evalgpt
1.0.0
? Dieses Projekt befindet sich noch in einem frühen Entwicklungsstadium und wir arbeiten aktiv daran. Wenn Sie Fragen oder Anregungen haben, reichen Sie bitte ein Problem oder eine PR ein.
EvalGPT ist ein Code-Interpreter-Framework, das die Leistungsfähigkeit großer Sprachmodelle wie GPT-4, CodeLlama und Claude 2 nutzt. Mit diesem leistungsstarken Tool können Benutzer Aufgaben schreiben, und EvalGPT unterstützt Sie beim Schreiben des Codes, bei der Ausführung und bei der Bereitstellung Ergebnisse.
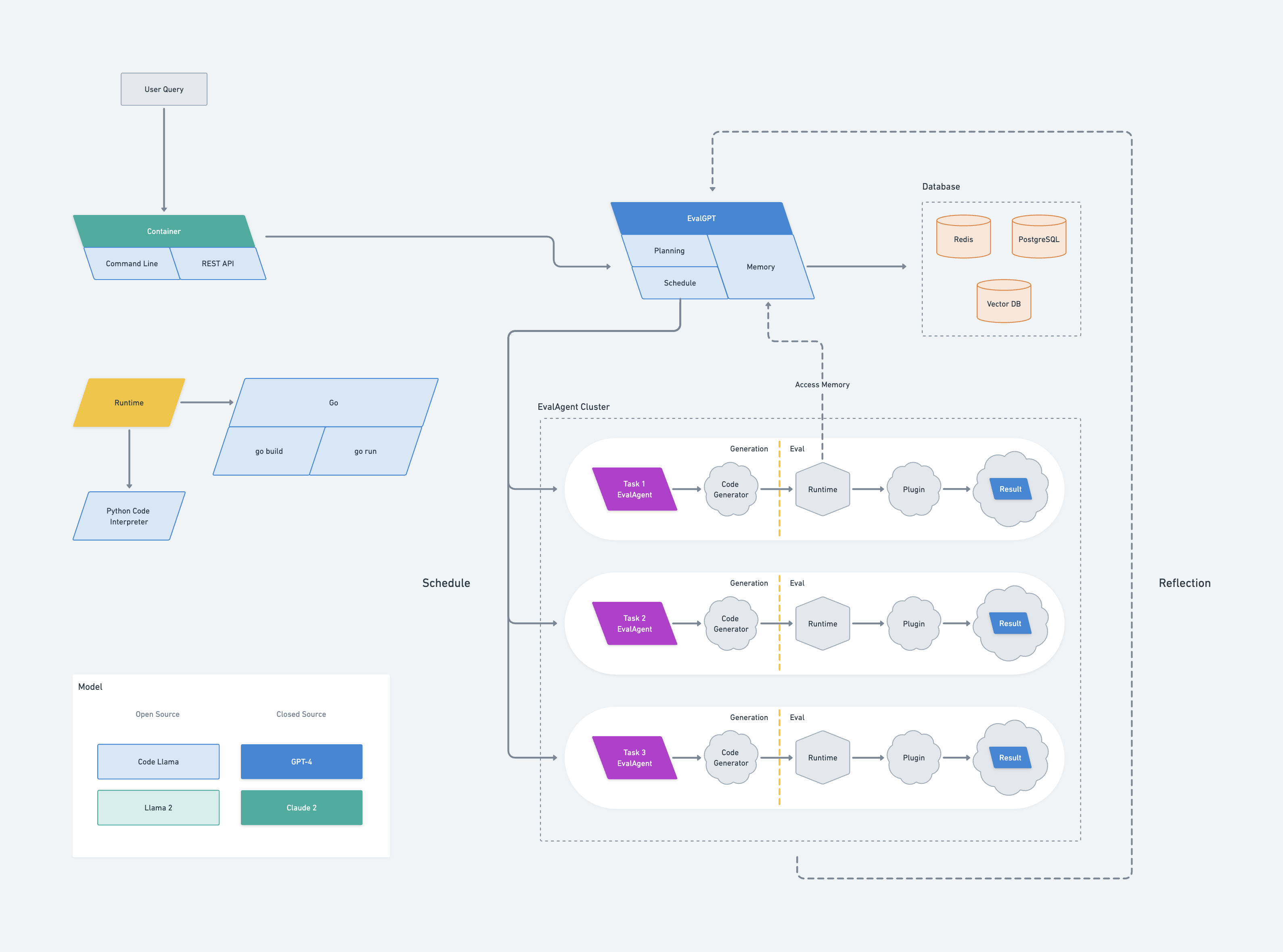
Die Architektur von EvalGPT ist vom Borg-System von Google inspiriert. Es umfasst einen Masterknoten namens EvalGPT, der aus drei Komponenten besteht: Planung, Scheduler und Speicher.
Wenn EvalGPT eine Anfrage erhält, beginnt es mit der Planung der Aufgabe mithilfe eines Large Language Model (LLM) und teilt größere Aufgaben in kleinere, überschaubare Aufgaben auf. Für jede Unteraufgabe erzeugt EvalGPT einen neuen Knoten, der als EvalAgent bekannt ist.
Jeder EvalAgent ist dafür verantwortlich, den Code basierend auf der zugewiesenen kleinen Aufgabe zu generieren. Sobald der Code generiert ist, initiiert der EvalAgent eine Laufzeit zur Ausführung des Codes und nutzt bei Bedarf sogar externe Tools. Die Ergebnisse werden dann vom EvalAgent gesammelt.
EvalAgent-Knoten können vom EvalGPT-Masterknoten auf den Speicher zugreifen, was eine effiziente und effektive Kommunikation ermöglicht. Wenn ein EvalAgent während des Prozesses auf Fehler stößt, meldet er den Fehler an den EvalGPT-Masterknoten, der dann die Aufgabe neu plant, um den Fehler zu vermeiden.
Schließlich sammelt der EvalGPT-Masterknoten alle Ergebnisse der EvalAgent-Knoten und generiert die endgültige Antwort für die Anfrage.
evalgpt installierenSie können evalgpt mit dem folgenden Befehl installieren:
go install github.com/index-labs/evalgpt@latestSie können die Installation überprüfen, indem Sie den folgenden Befehl ausführen:
evalgpt -hgit clone https://github.com/index-labs/evalgpt.git
cd evalgpt
go mod tidy && go mod vendor
mkdir -p ./bin
go build -o ./bin/evalgpt ./ * .go
./bin/evalgpt -hDann finden Sie es im bin-Verzeichnis.
Nachdem Sie die Befehlszeile von evalgpt installiert haben, müssen Sie vor der Ausführung die folgenden Optionen konfigurieren:
Konfigurieren Sie den Openai-API-Schlüssel
export OPENAI_API_KEY=sk_ ******Sie können den OpenAI-API-Schlüssel auch über Befehlsargs konfigurieren, dies wird jedoch nicht empfohlen:
evalgpt --openai-api-key sk_ ***** -q < query >
Konfigurieren Sie den Python-Interpreter
Standardmäßig verwendet der Code-Interpreter den Python-Interpreter des Systems. Sie können jedoch mit den virtuellen Umgebungstools von Python einen völlig neuen Python-Interpreter erstellen und ihn entsprechend konfigurieren.
python3 -m venv /path/evalgpt/venv
# install third python libraries
/path/evalgpt/venv/bin/pip3 install -r requirements.txt
# config python interpreter
export PYTHON_INTERPRETER=/path/evalgpt/venv/bin/python3oder
evalgpt --python-interpreter /path/evalgpt/venv/bin/python3 -q < query >Notiz:
Bevor Sie komplexe Aufgaben in Angriff nehmen, stellen Sie sicher, dass Sie die erforderlichen Python-Bibliotheken von Drittanbietern installieren. Dadurch ist Ihr Code-Interpreter für die entsprechenden Aufgaben gerüstet, was die Effizienz steigert und einen reibungslosen Betrieb gewährleistet.
Helfen
> evalgpt -h
NAME:
evalgpt help - A new cli application
USAGE:
evalgpt help [global options] command [command options] [arguments...]
DESCRIPTION:
description
COMMANDS:
help, h Shows a list of commands or help for one command
GLOBAL OPTIONS:
--openai-api-key value Openai Api Key, if you use open ai model gpt3 or gpt4, you must set this flag [ $OPENAI_API_KEY ]
--model value LLM name (default: " gpt-4-0613 " ) [ $MODEL ]
--python-interpreter value python interpreter path (default: " /usr/bin/python3 " ) [ $PYTHON_INTERPRETER ]
--verbose, -v print verbose log (default: false) [ $VERBOSE ]
--query value, -q value what you want to ask
--file value [ --file value ] the path to the file to be parsed and processed, eg. --file /tmp/a.txt --file /tmp/b.txt
--help, -h show helpNotiz:
Denken Sie daran, den OpenAI-API-Schlüssel und den Python-Interpreter zu konfigurieren, bevor Sie den Code-Interpreter ausführen. Die folgenden Beispiele wurden bereits mit Umgebungsvariablen für den OpenAI-API-Schlüssel und den Python-Interpreter konfiguriert.
Einfache Abfrage
Rufen Sie die öffentliche IP-Adresse der Maschine ab:
❯ evalgpt -q ' get the public IP of my computer '
Your public IP is: 104.28.240.133Berechnen Sie den sha256-Hash einer Zeichenfolge:
❯ evalgpt -q ' calculate the sha256 of the "hello,world" '
77df263f49123356d28a4a8715d25bf5b980beeeb503cab46ea61ac9f3320edaHolen Sie sich den Titel einer Website:
❯ evalgpt -q " get the title of a website: https://arxiv.org/abs/2302.04761 " -v
[2302.04761] Toolformer: Language Models Can Teach Themselves to Use ToolsPipeline
Sie können die Pipeline verwenden, um Kontextdaten einzugeben und diese abzufragen:
> cat a.csv
date,dau
2023-08-20,1000
2023-08-21,900
2023-08-22,1100
2023-08-23,2000
2023-08-24,1800
> cat a.csv | evalgpt -q ' calculate the average dau '
Average DAU: 1360.0Mit Dateien interagieren
Konvertieren Sie die PNG-Datei in eine WebP-Datei:
> ls
a.png
> evalgpt -q ' convert this png file to webp ' --file ./a.png
created file: a.webp
> ls
a.png a.webpZeichnen Sie ein Liniendiagramm basierend auf den Daten aus der CSV
> cat a.csv
date,dau
2023-08-20,1000
2023-08-21,900
2023-08-22,1100
2023-08-23,2000
2023-08-24,1800
> evalgpt -q ' draw a line graph based on the data from the CSV ' --file ./a.csvAusgabe:
Der EvalGPT-Masterknoten dient als Kontrollzentrum des Frameworks. Es enthält drei wichtige Komponenten: Planung, Zeitplaner und Speicher.
Die Planungskomponente nutzt große Sprachmodelle, um Aufgaben basierend auf den Anforderungen des Benutzers zu planen. Es zerlegt komplexe Aufgaben in kleinere, überschaubare Unteraufgaben, die jeweils von einem einzelnen EvalAgent-Knoten bearbeitet werden.
Die Scheduler-Komponente ist für die Aufgabenverteilung verantwortlich. Es weist jede Unteraufgabe einem EvalAgent-Knoten zu und sorgt so für eine effiziente Ressourcennutzung und parallele Ausführung von Aufgaben für optimale Leistung.
Die Speicherkomponente dient als gemeinsamer Speicherbereich für alle EvalAgent-Knoten. Es speichert die Ergebnisse ausgeführter Aufgaben und bietet eine Plattform für den Datenaustausch zwischen verschiedenen Knoten. Dieses Shared-Memory-Modell erleichtert komplexe Berechnungen und hilft bei der Fehlerbehandlung, indem es im Fehlerfall eine Neuplanung von Aufgaben ermöglicht.
Tritt während der Codeausführung ein Fehler auf, plant der Masterknoten die Aufgabe neu, um den Fehler zu vermeiden und so einen robusten und zuverlässigen Betrieb sicherzustellen.
Schließlich sammelt der EvalGPT-Masterknoten die Ergebnisse aller EvalAgent-Knoten, kompiliert sie und generiert die endgültige Antwort auf die Anfrage des Benutzers. Diese zentralisierte Steuerung und Koordination machen den EvalGPT-Masterknoten zu einem entscheidenden Bestandteil des EvalGPT-Frameworks.
EvalAgent-Knoten sind die Arbeitspferde des EvalGPT-Frameworks. Sie werden vom Masterknoten für jede Unteraufgabe erzeugt und sind für die Codegenerierung, -ausführung und Ergebniserfassung verantwortlich.
Der Codegenerierungsprozess in einem EvalAgent-Knoten richtet sich nach der ihm zugewiesenen spezifischen Aufgabe. Mithilfe des großen Sprachmodells wird der zur Erfüllung der Aufgabe erforderliche Code erstellt und sichergestellt, dass er den Anforderungen und der Komplexität der Aufgabe entspricht.
Sobald der Code generiert ist, initiiert der EvalAgent-Knoten eine Laufzeitumgebung zur Ausführung des Codes. Diese Laufzeit ist flexibel, kann bei Bedarf externe Tools integrieren und bietet eine robuste Plattform für die Codeausführung.
Während der Ausführung sammelt der EvalAgent-Knoten die Ergebnisse und kann vom EvalGPT-Masterknoten auf den gemeinsamen Speicher zugreifen. Dies ermöglicht einen effizienten Datenaustausch und erleichtert komplexe Berechnungen, die eine erhebliche Datenmanipulation oder den Zugriff auf zuvor berechnete Ergebnisse erfordern.
Treten während der Codeausführung Fehler auf, meldet der EvalAgent-Knoten diese an den EvalGPT-Masterknoten zurück. Der Masterknoten plant dann die Aufgabe neu, um den Fehler zu vermeiden und so einen robusten und zuverlässigen Betrieb sicherzustellen.
Im Wesentlichen sind EvalAgent-Knoten autonome Einheiten innerhalb des EvalGPT-Frameworks, die in der Lage sind, Code zu generieren und auszuführen, Fehler zu behandeln und Ergebnisse effizient zu kommunizieren.
Die Laufzeit von EvalGPT wird von EvalAgent-Knoten verwaltet. Jeder EvalAgent-Knoten generiert Code für eine bestimmte Aufgabe und initiiert eine Laufzeit zur Ausführung des Codes. Die Laufzeitumgebung ist flexibel und kann bei Bedarf externe Tools integrieren, wodurch ein äußerst anpassungsfähiger Ausführungskontext bereitgestellt wird.
Die Laufzeit umfasst auch Fehlerbehandlungsmechanismen. Wenn ein EvalAgent-Knoten während der Codeausführung auf Fehler stößt, meldet er diese an den EvalGPT-Masterknoten zurück. Anschließend plant der Masterknoten die Aufgabe neu, um den Fehler zu vermeiden und so eine robuste und zuverlässige Codeausführung sicherzustellen.
Die Laufzeit kann mit dem Speicher des EvalGPT-Masterknotens interagieren, was einen effizienten Datenaustausch ermöglicht und komplexe Berechnungen erleichtert. Dieses Shared-Memory-Modell ermöglicht die Ausführung von Aufgaben, die eine erhebliche Datenmanipulation oder den Zugriff auf zuvor berechnete Ergebnisse erfordern.


