanterweise verfügt die kanonische SD-WebUI über eine integrierte Funktionalität mit Anime-/Hentai-Bildtafeln ... Einer der ersten Anwendungsfälle von SD direkt nach der Generierung von Anime-Girls durch DALL-E, daher ist der Sprung zu Hentai nicht überraschend.
Wie auch immer, die Techniken dieser Verrückten sind auf eine Vielzahl von Anwendungen anwendbar, insbesondere auf LoRAs, die wie Modell-Feinabstimmungsgeräte sind. Die Idee besteht darin, mit bestimmten LoRAs (z. B. Militärfahrzeugen, Flugzeugen, Waffen usw.) zusammenzuarbeiten, um synthetische Bilddaten für das Training von Sehmodellen zu generieren. Interessant ist auch das Training neuer, nützlicher LoRAs. Zu späteren Arbeiten kann das Inpainting für Störungen gehören.
Haftungsausschluss und Quellen
Every link here may contain NSFW content, as most of the cutting-edge work on SD and LoRAs is with porn or hentai. So, please be wary when you are working with these resources. ALSO, Rentry.org pages are the main resources linked to in this guide. If any of the rentry pages do not work, change the .org to .co and the link should work. Otherwise, use the Wayback machine.
-TP
Spielen Sie damit!
Was kann man eigentlich mit SD machen? Huggingface und einige andere haben einige Apps für Sie im Browser. Spielen Sie mit ihnen herum, um die Kraft zu sehen! Was wir in diesem Handbuch tun werden, ist, die vollständige, erweiterbare WebUI zu erhalten, damit wir alles tun können, was wir wollen.
- Huggingface Text to Image SD Playground
- Dreamstudio Text-to-Image-SD-App
- Dezgo Text-to-Image-SD-App
- Huggingface Bild-zu-Bild-SD-Spielplatz
- Huggingface Inpainting Spielplatz
Inhaltsverzeichnis
- WebUI-Grundlagen
- Richten Sie die lokale GPU-Nutzung ein
- Linux-Setup
- Tiefer gehen
- Aufforderung
- NovelAI-Modell
- LoRA
- Mit Models spielen
- VAEs
- Fügen Sie alles zusammen
- Der allgemeine SD-Prozess
- Eingabeaufforderungen speichern
- txt2img-Einstellungen
- Regenerieren eines zuvor generierten Bildes
- Fehlerbehebung
- Machen Sie es sich bequem
- Testen
- WebUI Advanced
- Prompte Bearbeitung
- Xformer
- Img2Img
- Inpainting
- Extras
- Kontrollnetze
- Neue Sachen machen (WIP)
- Checkpoint-Fusion
- LoRAs trainieren
- Neue Modelle trainieren
- Google Colab-Setup (WIP)
- Mitten auf der Reise
- MJ-Parameter
- Erweiterte MJ-Eingabeaufforderungen
- DreamStudio (WIP)
- Stabile Horde (WIP)
- DreamBooth (WIP)
- Videoverbreitung (WIP)
WebUI-Grundlagen
Es ist etwas entmutigend, sich darauf einzulassen ... aber 4channers hat gute Arbeit geleistet, um dies zugänglich zu machen. Im Folgenden sind die Schritte, die ich unternommen habe, im einfachsten Sinne aufgeführt. Ihr Ziel ist es, die Stable Diffusion WebUI (erstellt mit Gradio) lokal zum Laufen zu bringen, damit Sie mit der Eingabeaufforderung und der Erstellung von Bildern beginnen können.
Richten Sie die lokale GPU-Nutzung ein
Wir werden Google Colab Pro später einrichten, damit wir SD auf jedem Gerät ausführen können, wo immer wir wollen; Aber zunächst einmal beginnen wir mit dem WebUI-Setup auf einem PC. Sie benötigen 16 GB RAM, eine GPU mit 2 GB VRAM, Windows 7+ und 20+ GB Festplattenspeicher.
- Beenden Sie die Anleitung zur Ersteinrichtung
- Ich habe dies bis Schritt 7 verfolgt, danach geht es weiter mit dem Hentai-Zeug
- Schritt 3 dauert bei durchschnittlicher Internetgeschwindigkeit 15–45 Minuten, da die Modelle jeweils über 5 GB verfügen
- Schritt 7 kann mehr als eine halbe Stunde dauern und scheint in der CLI „hängenzubleiben“.
- In Schritt 3 habe ich SD1.5 heruntergeladen, nicht die 2.x-Versionen, da 1.5 viel bessere Ergebnisse liefert
- CivitAI verfügt über alle SD-Modelle; Es ist wie HuggingFace, aber speziell für SD
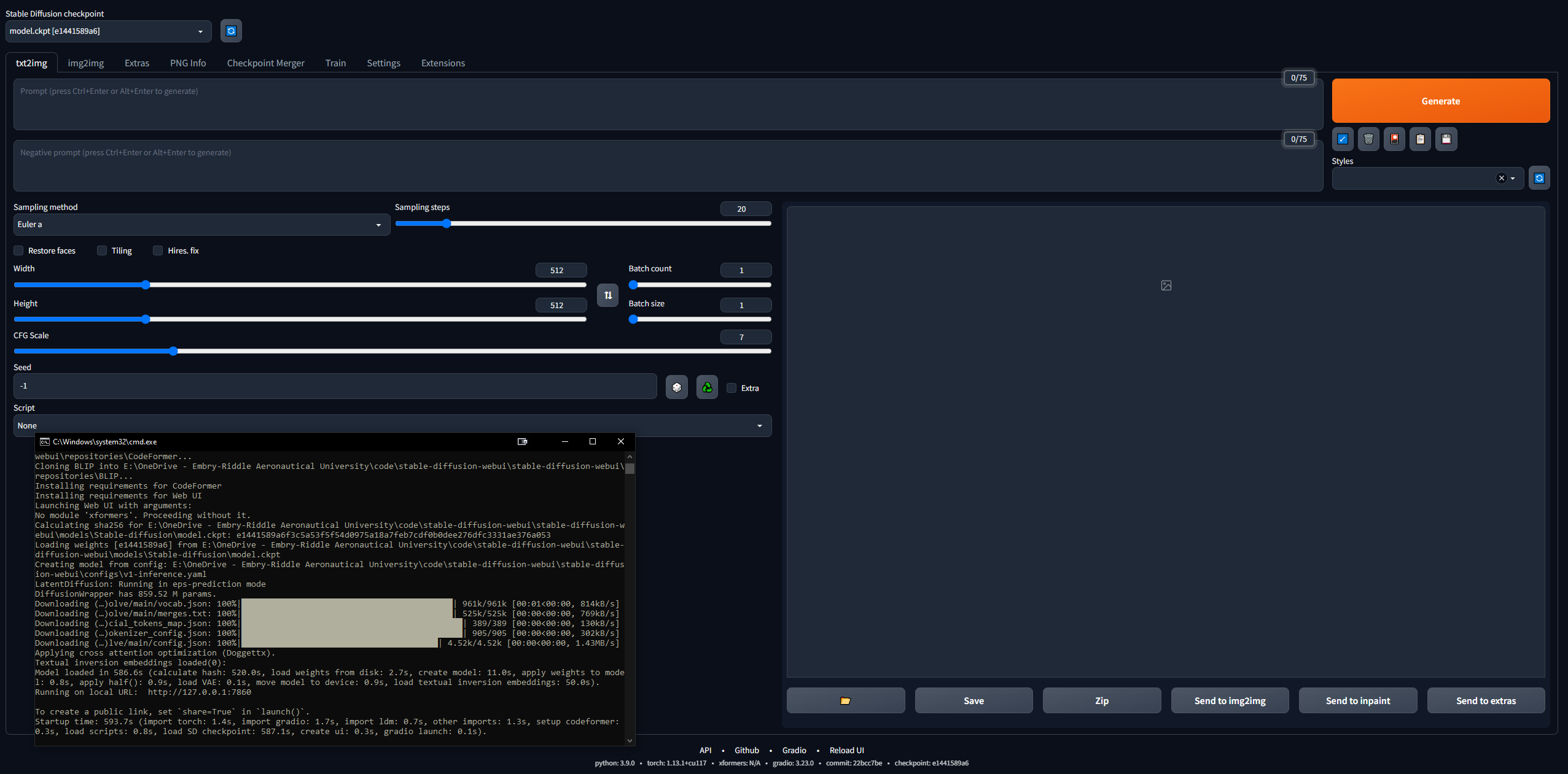
- Stellen Sie sicher, dass die WebUI funktioniert
- Kopieren Sie die URL, die die CLI ausgibt, wenn Sie fertig sind, z. B.
127.0.0.1:7860 (verwenden Sie NICHT Strg + C, da dieser Befehl die CLI schließen kann) - In den Browser einfügen und voilà; Versuchen Sie es mit einer Eingabeaufforderung und schon geht es los mit den Rennen
- Bilder werden bei der Generierung automatisch unter
stable-diffusion-webuioutputstxt2img-images<date> gespeichert
- Denken Sie daran, zum Aktualisieren einfach eine CLI im Ordner „stable-diffusion-webui“ zu öffnen und den Befehl
git pull einzugeben
Linux-Setup
Ignorieren Sie dies vollständig, wenn Sie Windows haben. Ich habe es auch geschafft, es unter Linux zum Laufen zu bringen, obwohl es etwas komplizierter ist. Ich habe damit begonnen, dieser Anleitung zu folgen, aber sie ist ziemlich dürftig geschrieben. Im Folgenden sind die Schritte aufgeführt, die ich unternommen habe, um sie unter Linux zum Laufen zu bringen. Ich habe Linux Mint 20 verwendet, eine Ubuntu 20-Distribution.
- Beginnen Sie mit dem Klonen des Webui-Repos:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git - Besorgen Sie sich ein SD-Modell (z. B. SD 1.5, wie im vorherigen Abschnitt)
- Legen Sie die Modell-CKPT-Datei in
stable-diffusion-webui/models/Stable-diffusion - Laden Sie Python herunter (falls Sie es noch nicht haben):
sudo apt install python3 python3-pip python3-virtualenv wget git - Und die WebUI ist sehr speziell, daher müssen wir Conda, einen Manager für virtuelle Umgebungen, installieren, um darin arbeiten zu können:
wget https://repo.anaconda.com/miniconda/Minconda3-latest-Linux-x86_64.sh
chmod +x Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
- Erstellen Sie nun die Umgebung:
conda create --name sdwebui python=3.10.6 - Aktivieren Sie die Umgebung:
conda activate sdwebui - Navigieren Sie zu Ihrem WebUI-Ordner und geben Sie
./webui.sh ein - Es sollte eine Weile ausgeführt werden, bis Sie eine Fehlermeldung erhalten, dass Sie nicht auf CUDA/Ihre GPU zugreifen können... das ist in Ordnung, denn es ist unser nächster Schritt
- Löschen Sie zunächst alle vorhandenen Nvidia-Treiber:
sudo apt update
sudo apt purge *nvidia*
- Befolgen Sie nun einige Teile dieser Anleitung und finden Sie heraus, über welche GPU Ihr Linux-Rechner verfügt (der einfachste Weg, dies zu tun, besteht darin, die Treiber-Manager-App zu öffnen und Ihre GPU wird aufgelistet; es gibt aber ein Dutzend Möglichkeiten, googeln Sie sie einfach).
- Gehen Sie zu dieser Seite und klicken Sie unter Linux x86_64 auf den Zweig „Neueste neue Funktion“ (bei mir war es 530.xx.xx).
- Klicken Sie auf die Registerkarte „Unterstützte Produkte“ und drücken Sie Strg + F, um Ihre GPU zu finden. Wenn es aufgeführt ist, fahren Sie fort, andernfalls gehen Sie zurück und versuchen Sie es mit „Neueste Produktionszweigversion“; Notieren Sie sich die Nummer, z. B. 530
- Geben Sie in einem Terminal Folgendes ein:
sudo add-apt-repository ppa:graphics-drivers/ppa - Aktualisieren Sie mit
sudo apt-get update - Starten Sie die Treiber-Manager-App und Sie sollten eine Liste davon sehen; Wählen Sie NICHT das empfohlene aus (z. B. nvidia-driver-530-open), wählen Sie genau das von zuvor aus (z. B. nvidia-driver-530) und übernehmen Sie die Änderungen. ODER installieren Sie es im Terminal mit
sudo apt-get install nvidia-driver-530 - AN DIESEM PUNKT sollten Sie über Ihre CLI ein Popup-Fenster zum Thema „Secure Boot“ erhalten, in dem Sie nach einem 8-stelligen Passwort gefragt werden: Legen Sie es fest und notieren Sie es
- Starten Sie Ihren PC neu und vor Ihrer Verschlüsselung/Benutzeranmeldung sollte ein BIOS-ähnlicher Bildschirm (ich schreibe dies aus dem Gedächtnis) mit der Option zur Eingabe eines MOK-Schlüssels angezeigt werden; Klicken Sie darauf und geben Sie Ihr Passwort ein, dann senden Sie es ab und starten Sie; ein paar Infos hier
- Melden Sie sich wie gewohnt an und geben Sie den Befehl
nvidia-smi ein; Bei Erfolg sollte eine Tabelle gedruckt werden. Wenn nicht, wird etwa Folgendes angezeigt: „Es konnte keine Verbindung zur GPU hergestellt werden. Bitte stellen Sie sicher, dass der aktuellste Treiber installiert ist.“ - Jetzt installieren Sie CUDA (der letzte Befehl hier sollte einige Informationen über Ihre neue CUDA-Installation ausgeben); aus dieser Anleitung:
sudo apt update
sudo apt install apt-transport-https ca-certificates gnupg
sudo apt install nvidia-cuda-toolkit
nvcc-version
- Gehen Sie nun zurück und führen Sie die Schritte 7 bis 9 aus. Wenn Sie die Meldung „FEHLER: Python venv kann nicht aktiviert werden, wird abgebrochen …“ erhalten, fahren Sie mit dem nächsten Schritt fort (andernfalls sind Sie auf dem Weg zu den Rennen und kopieren die IP-Adresse wie gewohnt von der CLI und können mit dem Spielen mit SD beginnen).
- Dieses Github-Problem enthält einige Fehlerbehebungen für dieses Venv-Problem. Bei mir hat das Laufen funktioniert
python3 -c 'import venv'
python3 -m venv venv/
Gehen Sie dann zum Ordner /stable-diffusion-webui und führen Sie Folgendes aus:
rm -rf venv/
python3 -m venv venv/
Danach hat es bei mir funktioniert.
Tiefer gehen
- Informieren Sie sich über Aufforderungstechniken, denn es gibt viel zu wissen (z. B. positive Aufforderung vs. negative Aufforderung, Stichprobenschritte, Stichprobenmethode usw.).
- OpenArt Promptbook-Leitfaden
- Definitiver SD-Eingabeleitfaden
- Eine prägnante Anleitung
- Tipps zur 4chan-Eingabeaufforderung (NSFW)
- Sammlung von Eingabeaufforderungen und Bildern
- Schritt-für-Schritt-Anleitung zur Anleitung für Anime-Mädchen
- Informieren Sie sich über SD-Wissen im Allgemeinen:
- Wegweisende stabile Diffusionspublikation
- CompVis / Stability AI Github (Heimat der ursprünglichen SD-Modelle)
- Stable Diffusion Compendium (gute externe Ressource)
- Stable Diffusion Links Hub (unglaubliche 4chan-Ressource)
- Stabile Diffusionsgoldmine
- Vereinfachtes SD Goldmine
- Zufällig/Verschiedenes. SD-Links
- FAQ (NSFW)
- Noch eine FAQ
- Treten Sie dem Stable Diffusion Discord bei
- Bleiben Sie mit den Neuigkeiten von Stable Diffsion auf dem Laufenden
- Wussten Sie, dass ab März 2023 ein Text-zu-Video-Diffusionsmodell mit 1,7 Milliarden Parametern verfügbar ist?
- Spielen Sie in der WebUI herum, spielen Sie mit verschiedenen Modellen, Einstellungen usw.
Aufforderung
Die Reihenfolge der Wörter in einer Eingabeaufforderung hat Auswirkungen: Frühere Wörter haben Vorrang. Die allgemeine Struktur einer guten Eingabeaufforderung, von hier aus:
<general positives> <descriptors of subject> <descriptors of background> <post-processing, camera, etc.>
Und ein anderer guter Leitfaden besagt, dass die Eingabeaufforderung dieser Struktur folgen sollte:
<subject> <medium> <style> <artist> <website> <resolution> <additional details> <color> <lighting>
Eine bahnbrechende Arbeit über Prompt-Engineering-txt2img-Modelle finden Sie hier. Die definitive Ressource zur LLM-Eingabeaufforderung finden Sie hier.
Was auch immer Sie verlangen, versuchen Sie, einer Struktur zu folgen, damit Ihr Prozess reproduzierbar ist. Nachfolgend sind die erforderlichen Elemente der Eingabeaufforderungssyntax aufgeführt:
- () = Modifikator x1,05
- [] = /1,05 Modifikator
- (Wort:1.05) == (Wort)
- (Wort:1.1025) == ((Wort))
- (Wort:.952) == [Wort]
- (Wort:.907) == [[Wort]]
- Mit dem Schlüsselwort AND können Sie zwei separate Eingabeaufforderungen gleichzeitig auffordern, um sie zusammenzuführen. Gut, damit die Dinge im latenten Raum nicht zusammenschlagen
- ZB:
1girl standing on grass in front of castle AND castle in background
NovelAI-Modell
Das Standardmodell ist ziemlich nett, aber wie so oft in der Geschichte treibt Sex die meisten Dinge an. NovelAI (NAI) war ein auf Animes ausgerichteter Dienst zur Generierung von SD-Inhalten und sein Hauptmodell wurde durchgesickert. Die meisten SD-generierten Bilder von Anime-Männern und -Frauen, die Sie sehen (NSFW oder nicht), stammen von diesem durchgesickerten Modell.
Auf jeden Fall ist es wirklich gut darin, Menschen zu generieren, und die meisten Modelle oder LoRAs, mit denen Sie spielen werden, sind damit kompatibel, da sie auf Anime-Bildern trainiert sind. Außerdem stellen Menschen einen wirklich guten Einstiegsanwendungsfall für die Feinabstimmung dar, welche LoRAs Sie für professionelle Zwecke verwenden möchten. Sie werden viel mit der Fehlersuche zu tun haben und die meisten Anleitungen da draußen beziehen sich auf Bilder von Frauen. Später werden wir uns mit variablen Auto-Encodern (VAEs) befassen, die dem Modell echten Realismus verleihen.
- Befolgen Sie den NovelAI Speedrun-Leitfaden
- Sie müssen das durchgesickerte Modell per Torrent herunterladen oder woanders finden
- Sobald Sie die Dateien im Ordner für die WebUI
stable-diffusion-webuimodelsStable-diffusion abgelegt und dort das Modell ausgewählt haben, sollten Sie einige Minuten warten müssen, während die CLI die VAE-Gewichte lädt- Wenn Sie hier Probleme haben, kopieren Sie die Datei config.yaml aus dem Ordner, in dem sich das Modell befand, und folgen Sie demselben Benennungsschema (wie in dieser Anleitung).
- Das ist wichtig... Erstellen Sie das Asuka-Bild exakt neu und beziehen Sie sich auf die Anleitung zur Fehlerbehebung, wenn es nicht übereinstimmt
- Finden Sie neue SD-Modelle und LoRAs
- CivitAI
- Umarmendes Gesicht
- SDG-Modelle
- SDG-Modell-Motherload (NSFW)
- SDG LoRA Motherload (NSFW)
- Viele beliebte Modelle (auch die Anleitung von früher) (NSFW)
LoRA
Low-Rank Adaptation (LoRA) ermöglicht die Feinabstimmung für ein bestimmtes Modell. Weitere Informationen zu LoRAs finden Sie hier. In der WebUI können Sie LoRAs wie das Sahnehäubchen auf einem Kuchen zu einem Modell hinzufügen. Auch das Training neuer LoRAs ist ziemlich einfach. Es gibt andere, „uralte“ Mittel zur Feinabstimmung (z. B. Textinversion und Hypernetzwerke), aber LoRAs sind der Stand der Technik.
- ZTZ99A Panzer – Militärpanzer LoRA (ein bestimmter Panzer)
- Kampfjets - Kampfjet LoRA
- epi_noiseoffset – LoRA, das Bilder zum Platzen bringt und den Kontrast erhöht
Ich werde im gesamten Leitfaden den Panzer LoRA verwenden. Bitte beachten Sie, dass dies kein sehr gutes LoRA ist, da es für Bilder im Anime-Stil gedacht ist, aber es ist gut, damit herumzuspielen.
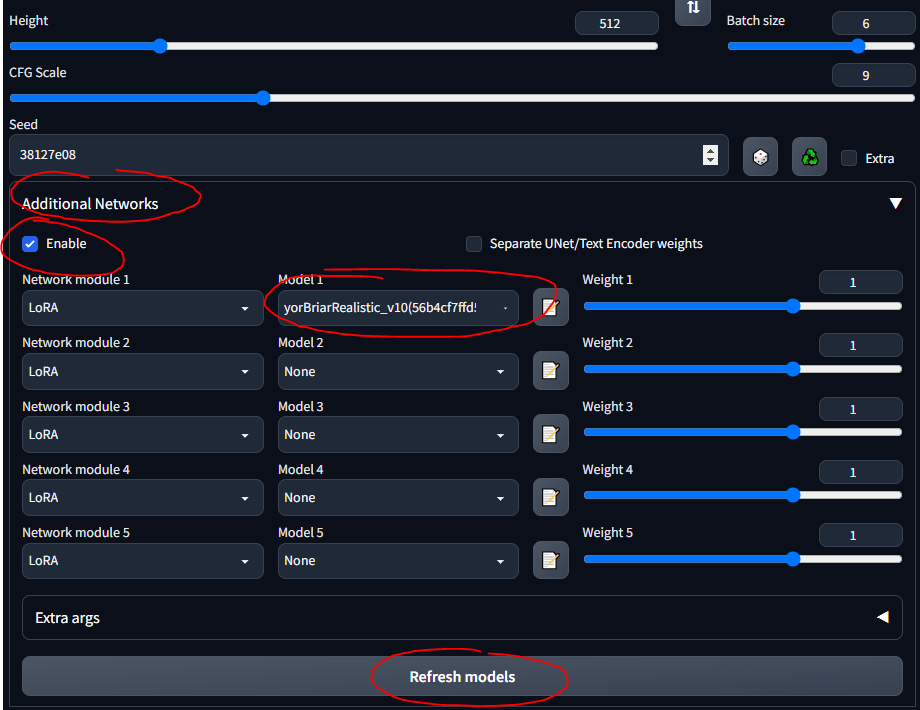
- Befolgen Sie diese Kurzanleitung, um die Erweiterung zu installieren
- Sie sollten nun einen Abschnitt „Zusätzliche Netzwerke“ in der Benutzeroberfläche sehen
- Legen Sie Ihre LoRAs in
stable-diffusion-webuiextensionssd-webui-additional-networksmodelslora - Auswählen und loslegen
- Stellen Sie sicher, dass Sie „Aktivieren“ ankreuzen.
- Seien Sie sich nur darüber im Klaren, dass jedes LoRA, das Sie herunterladen, wahrscheinlich Informationen enthält, die beschreiben, wie es zu verwenden ist ... etwa „Verwenden Sie das Schlüsselwort Tank“ oder so etwas; Stellen Sie sicher, dass Sie die Beschreibung lesen, egal wo Sie es herunterladen (z. B. CivitAI).
Mit Models spielen
Aufbauend auf dem vorherigen Abschnitt ... verschiedene Modelle haben unterschiedliche Trainingsdaten und Trainingsschlüsselwörter ... daher funktioniert die Verwendung von Booru-Tags bei einigen Modellen nicht sehr gut. Unten sind einige der Modelle, mit denen ich gespielt habe, und die „Anleitungen“ dafür.
SDG Model Motherload, das zum Abrufen der meisten Modelle verwendet wird. Ich fasse die Anweisungen hier nur zum schnellen Nachschlagen zusammen. Die meisten Models sind für echte Pornos, ich habe mich auf die realistischen konzentriert. Folgen Sie den Links, um Beispielaufforderungen, Bilder und detaillierte Hinweise zur Verwendung der einzelnen Eingabeaufforderungen anzuzeigen.
- Standard-SD-Modell (1.5, aus dem Setup-Schritt; Sie können mit den 2.x-Versionen von SD spielen, aber um ehrlich zu sein, sie sind scheiße)
- NovelAI-Modell (aus dem ersten Leitfaden)
- Anything v3 – Allzweck-Anime-Modell
- Dreamshaper – Realismus, Allzweck
- Bewusst – Realismus, Fantasie, Gemälde, Landschaften
- Neverending Dream – Realismus, Fantasie, gut für Mensch und Tier
- Verwendet das Booru-Tag-System
- Epic Diffusion – Ultrarealismus, soll das Original-SD ersetzen
- AbyssOrangeMix (AOM) – Anime, Realismus, künstlerisch, Gemälde, sehr verbreitet und gut zum Testen
- Kotosmix – Allzweck, Realismus, Anime, Landschaft, Menschen, DPM++ 2M Karras-Sampler empfohlen
CivitAI wurde verwendet, um alle anderen zu bekommen. Sie müssen ein Konto erstellen , sonst können Sie NSFW-Inhalte, einschließlich Waffen und militärische Ausrüstung, nicht sehen. Auf CivitAI enthalten einige Modelle (Kontrollpunkte) VAEs; Wenn dies der Fall ist, laden Sie es ebenfalls herunter und platzieren Sie es neben dem Modell.
- ChilloutMix – Ultrarealismus, Porträts, eines der beliebtesten
- Protogen x3.4 – Ultrarealismus
- Verwenden Sie Triggerwörter: Modelshoot-Stil, Analog-Stil, MDJRNY-V4-Stil, NoUSR-Roboter
- Traumhaftes Fotoreal 2.0 – Ultrarealismus
- Verwenden Sie das Auslösewort: fotorealistisch
- SPYBGs Toolkit für digitale Künstler – Realismus, Konzeptkunst
- Verwenden Sie Triggerwörter: tk-char, tk-env
VAEs
Variable Autoencoder sorgen dafür, dass Bilder besser, schärfer und weniger überbelichtet aussehen. Manche fixieren auch Hände und Gesichter. Aber es ist hauptsächlich eine Sache der Sättigung und Schattierung. Hier und hier erklärt (NSFW). Häufig wird das NovelAI/Anything VAE verwendet. Es ist im Grunde ein Add-on zu Ihrem Modell, genau wie ein LoRA.
Finden Sie VAEs in der VAE-Liste:
- NAI / Anything – für Anime-Modelle
- Wird standardmäßig mit dem NAI-Modell geliefert, wenn Sie es im Modellordner ablegen
- SD 1,5 – für realistische Modelle
- Laden Sie eine VAE herunter
- Befolgen Sie diesen kurzen Abschnitt der Anleitung, um VAEs in der WebUI einzurichten
- Stellen Sie sicher, dass Sie sie im
stable-diffusion-webuimodelsVAE ablegen.
- Probieren Sie die Erstellung von Bildern mit und ohne VAE aus, um die Unterschiede zu erkennen
Fügen Sie alles zusammen
Hier sind einige allgemeine Hinweise und hilfreiche Dinge, die ich dabei gelernt habe und die nicht unbedingt in den chronologischen Ablauf dieses Leitfadens passen.
Der allgemeine SD-Prozess
Eine gute Möglichkeit zum Lernen besteht darin, coole Bilder auf CivitAI, AIbooru oder anderen SD-Sites (4chan, Reddit usw.) zu durchsuchen, das zu öffnen, was Ihnen gefällt, und die Generierungsparameter in die WebUI zu kopieren. Vollständige Offenlegung: Die exakte Wiederherstellung eines Bildes ist nicht immer möglich, wie hier beschrieben. Aber im Allgemeinen kommt man ziemlich nahe heran. Um wirklich herumzuspielen, drehen Sie den CFG niedrig, damit das Modell kreativer werden kann. Probieren Sie Chargen aus und verlassen Sie den Computer, um zu den Chargen zurückzukehren, die Sie durchsuchen können.
Der allgemeine Prozess für einen WebUI-Workflow ist:
find/pick models/LoRAs -> txt2img (repeat, change params, etc.) -> img2img -> inpainting -> extra ->
- txt2img – Eingabeaufforderung und Bilder abrufen
- img2img – Bilder bearbeiten und ähnliche erstellen
- Inpainting – Teile von Bildern bearbeiten (wird später besprochen)
- Extra – letzte Bildbearbeitung (wird später besprochen)
Eingabeaufforderungen speichern
Manchmal möchten Sie zu Eingabeaufforderungen zurückkehren, ohne Bilder einzufügen oder sie von Grund auf neu zu schreiben. Sie können Eingabeaufforderungen speichern, um sie in der WebUI wiederzuverwenden.
- Schreiben Sie eine positive und/oder negative Aufforderung
- Klicken Sie unter der Schaltfläche „Generieren“ auf die Schaltfläche rechts, um Ihren „Stil“ zu speichern.
- Geben Sie einen Namen ein und speichern Sie
- Sie können es jederzeit auswählen, indem Sie auf das Dropdown-Menü „Stile“ klicken
txt2img-Einstellungen
Dieser Abschnitt ist mehr oder weniger eine Zusammenfassung der Informationen dieses Leitfadens.
- Mehr Stichprobenschritte bedeuten im Allgemeinen mehr Genauigkeit (mit Ausnahme von „a“-Samplern wie Euler a, die sich von Zeit zu Zeit ändern).
- Spielen Sie damit ein- und ausgeschaltet; Im Allgemeinen sieht es Gesichter wirklich gut aus, wenn es eingeschaltet ist
- Hochauflösend. Fix ist gut für Bilder über 512 x 512; nützlich, wenn auf einem Bild mehr als eine Person zu sehen ist
- CFG ist am besten bei niedrigen bis mittleren Werten, etwa 5–10
Regenerieren eines zuvor generierten Bildes
Um mit einem SD-generierten Image zu arbeiten, das bereits vorhanden ist; Vielleicht hat es Ihnen jemand geschickt oder Sie möchten eines nachbauen, das Sie erstellt haben:
- Gehen Sie in der WebUI zur Registerkarte PNG-Info
- Ziehen Sie das Bild, das Sie interessiert, per Drag-and-Drop in die Benutzeroberfläche
- Sie werden unter
stable-diffusion-webuioutputstxt2img-images<date> gespeichert
- Die verwendeten Parameter finden Sie rechts
- Funktioniert, weil PNGs Metadaten speichern können
- Sie können es mit der entsprechenden Schaltfläche direkt zur txt2img-Seite senden
- Möglicherweise müssen Sie hin und her prüfen, um sicherzustellen, dass Modell, VAE und andere Parameter automatisch korrekt ausgefüllt werden
Beachten Sie, dass einige Websites PNG-Metadaten entfernen, wenn Bilder hochgeladen werden (z. B. 4chan). Suchen Sie daher nach URLs zu den vollständigen Bildern oder verwenden Sie Websites, die SD-Metadaten speichern, wie CivitAI oder AIbooru.
Fehlerbehebung
Ich habe hin und wieder ein paar Fehler gemacht. Hauptsächlich Fehler wegen unzureichendem Arbeitsspeicher (VRAM), die durch Verringern der Werte einiger Parameter behoben wurden. Manchmal stellt die Wiederherstellung Gesichter und Mitarbeiter ein. Fixeinstellungen können dies verursachen. In der Datei stable-diffusion-webuiwebui-user.bat können Sie in der Zeile „ set COMMANDLINE_ARGS= einige Flags setzen, die häufige Fehler beheben.
- Bei einem NaN-Fehler, etwa im Sinne von „Ein VAE hat etwas NaN erzeugt“, fügen Sie den Parameter
--disable-nan-check hinzu - Wenn Sie jemals schwarze Bilder erhalten, fügen Sie
--no-half hinzu - Wenn Ihnen ständig der VRAM ausgeht, fügen Sie
--medvram oder für Potato-Computer --lowvram hinzu - Codeformer-Reparatur für Gesichtswiederherstellung hier (falls es nicht funktioniert, versuchen Sie zunächst, Ihr Internet zurückzusetzen)
- Das langsame Laden des Modells (beim Wechsel zu einem neuen) liegt wahrscheinlich daran, dass .safetensors-Dateien langsam geladen werden, wenn die Dinge nicht richtig konfiguriert sind. Dieser Thread diskutiert es.
Ein wirklich häufiges Problem entsteht durch eine falsche Python-Version oder Torch-Version. Sie erhalten Fehlermeldungen wie „Torch kann nicht installiert werden“ oder „Torch kann GPU nicht finden“. Die einfachste Lösung ist:
- Deinstallieren Sie alle Python-Versionen, die Sie aktualisiert haben, da die SD-WebUI 3.10.6 erwartet (ich habe 3.11.5 verwendet und den Startfehler problemlos ignoriert, aber 3.10.6 scheint am besten zu funktionieren) (Sie können bei Bedarf auch einen Versionsmanager verwenden sind weit genug fortgeschritten)
- Installieren Sie Python 3.10.6 und stellen Sie sicher, dass Sie es zu Ihrem PATH hinzufügen (sowohl Ihrem
Python Ordner als auch den Python/Scripts -Ordnern). - Löschen Sie den Ordner
venv in Ihrem Ordner stable-diffusion-webui . - Führen Sie
stable-diffusion-webuiwebui-user.bat aus und lassen Sie es das venv ordnungsgemäß neu erstellen - Genießen
Alle Kommandozeilenargumente finden Sie hier.
Machen Sie es sich bequem
Einige Erweiterungen können die Nutzung der WebUI verbessern. Holen Sie sich den Github-Link, gehen Sie zur Registerkarte „Erweiterungen“ und installieren Sie über die URL. Klicken Sie optional auf der Registerkarte „Erweiterungen“ auf „Verfügbar“ und dann auf „Laden von“. Sie können Erweiterungen lokal durchsuchen. Dies spiegelt die Erweiterungen im Github-Wiki wider.
- Tag-Vervollständiger – empfiehlt und vervollständigt Booru-Tags während der Eingabe automatisch
- Stable Diffusion Web UI State – behält den UI-Status auch nach dem Neustart bei
- Testen Sie meine Eingabeaufforderung – ein Skript, das Sie ausführen können, um einzelne Wörter aus Ihrer Eingabeaufforderung zu entfernen und zu sehen, wie sich dies auf die Bilderzeugung auswirkt
- Model-Keyword – füllt automatisch Schlüsselwörter aus, die mit einigen Modellen und LoRAs verknüpft sind, ziemlich gut gepflegt und aktuell (Stand: April 2023).
- NSFW Checker – schwärzt NSFW-Bilder; Nützlich, wenn Sie in einem Büro arbeiten, da viele gute Modelle NSFW-Inhalte zulassen und Sie diese bei der Arbeit möglicherweise nicht sehen möchten
- ACHTUNG: Diese Erweiterung kann das Inpainting oder sogar die Generierung durcheinander bringen, indem NSFW-Bilder geschwärzt werden (nicht zeitlich, stattdessen wird buchstäblich ein schwarzes Bild ausgegeben). Stellen Sie daher sicher, dass Sie sie bei Bedarf deaktivieren
- Gelbooru-Eingabeaufforderung – ruft Tags ab und erstellt mithilfe seines Hashs eine automatische Eingabeaufforderung aus jedem Gelbooru-Bild
- booru2prompt – ähnlich wie Gelbooru Prompt, aber etwas mehr Funktionalität
- Dynamic Prompting – eine Vorlagensprache für die Eingabeaufforderungsgenerierung, mit der Sie zufällige oder kombinatorische Eingabeaufforderungen ausführen können, um verschiedene Bilder zu generieren (verwendet Platzhalter)
- Hier noch mehr beschrieben
- Modell-Toolkit – beliebte Erweiterung, die Sie bei der Verwaltung, Bearbeitung und Erstellung von Modellen unterstützt
- Modellkonverter – nützlich zum Konvertieren von Modellen, Ändern von Präzisionen usw., wenn Sie Ihre eigenen Modelle trainieren
Testen
Jetzt haben Sie einige Modelle, LoRAs und Eingabeaufforderungen ... wie können Sie testen, was am besten funktioniert? Unterhalb des Bereichs „Zusätzliche Netzwerke“ befindet sich das Dropdown-Menü „Skript“. Klicken Sie hier auf X/Y/Z-Plot. Wählen Sie im X-Typ den Namen des Prüfpunkts aus. Klicken Sie in den X-Werten auf die Schaltfläche rechts, um alle Ihre Modelle einzufügen. Versuchen Sie es beim Y-Typ mit VAE oder vielleicht mit der Seed- oder CFG-Skala. Unabhängig davon, welches Attribut Sie auswählen, fügen Sie die Werte ein (oder geben Sie sie ein), die Sie grafisch darstellen möchten. Wenn Sie beispielsweise über 5 Modelle und 5 VAE verfügen, erstellen Sie ein Raster aus 25 Bildern und vergleichen die Ergebnisse jedes Modells mit den einzelnen VAE. Dies ist sehr vielseitig und kann Ihnen bei der Entscheidung helfen, was Sie verwenden möchten. Beachten Sie jedoch, dass, wenn Ihre X- oder Y-Achse Modelle von VAEs sind, die Modell- oder VAE-Gewichte für jede Kombination geladen werden müssen, was eine Weile dauern kann.
Eine wirklich gute Ressource zu SD-Vergleichen finden Sie hier (NSFW). Es gibt viele Links, denen man folgen kann. Sie können beginnen, ein Verständnis dafür zu entwickeln, wie sich die verschiedenen Modelle, VAEs, LoRAs, Parameterwerte usw. auf die Bilderzeugung auswirken.
Ich habe eine Testaufforderung von hier übernommen und den Tank LoRA verwendet, um dieses X/Y-Gitter zu erstellen. Sie können sehen, wie die verschiedenen Modelle und Sampler miteinander funktionieren. Anhand dieses Tests können wir Folgendes beurteilen:
- Die Modelle ChilloutMix, Deliberate, Dreamlike Photoreal und Epic Diffusion scheinen die „realistischsten“ Panzerbilder zu erzeugen
- In späteren unabhängigen Tests wurde festgestellt, dass der Protogen X34 Photorealism und das SpyBGs Toolkit beide auch ziemlich gut bei Panzern waren
- Die vielversprechendsten Sampler hier scheinen DPM++ SDE oder einer der Karras-Sampler zu sein.

Die genauen verwendeten Parameter (ohne Modell oder Probenehmer) für jedes dieser Tankbilder sind unten angegeben (wiederum von hier übernommen):
- Positive Aufforderung: Panzer, bf2042, beste Qualität, Meisterwerk, ultrahohe Auflösung, (fotorealistisch: 1,4), detaillierte Haut, filmische Beleuchtung, filmisch sehr detailliert, farbenfroh, modernes Foto, eine Gruppe von Soldaten auf dem Schlachtfeld, überall Explosionen auf dem Schlachtfeld, Düsenjäger und am Himmel fliegende Hubschrauber, zwei Panzer am Boden, ein Wüstengebiet, brennende Gebäude und ein verlassenes militärisches Panzerfahrzeug im Hintergrund
- Negative Eingabeaufforderung: nackt, (schlechteste Qualität:2), (niedrige Qualität:2), (normale Qualität:2), niedrige Auflösung, schlechte Anatomie, schlechte Hände, normale Qualität, ((monochrom)), ((Graustufen)), zusammengeklappt Lidschatten, mehrere Augenbrauen, rosa Haare, Löcher in den Brüsten, ng_deepnegative_v1_75t, nsfw, Brustwarzen, zusätzliche Finger, ((zusätzliche Arme)), (zusätzliche Beine), mutiert Hände, (verwachsene Finger), (zu viele Finger), (langer Hals: 1,3)
- Schritte: 22
- CFG-Skala: 7,5
- Samen: 1656460887
- Größe: 480x480
- Clip überspringen: 2
- AddNet aktiviert: True, AddNet-Modul 1: LoRA, AddNet-Modell 1: ztz99ATank_ztz99ATank(82a1a1085b2b), AddNet Weight A 1: 1, AddNet Weight B 1: 1
WebUI Advanced
In diesem Abschnitt finden Sie die fortgeschritteneren Dinge, die Sie tun können, sobald Sie mit der Verwendung von Modellen, LoRAs, VAEs, Eingabeaufforderungen, Parametern, Skripten und Erweiterungen auf der Registerkarte „txt2image“ der WebUI vertraut sind.
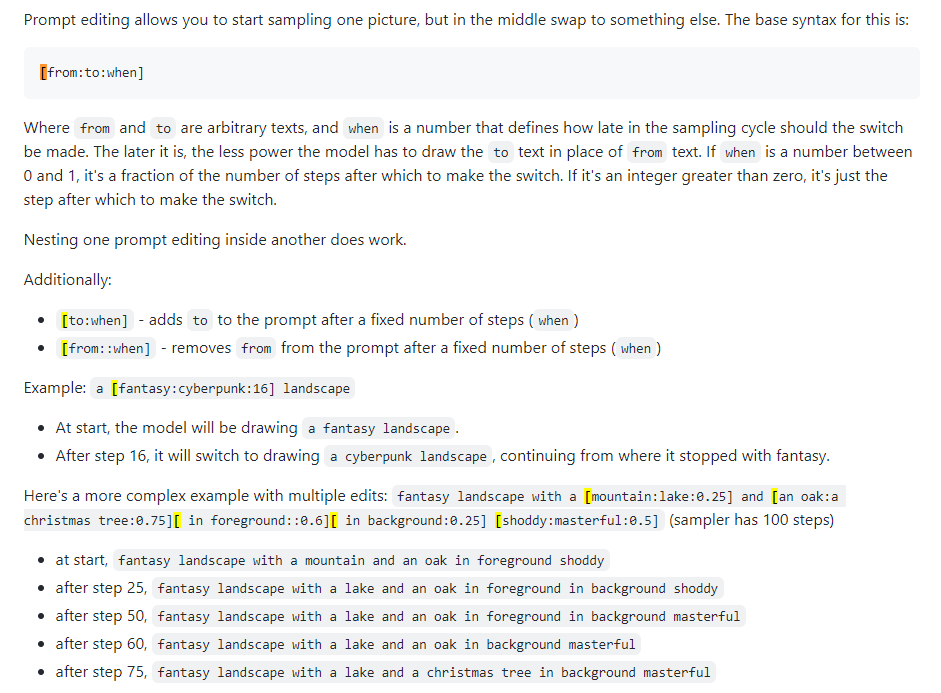
Prompte Bearbeitung
Wird auch als promptes Mischen bezeichnet. Mit der Eingabeaufforderungsbearbeitung können Sie veranlassen, dass das Modell seine Eingabeaufforderung in bestimmten Schritten ändert. Das folgende Bild stammt aus einem 4chan-Beitrag und beschreibt die Technik. Wie in diesem Handbuch beschrieben, kann die sofortige Bearbeitung beispielsweise zum Verschmelzen von Gesichtern verwendet werden.
Xformer
Xformer oder Queraufmerksamkeitsebenen. Eine Möglichkeit, die Bilderzeugung (gemessen in Sekunden/Iteration oder s/it) auf Nvidia-GPUs zu beschleunigen, senkt die VRAM-Nutzung, führt aber zu Nichtdeterminismus. Berücksichtigen Sie dies nur, wenn Sie über eine leistungsstarke GPU verfügen. Realistisch gesehen brauchen Sie einen Quadro.
img2img
Nicht gerade oft verwendet, eine Art verwirrende Registerkarte. Kann zum Generieren von Bildern anhand von Skizzen verwendet werden, wie im Huggingface Image to Image SD Playground. Diese Registerkarte verfügt über eine Unterregisterkarte, Inpainting, die Gegenstand des nächsten Abschnitts ist und eine sehr wichtige Funktion der WebUI darstellt. Während Sie diesen Abschnitt verwenden können, um geänderte Bilder zu generieren, vorausgesetzt, Sie haben sie bereits erstellt (Ausgabe an stable-diffusion-webuioutputsimg2img-images ), ist die Funktionalität für mich lückenhaft ... sie scheint wahnsinnig viel Speicher zu verbrauchen und Ich bekomme es kaum zum Laufen. Gehen Sie zum nächsten Abschnitt unten.
Inpainting
Hier liegt die Macht für den Inhaltsersteller oder jemanden, der an der Bildveränderung interessiert ist. Die Ausgabe erfolgt in stable-diffusion-webuioutputsimg2img-images .
- Anleitung zum Inpainting und Outpainting
- 4chan Inpainting (NSFW)
- Definitive Inpainting-Anleitung
- Schnappen Sie sich ein Bild, das Ihnen gefällt, aber das ist nicht perfekt, etwas stimmt nicht – es muss optimiert werden
- Oder erstellen Sie eine und klicken Sie auf „An Inpaint senden“ (alle Einstellungen werden automatisch ausgefüllt).
- Sie befinden sich jetzt im Unterregister „img2img -> inpaint“.
- Zeichnen Sie (mit der Maus) genau die Stelle auf dem Bild, die Sie ändern möchten
- Stellen Sie den Maskenmodus auf „inpaint masked“, den maskierten Inhalt auf „original“ und den Inpaint-Bereich auf „only masked“ ein.
- Schreiben Sie im Eingabeaufforderungsbereich oben die neue Eingabeaufforderung, um diese Stelle im Bild zu optimieren. Machen Sie eine negative Eingabeaufforderung, wenn Sie möchten
- Erzeugen Sie ein Bild (idealerweise einen Stapel von etwa 4 Bildern)
- Was auch immer Ihnen gefällt, klicken Sie auf „An Inpaint senden“ und wiederholen Sie den Vorgang, bis Sie ein fertiges Bild haben
Outpainting
Outpainting ist ein ziemlich komplexer semantischer Prozess. Mit Outpainting können Sie ein Bild aufnehmen und es so oft erweitern, wie Sie möchten, wodurch im Wesentlichen die Ränder vergrößert werden. Der Vorgang wird hier beschrieben. Sie erweitern das Bild jeweils nur um 64 Pixel. Dafür gibt es zwei UI-Tools (die ich finden konnte):
- Alpha Canvas (als Erweiterung/Skript in WebUI integriert)
- Hua (Web-App für Inpainting/Outpainting)
Extras
Diese WebUI-Registerkarte dient speziell der Hochskalierung. Wenn Sie ein Bild erhalten, das Ihnen wirklich gefällt, können Sie es hier am Ende Ihres Workflows hochskalieren. Hochskalierte Bilder werden in stable-diffusion-webuioutputsextras-images gespeichert. Einige der Speicherprobleme, die mit der Hochskalierung mit leistungsstärkeren Upscalern während der Generierung auf der Registerkarte „txt2img“ verbunden sind (z. B. die 4x+-Bilder), treten hier nicht auf, da Sie keine neuen Bilder generieren, sondern nur statische Bilder hochskalieren.
Kontrollnetze
Der beste Weg, um zu verstehen, was ein ControlNet tut, ist, als würde man sagen: „Inpainting auf Steroiden“. Sie geben ihm ein Eingabebild (SD-generiert oder nicht) und es kann das Ganze ändern. Mit ControlNets sind auch Posen möglich. Sie können eine Referenzpose für eine Person angeben und anhand Ihrer typischen Eingabeaufforderung entsprechende Bilder erstellen. Einen guten Einstieg in das Verständnis von ControlNets finden Sie hier.
- Installieren Sie die ControlNet-Erweiterung sd-webui-controlnet in der WebUI
- Stellen Sie sicher, dass Sie die Benutzeroberfläche neu laden, indem Sie auf der Registerkarte „Einstellungen“ auf die Schaltfläche „Benutzeroberfläche neu laden“ klicken
- Stellen Sie sicher, dass sich die Schaltfläche „ControlNet“ jetzt auf der Registerkarte „txt2img“ (und „img2img“) unter „Zusätzliche Netzwerke“ befindet (wo Sie Ihre LoRAs platzieren).
- Aktivieren Sie mehrere ControlNet-Modelle: Einstellungen -> ControlNet -> Schieberegler für mehrere ControlNet -> 2+
- Laden Sie die Benutzeroberfläche neu und im ControlNet-Bereich sollten mehrere Modellregisterkarten angezeigt werden
- Sie können ControlNets (z. B. Canny und OpenPose) kombinieren, genau wie bei der Verwendung mehrerer LoRAs
- Holen Sie sich ein ControlNet-Modell
- Bei den Canny-Modellen handelt es sich um Kantenerkennungsmodelle; Bilder werden in Schwarz-Weiß-Randbilder umgewandelt, wobei die Ränder SD ungefähr sagen, wie Ihr Bild aussehen wird
- Die OpenPose-Modelle nehmen ein Bild einer Person auf und wandeln es in ein Posenmodell zur Verwendung in späteren Bildern um
- Es gibt auch viele andere Modelle, die dort untersucht werden können
- Nehmen wir die Modelle Canny und OpenPose
- Legen Sie sie in
stable-diffusion-webuiextensionssd-webui-controlnetmodels - Holen Sie sich ein beliebiges Bild, das Sie interessiert, oder erstellen Sie ein neues. Hier verwende ich dieses Tankbild, das ich zuvor erstellt habe

- Einstellungen in txt2img: Sampling-Methode „DDIM“, Sampling-Schritte 20, Breite/Höhe wie bei Ihrem ausgewählten Bild
- Einstellungen auf der Registerkarte „ControlNet“: Aktivieren Sie „Aktivieren“, Präprozessor „Canny“, Modell „control_canny-fp16“, Leinwandbreite/-höhe wie bei Ihrem ausgewählten Bild (alle anderen Einstellungen sind Standardeinstellungen).
- Ändern Sie Ihre Eingabeaufforderungen und klicken Sie auf „Generieren“. Ich habe versucht, mein Panzerbild in eines auf dem Mars umzuwandeln

- Positiver Hinweis war: eine Szene auf dem Mars, dem Weltraum, dem Weltraum, dem Universum, ((Galaxie-Weltraumhintergrund)), Sternen, Mondbasis, futuristisch, schwarzem Hintergrund, dunklem Hintergrund, Sternen am Himmel, (Nacht) roter Sand, ((Sterne in der Hintergrund)), Panzer, bf2042, Beste Qualität, Meisterwerk, ultrahohe Auflösung, (fotorealistisch: 1,4), detaillierte Haut, filmische Beleuchtung, filmisches, sehr detailliertes, farbenfrohes, modernes Foto, eine Gruppe von Soldaten auf dem Schlachtfeld, Explosion auf dem Schlachtfeld Überall fliegen Düsenjäger und Hubschrauber am Himmel, zwei Panzer am Boden, in einer Wüstengegend, brennende Gebäude und ein verlassenes gepanzertes Militärfahrzeug im Hintergrund, Baum, Wald, Himmel
- Schnappen Sie sich ein Bild mit Personen darin und Sie können sowohl das Canny-Modell im Kontrollmodell – 0 als auch das OpenPose-Modell im Kontrollmodell – 1 erstellen, um wirklich Spaß damit zu haben
- Sehen Sie sich noch einmal dieses Video an, um mehr über Canny und OpenPose zu erfahren
Neue Sachen machen
Das ist alles schön und gut, aber manchmal braucht man für professionelle Anwendungsfälle bessere Modelle oder LoRAs. Da die meisten SD-Inhalte im wahrsten Sinne des Wortes für die Generierung von Frauen oder Pornos gedacht sind, müssen möglicherweise bestimmte Models und LoRAs geschult werden.
- Durchsuchen Sie hier alle interessanten Themen
- LoRAs trainieren
- LoRA-Zug
- Lazy LoRA-Trainingsleitfaden
- Ein guter LoRA-Trainingsleitfaden von CivitAI
- Ein weiterer LoRA-Trainingsleitfaden
- Weitere allgemeine LoRA-Informationen
- Modelle zusammenführen
- Mischmodelle
Neue Modelle trainieren
Siehe den Abschnitt über DreamBooth.
Checkpoint-Fusion
TODO
Auf der Registerkarte „Checkpoint Merger“ in der WebUI können Sie zwei Modelle miteinander kombinieren, beispielsweise zwei Soßen in einem Topf mischen, wobei das Ergebnis eine neue Soße ist, die eine Kombination aus beiden ist.
LoRAs trainieren
TODO
Das Training eines LoRA ist nicht unbedingt schwierig, es geht lediglich darum, genügend Daten zu sammeln.
Google Colab-Setup
Dies ist ein wichtiger Schritt, wenn Sie außerhalb Ihres Bohrgeräts arbeiten müssen. Google Colab Pro kostet 10 Dollar pro Monat und bietet Ihnen 89 GB RAM und Zugriff auf gute GPUs, sodass Sie technisch gesehen Eingabeaufforderungen von Ihrem Telefon aus ausführen und diese auf einem Server in Timbuktu für Sie ausführen können. Wenn Ihnen ein paar zusätzliche Kosten nichts ausmachen, ist Google Colab Pro+ für 50 Dollar pro Monat sogar noch besser.
- Gehen Sie zu diesem vorgefertigten SD Colab
- Sie können es auf Ihr GDrive klonen oder es einfach unverändert verwenden, sodass es immer auf dem aktuellsten Stand von Github ist
- Führen Sie die ersten 4 Codeblöcke aus (dauert ein wenig)
- Überspringen Sie den ControlNet-Codeblock
- Führen Sie „Start Stable-Diffusion“ aus (dauert ein wenig)
- Geben Sie Benutzername/Passwort ein, wenn Sie möchten (wahrscheinlich eine gute Idee, da Gradio öffentlich ist)
- Klicken Sie auf den Gradio-Link („Auf öffentlicher URL ausführen“).
- Verwenden Sie die WebUI wie gewohnt
- Senden Sie den Link an Ihr Telefon und Sie können unterwegs Bilder erstellen
- Um neue Modelle und LoRAs hinzuzufügen, sollten Sie neue Ordner in Ihrem Google Drive haben:
gdrive/MyDrive/sd/stable-diffusion-webui , und von diesem Basisordner aus können Sie die gleiche Ordnerstruktur verwenden, die Sie im lokalen Ordner verwendet haben WebUI- Führen Sie die Installation der LoRA-Erweiterung wie zuvor durch und die Ordnerstruktur wird automatisch ausgefüllt, genau wie auf dem Desktop
- Jetzt müssen Sie jedes Mal, wenn Sie es verwenden möchten, nur noch den Codeblock „Start Stable-Diffusion“ ausführen (nichts anderes), einen Gradio-Link erhalten und fertig
Google Colab ist immer kostenlos und Sie können es ewig nutzen, es kann jedoch etwas langsam sein. Durch ein Upgrade auf Colab Pro für 10 $/Monat erhalten Sie noch mehr Leistung. Aber Colab Pro+ für 50 $/Monat macht wirklich Spaß. Mit Pro+ können Sie Ihren Code 24 Stunden lang ausführen, auch nachdem Sie den Tab geschlossen haben.
TODO: Ich erhalte eine seltsame Fehlermeldung, die dazu führt, dass mein Pro-Abonnement nicht funktioniert, wenn ich meine Laufzeit -> Runetime-Typ-Notebook-Einstellungen auf Premium-GPU-Klasse und High-RAM einstelle. Das liegt daran, dass xFormers nicht mit CUDA-Unterstützung erstellt wurde. Dies könnte durch die Verwendung von TPUs oder die Deaktivierung von xFormern gelöst werden, aber ich habe im Moment nicht die Geduld dafür. Probieren Sie die Probleme des Colab aus.
Mitten auf der Reise
MJ ist wirklich gut für Künstler. Es ist überhaupt nicht so erweiterbar oder leistungsstark wie SD in der WebUI (NSFW ist unmöglich), aber Sie können einige ziemlich tolle Dinge generieren. Sie können es für ein paar Aufforderungen kostenlos im MJ Discord nutzen (melden Sie sich auf deren Website an) oder zahlen Sie 8 $/Monat für den Basisplan, woraufhin Sie es auf Ihrem eigenen privaten Server verwenden können. Alle Discord-Befehle finden Sie hier und hier. Die Eingabeaufforderungsstruktur für MJ lautet:
/imagine <optional image prompt> <prompt> --parameters
MJ-Parameter
Diese gelten für MJ V4, größtenteils gleich für MJ 5. Alle Modelle werden hier beschrieben.
- --ar 1.2-2.1: Seitenverhältnis, Standard ist 1:1
- --chaos 0-100: Variation in, Standard ist 0
- --no Plants: Entfernt Pflanzen
- --q 0.0-2.0: Renderqualitätszeit, Standard ist 1
- --seed: der Samen
- --stop 10-100: Job teilweise anhalten, um ein unschärferes Bild zu erzeugen
- --style 4a/4b/4c: Stil von MJ 4'
- --stylize 0-1000: Wie stark MJs Ästhetik frei bleibt, Standard ist 100
- --uplight: Verwenden Sie einen „leichten“ Upscaler, das Bild ist weniger detailliert
- --upbeta: Verwenden Sie einen Beta-Upscaler, der näher am Originalbild liegt
- --upanime: Upscaler für Anime-Bilder
- --niji: alternatives Modell für Anime-Bilder
- --hd: Verwenden Sie ein früheres Modell, das größere Bilder erzeugt, gut für Abstraktionen und Landschaften
- -Test: Verwenden Sie das spezielle MJ-Testmodell
- -Testp: Verwenden Sie das spezielle MJ-fotografische Testmodell
- -KREIS: Erzeugt nur für MJ 5 ein sich wiederholendes Bild
- -V 1/2/3/4/5: Welche MJ-Version zu verwenden (5 ist am besten)
MJ erweiterte Eingabeaufforderungen
- Sie können ein Bild (oder Bilder) in den Beginn einer Aufforderung injizieren, seinen Stil und seine Farben zu beeinflussen. Siehe diesen Doc. Laden Sie ein Bild auf Ihren Discord-Server hoch und klicken Sie mit der rechten Maustaste, um den Link zu erhalten.
- Mit Remixing können Sie Variationen eines Bildes, sich ändern, Modelle, Themen oder Medien ändern. Siehe diesen Doc.
- Multi -Eingaben können MJ zwei oder mehr separate Konzepte einzeln in Betracht ziehen. MJ-Versionen nur 1-4 und Niji. Zum Beispiel macht "Hot Dog" Bilder des Essens, "Hot :: Dog" Bilder von einem warmen Eckzahn. Sie können auch Gewichte hinzufügen. Zum Beispiel wird "Hot :: 2 Dog" Bilder von Hunden in Flammen machen. MJ 1/2/3 akzeptiert Ganzzahlgewichte, MJ 4 kann Dezimalstellen akzeptieren. Siehe diesen Doc.
- Mit Mischung können Sie 2-5 Bilder hochladen, um sie in ein neues Bild zu verschmelzen. Der Befehl /Blend wird hier beschrieben.
Dreamstudio
TODO
DreamStudio (nicht Dreambooth) ist die Flaggschiff -Plattform des Stabilitäts -KI -Unternehmens. Ihre Website ist eine Plattform, Dreambooth Studio, aus der Sie Bilder generieren können. Es liegt zwischen Midjourney und dem Webui in Bezug auf offene Funktionalität. DreamBooth Studio scheint auf der Plattform für invoke.ai gebaut zu werden, die Sie wie das Webui lokal installieren und ausführen können.
Stabile Horde
TODO
Die stabile Horde ist eine Community -Anstrengung, um für alle stabile Diffusion frei zu machen. Es funktioniert im Wesentlichen wie Torrenting oder Bitcoin -Hashing, wobei jeder einen Teil seiner GPU -Macht zur Generierung von SD -Inhalten beisteuert. Die Horde -App kann hier zugegriffen werden.
Dreambooth
TODO
Dreambooth (nicht DreamStudio) war die Implementierung einer feinabstabstabilen Diffusionsmodell-Technik von Google. Kurz gesagt: Sie können es verwenden, um Modelle mit Ihren eigenen Bildern zu trainieren. Sie können es direkt von hier oder hier verwenden. Es ist komplexer als nur das Herunterladen von Modellen und das Klicken im Webui, da Sie daran arbeiten, ein neues Modell tatsächlich zu trainieren und zu serialisieren. Einige Videos fassen zusammen, wie es geht:
- Dreambooth Easy Tutorial
- Dreambooth 10 -minütiges Training
- Webui Dreambooth -Erweiterung
Und einige gute Führer:
- Reddit Advanced Dreambooth Ratschläge
- Einfacher Traumbooth
- Dreambooth Dump (viele Informationen, durch Links scrollen)
Ein Google Colab für Dreambooth:
- Thelastben Dreambooth Training Colab (gleiche Autor wie der SD Colab, der in Google Colab Setup beschrieben wird)
Es gibt auch einen Modelltrainer namens ENGENDREAM. Ein vollständiger Vergleich zwischen Dreambooth und Everydream finden Sie hier.
Videodiffusion
TODO
Ab dem März 2023 ist es möglich, eine stabile Diffusion zu verwenden, um Videos zu generieren. Derzeit (April 2023) ist die Funktionalität eher simpel, da Videos aus ähnlichen Bildern, Frame nach Frame generiert werden, und Videos eine Art "Flipbook" -Look verleihen. Es gibt zwei primäre Erweiterungen für die Webui, die Sie verwenden können:
- Animator - einfacher
- DeForum - Mehr Funktionalität
Schrottplatz
Sachen, von denen ich nicht viel weiß, aber ich muss mich untersuchen
Es gibt einen Prozess, den Sie befolgen können, um immer wieder gute Ergebnisse zu erzielen ... dies wird im Laufe der Zeit verfeinert.
- TODO
- HIGHRES Fix, hier
- Upscaling, überall, aber meistens hier
CHATGPT -Integration?
jaint
Dall-e 2
DeForum https://deforum.github.io/


