llm4data
v0.0.9
LLM4Data ist eine Python-Bibliothek, die die Anwendung großer Sprachmodelle (LLMs) und künstlicher Intelligenz für Entwicklungsdaten und Wissensermittlung erleichtern soll. Es soll Benutzern und Organisationen die Möglichkeit geben, Entwicklungsdaten auf innovative Weise mithilfe natürlicher Sprache zu entdecken und mit ihnen zu interagieren.
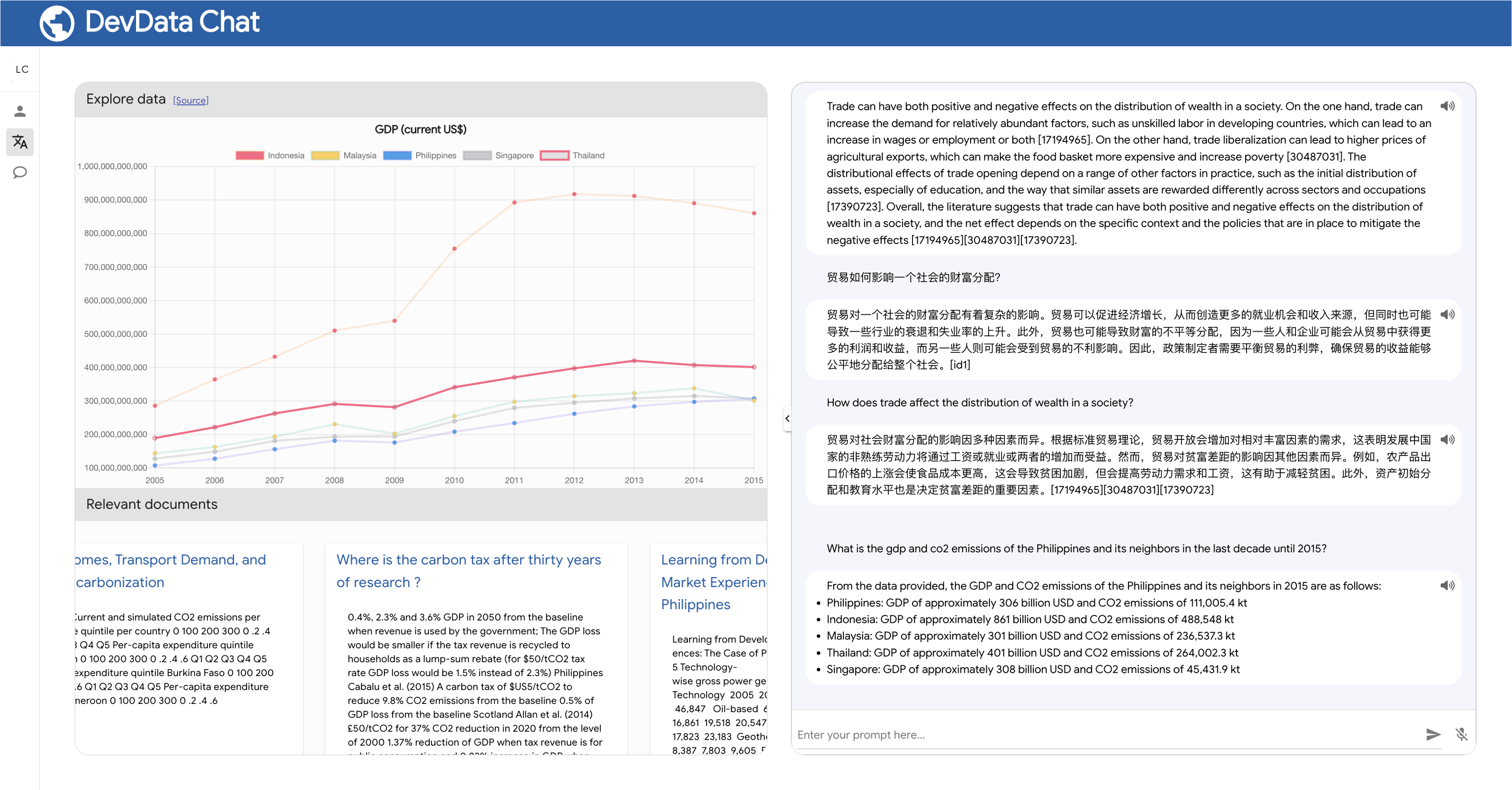
LLM4Data unterstützt die DevData-Chat-Anwendung, die bald als Open-Source-Projekt verfügbar sein wird. Diese Anwendung demonstriert die verschiedenen Möglichkeiten, wie LLM (Sprachmodell) und KI die Entdeckung und Interaktion mit Daten und Wissen verbessern und innovative Lösungen bieten, um Lücken in der Auffindbarkeit und Zugänglichkeit zu schließen.
Die LLM4Data-Bibliothek enthält eine Sammlung von Erkennungs- und Datenerweiterungslösungen für verschiedene Datentypen, darunter Dokumente, Indikatoren, Mikrodaten, Geodaten und mehr. Die aktuelle Version der Bibliothek enthält Lösungen für die WDI-Indikatoren. Weitere Lösungen werden in zukünftigen Versionen hinzugefügt.
Basierend auf vorhandenen Metadatenstandards und -schemata können Benutzer und Organisationen von LLMs profitieren, um datengesteuerte Anwendungen zu verbessern und mit LLM4Data die Verarbeitung natürlicher Sprache, die Textgenerierung und mehr zu ermöglichen. Die Bibliothek dient als Brücke zwischen LLMs und Entwicklungsdaten mithilfe von Open-Source-Bibliotheken und bietet eine nahtlose Schnittstelle zur Nutzung der Funktionen dieser leistungsstarken Sprachmodelle.
Verwenden Sie den Paketmanager pip, um LLM4Data zu installieren.
pip install llm4dataDie folgenden Beispiele zeigen, wie Sie LLM4Data verwenden, um WDI-API-URLs und SQL-Abfragen aus Eingabeaufforderungen zu generieren.
Weitere Beispiele finden Sie hier.
This example uses the OpenAI API. Before you proceed, make sure to set your API keys in the `.env` file. See the [setup instructions](https://worldbank.github.io/llm4data/notebooks/examples/getting-started/openai-api.html) for more details.
from llm4data . prompts . indicators import wdi
# Create a WDI API prompt object
wdi_api = wdi . WDIAPIPrompt ()
# Send a prompt to the LLM to get a WDI API URL relevant to the prompt
response = wdi_api . send_prompt (
"What is the gdp and the co2 emissions of the philippines and its neighbors in the last decade?"
)
# Parse the response to get the WDI API URL
wdi_api_url = wdi_api . parse_response ( response )
print ( wdi_api_url )Die Ausgabe sieht wie folgt aus:
https://api.worldbank.org/v2/country/PHL;IDN;MYS;SGP;THA;VNM/indicator/NY.GDP.MKTP.CD;EN.ATM.CO2E.KT?date=2013:2022&format=json&source=2
Beachten Sie, dass die generierte URL bereits die für die Eingabeaufforderung relevanten Ländercodes und Indikatoren enthält. Es versteht, welche Länder die Nachbarn der Philippinen sind. Es versteht auch, welche Indikatorcodes voraussichtlich die relevanten Daten für das BIP und die CO2-Emissionen liefern.
Die URL enthält auch den Datumsbereich, das Format und die Quelle der Daten. Der Benutzer kann dann die URL nach Bedarf anpassen und sie zum Abfragen der WDI-API verwenden.
Make sure you have set up your environment first. The example below requires a working database engine, e.g., postgresql. If you want to use SQLite, make sure to update the `.env` file and set the environment variables.
Die WDI-Daten können zwar in einen Pandas-Datenrahmen geladen werden, dies ist jedoch nicht immer praktisch. zum Beispiel die Entwicklung von Anwendungen, die beliebige Datenfragen beantworten können.
Die LLM4Data-Bibliothek enthält eine SQL-Schnittstelle zu WDI-Daten, die es Benutzern ermöglicht, die Daten mithilfe von SQL abzufragen.
Über diese Schnittstelle können Benutzer die Daten mithilfe von SQL abfragen und die Ergebnisse als Pandas-Datenrahmen zurückgeben. Über die Schnittstelle können Benutzer die Daten auch mithilfe von SQL abfragen und die Ergebnisse als JSON-Objekt zurückgeben.
import json
from llm4data . prompts . indicators import templates , wdi
from llm4data . llm . indicators import wdi_sql
prompt = "What is the GDP and army spending of the Philippines in 2020?"
sql_data = wdi_sql . WDISQL (). llm2sql_answer ( prompt , as_dict = True )
print ( sql_data )
# # {'sql': "SELECT country, value AS gdp, (SELECT value FROM wdi WHERE country_iso3 = 'PHL' AND indicator = 'MS.MIL.XPND.GD.ZS' AND year = 2020) AS army_spending FROM wdi WHERE country_iso3 = 'PHL' AND indicator = 'NY.GDP.MKTP.CD' AND year = 2020 AND value IS NOT NULL",
# # 'params': {},
# # 'data': {'data': [{'country': 'Philippines',
# # 'gdp': 361751116292.541,
# # 'army_spending': 1.01242392260698}],
# # 'sample': [{'country': 'Philippines',
# # 'gdp': 361751116292.541,
# # 'army_spending': 1.01242392260698}]},
# # 'num_samples': 20}Die LLM4Data-Bibliothek bietet auch Unterstützung für die Generierung narrativer Erläuterungen zu SQL-Abfrageantworten. Dies ist nützlich, um Beschreibungen von Daten in natürlicher Sprache zu erstellen, die verwendet werden können, um Benutzern Kontext bereitzustellen und die Ergebnisse von Datenabfragen zu erklären.
from llm4data . prompts . indicators import templates
# Send the prompt to the LLM for a narrative explanation of the response.
# This is optional and can be skipped.
# Note that we pass only a sample in the `context_data`.
# This could limit the quality of the response.
# This is a limitation of the current version of the LLM which is constrained by the context length and cost.
explainer = templates . IndicatorPrompt ()
description = explainer . send_prompt ( prompt = prompt , context_data = json . dumps ( sql_data [ "data" ][ "sample" ]))
print ( description [ "content" ])
# # Based on the data provided, the GDP of the Philippines in 2020 was approximately 362 billion USD. Meanwhile, the country's army spending in the same year was around 1.01 billion USD. It is worth noting that while army spending is an important aspect of a country's budget, it is not the only factor that contributes to its economic growth and development. Other factors such as infrastructure, education, and healthcare also play a crucial role in shaping a country's economy. Langchain ist eine großartige Bibliothek und verfügt über einen Wrapper für SQL-Datenbanken, mit dem Sie diese in natürlicher Sprache abfragen können. Der Wrapper heißt SQLDatabaseChain und kann wie folgt verwendet werden:
from langchain import OpenAI , SQLDatabase , SQLDatabaseChain
db = SQLDatabase . from_uri ( "sqlite:///../llm4dev/data/sqldb/wdi.db" )
llm = OpenAI ( temperature = 0 , verbose = True )
db_chain = SQLDatabaseChain . from_llm ( llm , db , verbose = True , return_intermediate_steps = True )
out = db_chain ( "What is the GDP and army spending of the Philippines in 2020?" ) > Entering new SQLDatabaseChain chain...
What is the GDP and army spending of the Philippines in 2020 ?
SQLQuery:SELECT " value " FROM wdi WHERE " name " = ' GDP (current US$) ' AND " country_iso3 " = ' PHL ' AND " year " = 2020
UNION
SELECT " value " FROM wdi WHERE " name " = ' Military expenditure (% of GDP) ' AND " country_iso3 " = ' PHL ' AND " year " = 2020
SQLResult: [(1.01242392260698,), (361751116292.541,)]
Answer:The GDP of the Philippines in 2020 was 1.01242392260698 and the military expenditure (% of GDP) was 361751116292.541.
> Finished chain. Leider betrug die Antwort: The GDP of the Philippines in 2020 was 1.01242392260698 and the military expenditure (% of GDP) was 361751116292.541. ist falsch, da die Werte vertauscht wurden.
Eines der Ziele von LLM4Data ist die Entwicklung von Lösungen rund um die Einschränkungen bestehender Open-Source-Lösungen bei der Anwendung auf Entwicklungsdaten und Wissensentdeckung.
Pull-Anfragen sind willkommen. Bei größeren Änderungen öffnen Sie bitte zunächst ein Problem, um zu besprechen, was Sie ändern möchten.
Weitere Informationen finden Sie unter CONTRIBUTING.md.
LLM4Data ist unter dem World Bank Master Community License Agreement lizenziert.


