Machine Learning Guide
1.0.0
Hinweis: Mit dieser praktischen Erweiterung „Markdown PDF“ können Sie diese Markdown-Datei ganz einfach in VSCode in eine PDF-Datei konvertieren.

Frameworks für maschinelles Lernen/Deep Learning.
Lernressourcen für ML
ML-Frameworks, Bibliotheken und Tools
Algorithmen
PyTorch-Entwicklung
TensorFlow-Entwicklung
Kern-ML-Entwicklung
Deep-Learning-Entwicklung
Verstärkung des Lernens
Entwicklung von Computer Vision
Entwicklung der Verarbeitung natürlicher Sprache (NLP).
Bioinformatik
CUDA-Entwicklung
MATLAB-Entwicklung
C/C++-Entwicklung
Java-Entwicklung
Python-Entwicklung
Scala-Entwicklung
R-Entwicklung
Julia-Entwicklung
Zurück nach oben
Maschinelles Lernen ist ein Zweig der künstlichen Intelligenz (KI), der sich auf die Entwicklung von Apps mithilfe von Algorithmen konzentriert, die aus Datenmodellen lernen und ihre Genauigkeit im Laufe der Zeit verbessern, ohne dass sie programmiert werden müssen.

Zurück nach oben
Best Practices für die Verarbeitung natürlicher Sprache (NLP) von Microsoft
Das Kochbuch zum autonomen Fahren von Microsoft
Azure Machine Learning – ML as a Service | Microsoft Azure
So führen Sie Jupyter Notebooks in Ihrem Azure Machine Learning-Arbeitsbereich aus
Maschinelles Lernen und künstliche Intelligenz | Amazon Web Services
Planen von Jupyter-Notebooks auf kurzlebigen Amazon SageMaker-Instanzen
KI und maschinelles Lernen | Google Cloud
Verwendung von Jupyter Notebooks mit Apache Spark in Google Cloud
Maschinelles Lernen | Apple-Entwickler
Künstliche Intelligenz und Autopilot | Tesla
Meta-KI-Tools | Facebook
PyTorch-Tutorials
TensorFlow-Tutorials
JupyterLab
Stabile Diffusion mit Core ML auf Apple Silicon
Zurück nach oben
Maschinelles Lernen von der Stanford University von Andrew Ng | Coursera
AWS-Schulung und Zertifizierung für Kurse zum maschinellen Lernen (ML).
Stipendienprogramm für maschinelles Lernen für Microsoft Azure | Udacity
Microsoft-zertifiziert: Azure Data Scientist Associate
Microsoft-zertifiziert: Azure AI Engineer Associate
Schulung und Bereitstellung von Azure Machine Learning
Lernen Sie maschinelles Lernen und künstliche Intelligenz von Google Cloud Training
Crashkurs zum maschinellen Lernen für Google Cloud
Online-Kurse zum maschinellen Lernen | Udemy
Online-Kurse zum maschinellen Lernen | Coursera
Lernen Sie maschinelles Lernen mit Online-Kursen und -Kursen | edX
Zurück nach oben
Einführung in maschinelles Lernen (PDF)
Künstliche Intelligenz: Ein moderner Ansatz von Stuart J. Russel und Peter Norvig
Deep Learning von Ian Goodfellow, Yoshoua Bengio und Aaron Courville
Das hundertseitige Buch über maschinelles Lernen von Andriy Burkov
Maschinelles Lernen von Tom M. Mitchell
Programmieren kollektiver Intelligenz: Erstellen intelligenter Web 2.0-Anwendungen von Toby Segaran
Maschinelles Lernen: Eine algorithmische Perspektive, 2. Auflage
Mustererkennung und maschinelles Lernen von Christopher M. Bishop
Verarbeitung natürlicher Sprache mit Python von Steven Bird, Ewan Klein und Edward Loper
Python Machine Learning: Ein technischer Ansatz für maschinelles Lernen für Anfänger von Leonard Eddison
Bayesianisches Denken und maschinelles Lernen von David Barber
Maschinelles Lernen für absolute Anfänger: Eine einfache englische Einführung von Oliver Theobald
Maschinelles Lernen in Aktion von Ben Wilson
Praktisches maschinelles Lernen mit Scikit-Learn, Keras und TensorFlow: Konzepte, Tools und Techniken zum Aufbau intelligenter Systeme von Aurélien Géron
Einführung in maschinelles Lernen mit Python: Ein Leitfaden für Datenwissenschaftler von Andreas C. Müller und Sarah Guido
Maschinelles Lernen für Hacker: Fallstudien und Algorithmen für den Einstieg von Drew Conway und John Myles White
Die Elemente des statistischen Lernens: Data Mining, Inferenz und Vorhersage von Trevor Hastie, Robert Tibshirani und Jerome Friedman
Verteilte Muster des maschinellen Lernens – Buch (kostenlos online lesbar) + Code
Maschinelles Lernen in der realen Welt [Kostenlose Kapitel]
Eine Einführung in das statistische Lernen – Buch + R-Code
Elemente des statistischen Lernens – Buch
Think Bayes – Buch + Python-Code
Riesige Datensätze abbauen
Eine erste Begegnung mit maschinellem Lernen
Einführung in maschinelles Lernen – Alex Smola und SVN Vishwanathan
Eine probabilistische Theorie der Mustererkennung
Einführung in die Informationsbeschaffung
Prognose: Prinzipien und Praxis
Einführung in maschinelles Lernen – Amnon Shashua
Verstärkungslernen
Maschinelles Lernen
Eine Suche nach KI
R-Programmierung für Data Science
Data Mining – Praktische Tools und Techniken für maschinelles Lernen
Maschinelles Lernen mit TensorFlow
Maschinelle Lernsysteme
Grundlagen des maschinellen Lernens – Mehryar Mohri, Afshin Rostamizadeh und Ameet Talwalkar
KI-gestützte Suche – Trey Grainger, Doug Turnbull, Max Irwin –
Ensemble-Methoden für maschinelles Lernen – Gautam Kunapuli
Maschinelles Lernen in Aktion – Ben Wilson
Datenschutzschonendes maschinelles Lernen – J. Morris Chang, Di Zhuang, G. Dumindu Samaraweera
Automatisiertes maschinelles Lernen in Aktion – Qingquan Song, Haifeng Jin und Xia Hu
Verteilte Muster des maschinellen Lernens – Yuan Tang
Verwalten von maschinellen Lernprojekten: Vom Entwurf bis zur Bereitstellung – Simon Thompson
Kausales maschinelles Lernen – Robert Ness
Bayesianische Optimierung in Aktion – Quan Nguyen
Algorithmen für maschinelles Lernen im Detail) – Vadim Smolyakov
Optimierungsalgorithmen – Alaa Khamis
Praktisches Gradient Boosting von Guillaume Saupin
Zurück nach oben
Zurück nach oben
TensorFlow ist eine End-to-End-Open-Source-Plattform für maschinelles Lernen. Es verfügt über ein umfassendes, flexibles Ökosystem aus Tools, Bibliotheken und Community-Ressourcen, mit dem Forscher den neuesten Stand der Technik im Bereich ML vorantreiben und Entwickler problemlos ML-basierte Anwendungen erstellen und bereitstellen können.
Keras ist eine High-Level-API für neuronale Netze, die in Python geschrieben ist und auf TensorFlow, CNTK oder Theano ausgeführt werden kann. Sie wurde mit dem Schwerpunkt entwickelt, schnelles Experimentieren zu ermöglichen. Es kann auf TensorFlow, Microsoft Cognitive Toolkit, R, Theano oder PlaidML ausgeführt werden.
PyTorch ist eine Bibliothek für Deep Learning für unregelmäßige Eingabedaten wie Diagramme, Punktwolken und Mannigfaltigkeiten. Hauptsächlich vom Facebook-KI-Forschungslabor entwickelt.
Amazon SageMaker ist ein vollständig verwalteter Dienst, der jedem Entwickler und Datenwissenschaftler die Möglichkeit bietet, Modelle für maschinelles Lernen (ML) schnell zu erstellen, zu trainieren und bereitzustellen. SageMaker entlastet jeden Schritt des maschinellen Lernprozesses und erleichtert so die Entwicklung qualitativ hochwertiger Modelle.
Azure Databricks ist ein schneller und kollaborativer Big-Data-Analysedienst auf Apache Spark-Basis, der für Data Science und Data Engineering entwickelt wurde. Azure Databricks richtet Ihre Apache Spark-Umgebung in wenigen Minuten ein, skaliert automatisch und arbeitet in einem interaktiven Arbeitsbereich an gemeinsamen Projekten zusammen. Azure Databricks unterstützt Python, Scala, R, Java und SQL sowie Data-Science-Frameworks und -Bibliotheken, einschließlich TensorFlow, PyTorch und scikit-learn.
Microsoft Cognitive Toolkit (CNTK) ist ein Open-Source-Toolkit für verteiltes Deep Learning in kommerzieller Qualität. Es beschreibt neuronale Netze als eine Reihe von Rechenschritten über einen gerichteten Graphen. Mit CNTK kann der Benutzer gängige Modelltypen wie Feed-Forward-DNNs, Convolutional Neural Networks (CNNs) und Recurrent Neural Networks (RNNs/LSTMs) einfach realisieren und kombinieren. CNTK implementiert stochastisches Gradientenabstiegslernen (SGD, Error Backpropagation) mit automatischer Differenzierung und Parallelisierung über mehrere GPUs und Server hinweg.
Apple CoreML ist ein Framework, das dabei hilft, Modelle für maschinelles Lernen in Ihre App zu integrieren. Core ML bietet eine einheitliche Darstellung für alle Modelle. Ihre App nutzt Core ML APIs und Benutzerdaten, um Vorhersagen zu treffen und Modelle zu trainieren oder zu optimieren – alles auf dem Gerät des Benutzers. Ein Modell ist das Ergebnis der Anwendung eines maschinellen Lernalgorithmus auf einen Satz Trainingsdaten. Sie verwenden ein Modell, um Vorhersagen auf der Grundlage neuer Eingabedaten zu treffen.
Apache OpenNLP ist eine Open-Source-Bibliothek für ein auf maschinellem Lernen basierendes Toolkit zur Verarbeitung natürlichsprachlicher Texte. Es verfügt über eine API für Anwendungsfälle wie die Erkennung benannter Entitäten, Satzerkennung, POS-Tagging (Part-Of-Speech), Extraktion von Tokenisierungsmerkmalen, Chunking, Parsing und Koreferenzauflösung.
Apache Airflow ist eine von der Community entwickelte Open-Source-Workflow-Management-Plattform zum programmgesteuerten Erstellen, Planen und Überwachen von Workflows. Installieren. Prinzipien. Skalierbar. Airflow verfügt über eine modulare Architektur und verwendet eine Nachrichtenwarteschlange, um eine beliebige Anzahl von Workern zu orchestrieren. Der Luftstrom kann bis ins Unendliche skaliert werden.
Open Neural Network Exchange (ONNX) ist ein offenes Ökosystem, das es KI-Entwicklern ermöglicht, die richtigen Tools auszuwählen, während sich ihr Projekt weiterentwickelt. ONNX bietet ein Open-Source-Format für KI-Modelle, sowohl Deep Learning als auch traditionelles ML. Es definiert ein erweiterbares Berechnungsdiagrammmodell sowie Definitionen integrierter Operatoren und Standarddatentypen.
Apache MXNet ist ein Deep-Learning-Framework, das sowohl auf Effizienz als auch auf Flexibilität ausgelegt ist. Es ermöglicht Ihnen, symbolische und imperative Programmierung zu kombinieren, um Effizienz und Produktivität zu maximieren. Im Kern enthält MXNet einen dynamischen Abhängigkeitsplaner, der sowohl symbolische als auch imperative Vorgänge automatisch im laufenden Betrieb parallelisiert. Eine darüber liegende Ebene zur Diagrammoptimierung sorgt für eine schnelle symbolische Ausführung und eine effiziente Speichernutzung. MXNet ist portabel und leicht und lässt sich effektiv auf mehrere GPUs und mehrere Maschinen skalieren. Unterstützung für Python, R, Julia, Scala, Go, Javascript und mehr.
AutoGluon ist ein Toolkit für Deep Learning, das maschinelle Lernaufgaben automatisiert und es Ihnen ermöglicht, auf einfache Weise eine starke Vorhersageleistung in Ihren Anwendungen zu erzielen. Mit nur wenigen Codezeilen können Sie hochpräzise Deep-Learning-Modelle für Tabellen-, Bild- und Textdaten trainieren und bereitstellen.
Anaconda ist eine sehr beliebte Data-Science-Plattform für maschinelles Lernen und Deep Learning, die es Benutzern ermöglicht, Modelle zu entwickeln, sie zu trainieren und einzusetzen.
PlaidML ist ein fortschrittlicher und tragbarer Tensor-Compiler, der Deep Learning auf Laptops, eingebetteten Geräten oder anderen Geräten ermöglicht, bei denen die verfügbare Computerhardware nicht gut unterstützt wird oder der verfügbare Software-Stack unangenehme Lizenzbeschränkungen enthält.
OpenCV ist eine hochoptimierte Bibliothek mit Schwerpunkt auf Echtzeit-Computer-Vision-Anwendungen. Die C++-, Python- und Java-Schnittstellen unterstützen Linux, MacOS, Windows, iOS und Android.
Scikit-Learn ist ein Python-Modul für maschinelles Lernen, das auf SciPy, NumPy und matplotlib aufbaut und die Anwendung robuster und einfacher Implementierungen vieler beliebter Algorithmen für maschinelles Lernen erleichtert.
Weka ist eine Open-Source-Software für maschinelles Lernen, auf die über eine grafische Benutzeroberfläche, Standard-Terminalanwendungen oder eine Java-API zugegriffen werden kann. Es wird häufig für Lehre, Forschung und industrielle Anwendungen verwendet, enthält eine Vielzahl integrierter Tools für Standardaufgaben des maschinellen Lernens und bietet darüber hinaus transparenten Zugriff auf bekannte Toolboxen wie scikit-learn, R und Deeplearning4j.
Caffe ist ein Deep-Learning-Framework, das auf Ausdruck, Geschwindigkeit und Modularität ausgelegt ist. Es wurde von Berkeley AI Research (BAIR)/The Berkeley Vision and Learning Center (BVLC) und Community-Mitwirkenden entwickelt.
Theano ist eine Python-Bibliothek, mit der Sie mathematische Ausdrücke mit mehrdimensionalen Arrays effizient definieren, optimieren und auswerten können, einschließlich einer engen Integration mit NumPy.
nGraph ist eine Open-Source-C++-Bibliothek, ein Compiler und eine Laufzeitumgebung für Deep Learning. Der nGraph Compiler zielt darauf ab, die Entwicklung von KI-Workloads mithilfe eines beliebigen Deep-Learning-Frameworks und der Bereitstellung auf einer Vielzahl von Hardwarezielen zu beschleunigen. Er bietet KI-Entwicklern Freiheit, Leistung und Benutzerfreundlichkeit.
NVIDIA cuDNN ist eine GPU-beschleunigte Bibliothek von Grundelementen für tiefe neuronale Netze. cuDNN bietet hochgradig abgestimmte Implementierungen für Standardroutinen wie Vorwärts- und Rückwärtsfaltung, Pooling, Normalisierung und Aktivierungsschichten. cuDNN beschleunigt weit verbreitete Deep-Learning-Frameworks, darunter Caffe2, Chainer, Keras, MATLAB, MxNet, PyTorch und TensorFlow.
Huginn ist ein selbst gehostetes System für Bauagenten, die online automatisierte Aufgaben für Sie ausführen. Es kann das Internet lesen, auf Ereignisse achten und in Ihrem Namen Maßnahmen ergreifen. Huginns Agenten erstellen und konsumieren Ereignisse und verbreiten sie entlang eines gerichteten Diagramms. Betrachten Sie es als eine hackbare Version von IFTTT oder Zapier auf Ihrem eigenen Server.
Netron ist ein Viewer für Modelle für neuronale Netze, Deep Learning und maschinelles Lernen. Es unterstützt ONNX, TensorFlow Lite, Caffe, Keras, Darknet, PaddlePaddle, ncnn, MNN, Core ML, RKNN, MXNet, MindSpore Lite, TNN, Barracuda, Tengine, CNTK, TensorFlow.js, Caffe2 und UFF.
Dopamin ist ein Forschungsrahmen für das schnelle Prototyping von Reinforcement-Learning-Algorithmen.
DALI ist eine GPU-beschleunigte Bibliothek, die hochoptimierte Bausteine und eine Ausführungs-Engine für die Datenverarbeitung enthält, um Deep-Learning-Trainings- und Inferenzanwendungen zu beschleunigen.
MindSpore Lite ist ein neues Open-Source-Deep-Learning-Trainings-/Inferenz-Framework, das für mobile, Edge- und Cloud-Szenarien verwendet werden kann.
Darknet ist ein Open-Source-Framework für neuronale Netzwerke, das in C und CUDA geschrieben ist. Es ist schnell, einfach zu installieren und unterstützt CPU- und GPU-Berechnungen.
PaddlePaddle ist eine benutzerfreundliche, effiziente, flexible und skalierbare Deep-Learning-Plattform, die ursprünglich von Wissenschaftlern und Ingenieuren von Baidu entwickelt wurde, um Deep Learning auf viele Produkte bei Baidu anzuwenden.
GoogleNotebookLM ist ein experimentelles KI-Tool, das die Leistungsfähigkeit von Sprachmodellen in Kombination mit Ihren vorhandenen Inhalten nutzt, um schneller wichtige Erkenntnisse zu gewinnen. Ähnlich einem virtuellen Forschungsassistenten, der Fakten zusammenfassen, komplexe Ideen erklären und auf der Grundlage der von Ihnen ausgewählten Quellen neue Zusammenhänge erarbeiten kann.
Unilm ist ein groß angelegtes, selbstüberwachtes Vortraining für Aufgaben, Sprachen und Modalitäten.
Semantic Kernel (SK) ist ein leichtes SDK, das die Integration von AI Large Language Models (LLMs) mit herkömmlichen Programmiersprachen ermöglicht. Das erweiterbare Programmiermodell von SK kombiniert semantische Funktionen in natürlicher Sprache, traditionelle Code-native-Funktionen und einbettungsbasierten Speicher, um neue Potenziale zu erschließen und Anwendungen mit KI einen Mehrwert zu verleihen.
Pandas AI ist eine Python-Bibliothek, die generative künstliche Intelligenzfunktionen in Pandas integriert und so Datenrahmen konversationsfähig macht.
NCNN ist ein leistungsstarkes Inferenz-Framework für neuronale Netze, das für die mobile Plattform optimiert ist.
MNN ist ein blitzschnelles, leichtes Deep-Learning-Framework, das sich in geschäftskritischen Anwendungsfällen in Alibaba bewährt hat.
MediaPipe ist für die End-to-End-Leistung auf einer Vielzahl von Plattformen optimiert. Demos ansehen Mehr erfahren Komplexes ML auf dem Gerät, vereinfacht Wir haben die Komplexität abstrahiert, die es mit sich bringt, ML auf dem Gerät anpassbar, produktionsbereit und plattformübergreifend zugänglich zu machen.
MegEngine ist ein schnelles, skalierbares und benutzerfreundliches Deep-Learning-Framework mit drei Hauptfunktionen: Einheitliches Framework für Training und Inferenz.
ML.NET ist eine Bibliothek für maschinelles Lernen, die als erweiterbare Plattform konzipiert ist, sodass Sie andere beliebte ML-Frameworks (TensorFlow, ONNX, Infer.NET und mehr) nutzen und Zugriff auf noch mehr Szenarien für maschinelles Lernen haben, wie z. B. Bildklassifizierung, Objekterkennung und mehr.
Ludwig ist ein deklaratives Framework für maschinelles Lernen, das die Definition von Pipelines für maschinelles Lernen mithilfe eines einfachen und flexiblen datengesteuerten Konfigurationssystems erleichtert.
MMdnn ist ein umfassendes und Framework-übergreifendes Tool zur Konvertierung, Visualisierung und Diagnose von Deep-Learning-Modellen (DL). „MM“ steht für Model Management und „dnn“ ist die Abkürzung für Deep Neural Network. Konvertieren Sie Modelle zwischen Caffe, Keras, MXNet, Tensorflow, CNTK, PyTorch Onnx und CoreML.
Horovod ist ein verteiltes Deep-Learning-Trainingsframework für TensorFlow, Keras, PyTorch und Apache MXNet.
Vaex ist eine leistungsstarke Python-Bibliothek für verzögerte Out-of-Core-DataFrames (ähnlich wie Pandas), um große tabellarische Datensätze zu visualisieren und zu untersuchen.
GluonTS ist ein Python-Paket für die probabilistische Zeitreihenmodellierung mit Schwerpunkt auf Deep-Learning-basierten Modellen, basierend auf PyTorch und MXNet.
MindsDB ist ein ML-SQL-Server, der maschinelle Lernworkflows für die leistungsstärksten Datenbanken und Data Warehouses mit SQL ermöglicht.
Jupyter Notebook ist eine Open-Source-Webanwendung, mit der Sie Dokumente erstellen und teilen können, die Live-Code, Gleichungen, Visualisierungen und narrativen Text enthalten. Jupyter wird häufig in Branchen eingesetzt, die sich mit Datenbereinigung und -transformation, numerischer Simulation, statistischer Modellierung, Datenvisualisierung, Datenwissenschaft und maschinellem Lernen befassen.
Apache Spark ist eine einheitliche Analyse-Engine für die Verarbeitung großer Datenmengen. Es bietet High-Level-APIs in Scala, Java, Python und R sowie eine optimierte Engine, die allgemeine Berechnungsdiagramme für die Datenanalyse unterstützt. Es unterstützt außerdem eine Vielzahl übergeordneter Tools, darunter Spark SQL für SQL und DataFrames, MLlib für maschinelles Lernen, GraphX für die Diagrammverarbeitung und Structured Streaming für die Stream-Verarbeitung.
Apache Spark Connector für SQL Server und Azure SQL ist ein leistungsstarker Connector, der Ihnen die Verwendung von Transaktionsdaten in Big-Data-Analysen ermöglicht und Ergebnisse für Ad-hoc-Abfragen oder Berichte speichert. Mit dem Connector können Sie jede SQL-Datenbank lokal oder in der Cloud als Eingabedatenquelle oder Ausgabedatensenke für Spark-Jobs verwenden.
Apache PredictionIO ist ein Open-Source-Framework für maschinelles Lernen für Entwickler, Datenwissenschaftler und Endbenutzer. Es unterstützt die Ereigniserfassung, die Bereitstellung von Algorithmen, die Auswertung und die Abfrage von Vorhersageergebnissen über REST-APIs. Es basiert auf skalierbaren Open-Source-Diensten wie Hadoop, HBase (und anderen DBs), Elasticsearch, Spark und implementiert eine sogenannte Lambda-Architektur.
Cluster Manager für Apache Kafka (CMAK) ist ein Tool zur Verwaltung von Apache Kafka-Clustern.
BigDL ist eine verteilte Deep-Learning-Bibliothek für Apache Spark. Mit BigDL können Benutzer ihre Deep-Learning-Anwendungen als Standard-Spark-Programme schreiben, die direkt auf vorhandenen Spark- oder Hadoop-Clustern ausgeführt werden können.
Eclipse Deeplearning4J (DL4J) ist eine Reihe von Projekten, die alle Anforderungen einer JVM-basierten Deep-Learning-Anwendung (Scala, Kotlin, Clojure und Groovy) unterstützen sollen. Das bedeutet, dass man mit den Rohdaten beginnt, diese lädt und vorverarbeitet, egal wo und in welchem Format sie vorliegen, bis hin zum Aufbau und der Optimierung einer Vielzahl einfacher und komplexer Deep-Learning-Netzwerke.
Tensorman ist ein von System76 entwickeltes Dienstprogramm zur einfachen Verwaltung von Tensorflow-Containern. Tensorman ermöglicht den Betrieb von Tensorflow in einer isolierten Umgebung, die vom Rest des Systems isoliert ist. Diese virtuelle Umgebung kann unabhängig vom Basissystem betrieben werden, sodass Sie jede Version von Tensorflow auf jeder Version einer Linux-Distribution verwenden können, die die Docker-Laufzeit unterstützt.
Numba ist ein Open-Source-, NumPy-fähiger, optimierender Compiler für Python, der von Anaconda, Inc. gesponsert wird. Er verwendet das LLVM-Compilerprojekt, um Maschinencode aus der Python-Syntax zu generieren. Numba kann eine große Teilmenge von numerisch fokussiertem Python kompilieren, einschließlich vieler NumPy-Funktionen. Darüber hinaus unterstützt Numba die automatische Parallelisierung von Schleifen, die Generierung von GPU-beschleunigtem Code sowie die Erstellung von UFUNCs und C-Callbacks.
Chainer ist ein Python-basiertes Deep-Learning-Framework, das auf Flexibilität abzielt. Es bietet automatische Differenzierungs-APIs basierend auf dem Define-by-Run-Ansatz (dynamische Rechendiagramme) sowie objektorientierte High-Level-APIs zum Aufbau und Training neuronaler Netze. Es unterstützt auch CUDA/cuDNN mit CuPy für Hochleistungstraining und Inferenz.
XGBoost ist eine optimierte verteilte Gradient-Boosting-Bibliothek, die hocheffizient, flexibel und portabel ist. Es implementiert Algorithmen für maschinelles Lernen im Rahmen des Gradient Boosting-Frameworks. XGBoost bietet ein paralleles Tree-Boosting (auch bekannt als GBDT, GBM), das viele datenwissenschaftliche Probleme schnell und genau löst. Es unterstützt verteiltes Training auf mehreren Maschinen, einschließlich AWS-, GCE-, Azure- und Yarn-Clustern. Außerdem kann es in Flink, Spark und andere Cloud-Datenflusssysteme integriert werden.
cuML ist eine Suite von Bibliotheken, die Algorithmen für maschinelles Lernen und mathematische Grundfunktionen implementieren, die kompatible APIs mit anderen RAPIDS-Projekten teilen. Mit cuML können Datenwissenschaftler, Forscher und Softwareentwickler herkömmliche tabellarische ML-Aufgaben auf GPUs ausführen, ohne sich mit den Details der CUDA-Programmierung befassen zu müssen. In den meisten Fällen stimmt die Python-API von cuML mit der API von scikit-learn überein.
Emu ist eine GPGPU-Bibliothek für Rust mit Schwerpunkt auf Portabilität, Modularität und Leistung. Es handelt sich um eine CUDA-artige rechenspezifische Abstraktion über WebGPU, die spezifische Funktionen bereitstellt, damit sich WebGPU eher wie CUDA anfühlt.
Scalene ist ein leistungsstarker CPU-, GPU- und Speicherprofiler für Python, der eine Reihe von Dingen kann, die andere Python-Profiler nicht können und können. Es läuft um Größenordnungen schneller als viele andere Profiler und liefert gleichzeitig weitaus detailliertere Informationen.
MLpack ist eine schnelle, flexible C++-Bibliothek für maschinelles Lernen, die in C++ geschrieben ist und auf der linearen Algebra-Bibliothek Armadillo, der numerischen Optimierungsbibliothek ensmallen und Teilen von Boost basiert.
Netron ist ein Viewer für Modelle für neuronale Netze, Deep Learning und maschinelles Lernen. Es unterstützt ONNX, TensorFlow Lite, Caffe, Keras, Darknet, PaddlePaddle, ncnn, MNN, Core ML, RKNN, MXNet, MindSpore Lite, TNN, Barracuda, Tengine, CNTK, TensorFlow.js, Caffe2 und UFF.
Lightning ist ein Tool, das PyTorch-Modelle erstellt und trainiert und sie mithilfe von Lightning-App-Vorlagen mit dem ML-Lebenszyklus verbindet, ohne sich um DIY-Infrastruktur, Kostenmanagement, Skalierung usw. kümmern zu müssen.
OpenNN ist eine Open-Source-Bibliothek für neuronale Netze für maschinelles Lernen. Es enthält hochentwickelte Algorithmen und Dienstprogramme für den Umgang mit vielen Lösungen der künstlichen Intelligenz.
H20 ist eine KI-Cloud-Plattform, die komplexe Geschäftsprobleme löst und die Entdeckung neuer Ideen beschleunigt – mit Ergebnissen, die Sie verstehen und denen Sie vertrauen können.
Gensim ist eine Python-Bibliothek zur Themenmodellierung, Dokumentindizierung und Ähnlichkeitssuche mit großen Korpora. Zielgruppe ist die Community für die Verarbeitung natürlicher Sprache (NLP) und die Informationsgewinnung (IR).
llama.cpp ist eine Portierung des LLaMA-Modells von Facebook in C/C++.
hmmlearn ist eine Reihe von Algorithmen für unbeaufsichtigtes Lernen und Inferenz von Hidden-Markov-Modellen.
Nextjournal ist ein Notizbuch für reproduzierbare Recherche. Es führt alles aus, was Sie in einen Docker-Container einfügen können. Verbessern Sie Ihren Workflow mit mehrsprachigen Notizbüchern, automatischer Versionierung und Zusammenarbeit in Echtzeit. Sparen Sie Zeit und Geld mit der On-Demand-Bereitstellung, einschließlich GPU-Unterstützung.
IPython bietet eine umfangreiche Architektur für interaktives Computing mit:
Veles ist eine verteilte Plattform für die schnelle Entwicklung von Deep-Learning-Anwendungen, die derzeit von Samsung entwickelt wird.
DyNet ist eine neuronale Netzwerkbibliothek, die von der Carnegie Mellon University und vielen anderen entwickelt wurde. Es ist in C++ geschrieben (mit Bindungen in Python) und so konzipiert, dass es sowohl auf der CPU als auch auf der GPU effizient läuft und gut mit Netzwerken funktioniert, deren dynamische Strukturen sich für jede Trainingsinstanz ändern. Diese Art von Netzwerken ist besonders wichtig bei der Verarbeitung natürlicher Sprache, und DyNet wurde zum Aufbau hochmoderner Systeme für syntaktisches Parsen, maschinelle Übersetzung, morphologische Flexion und viele andere Anwendungsbereiche verwendet.
Ray ist ein einheitliches Framework zur Skalierung von KI- und Python-Anwendungen. Es besteht aus einer verteilten Kernlaufzeit und einem Toolkit von Bibliotheken (Ray AIR) zur Beschleunigung von ML-Workloads.
whisper.cpp ist eine leistungsstarke Inferenz des automatischen Spracherkennungsmodells (ASR) Whisper von OpenAI.
ChatGPT Plus ist ein Pilotabonnement ( 20 $/Monat ) für ChatGPT, eine Konversations-KI, die mit Ihnen chatten, Folgefragen beantworten und falsche Annahmen in Frage stellen kann.
Auto-GPT ist ein „KI-Agent“, der ein Ziel in natürlicher Sprache vorgibt und versuchen kann, dieses zu erreichen, indem er es in Unteraufgaben aufteilt und das Internet und andere Tools in einer automatischen Schleife nutzt. Es nutzt die GPT-4- oder GPT-3.5-APIs von OpenAI und gehört zu den ersten Beispielen einer Anwendung, die GPT-4 zur Ausführung autonomer Aufgaben verwendet.
Chatbot UI von mckaywrigley ist ein erweitertes Chatbot-Kit für die Chat-Modelle von OpenAI, das auf Chatbot UI Lite mit Next.js, TypeScript und Tailwind CSS aufbaut. Diese Version der ChatBot-Benutzeroberfläche unterstützt sowohl GPT-3.5- als auch GPT-4-Modelle. Gespräche werden lokal in Ihrem Browser gespeichert. Sie können Konversationen exportieren und importieren, um sich vor Datenverlust zu schützen. Sehen Sie sich eine Demo an.
Chatbot UI Lite von mckaywrigley ist ein einfaches Chatbot-Starterkit für das Chat-Modell von OpenAI mit Next.js, TypeScript und Tailwind CSS. Sehen Sie sich eine Demo an.
MiniGPT-4 ist ein verbessertes visuelles Sprachverständnis mit fortschrittlichen großen Sprachmodellen.
GPT4All ist ein Ökosystem von Open-Source-Chatbots, die auf einer riesigen Sammlung sauberer Assistentendaten, einschließlich Code, Geschichten und Dialogen, basierend auf LLaMa, trainiert werden.
GPT4All UI ist eine Flask-Webanwendung, die eine Chat-Benutzeroberfläche für die Interaktion mit dem GPT4All-Chatbot bereitstellt.
Alpaca.cpp ist ein schnelles ChatGPT-ähnliches Modell lokal auf Ihrem Gerät. Es kombiniert das LLaMA-Grundmodell mit einer offenen Reproduktion von Stanford Alpaca, einer Feinabstimmung des Basismodells, um Anweisungen zu befolgen (ähnlich dem RLHF, das zum Trainieren von ChatGPT verwendet wird) und einer Reihe von Modifikationen an llama.cpp, um eine Chat-Schnittstelle hinzuzufügen.
llama.cpp ist eine Portierung des LLaMA-Modells von Facebook in C/C++.
OpenPlayground ist ein Spielplatz zum lokalen Ausführen von ChatGPT-ähnlichen Modellen auf Ihrem Gerät.
Vicuna ist ein Open-Source-Chatbot, der durch die Feinabstimmung von LLaMA trainiert wurde. Es erreicht offenbar eine Chatgpt-Qualität von mehr als 90 % und die Schulung kostet 300 US-Dollar.
Yeagar ai ist ein Langchain-Agent-Ersteller, der Ihnen dabei helfen soll, KI-gestützte Agents ganz einfach zu erstellen, zu prototypisieren und bereitzustellen.
Vicuna entsteht durch die Feinabstimmung eines LLaMA-Basismodells unter Verwendung von etwa 70.000 von Benutzern geteilten Konversationen, die von ShareGPT.com mit öffentlichen APIs gesammelt wurden. Um die Datenqualität sicherzustellen, wird der HTML-Code wieder in Markdown konvertiert und einige ungeeignete oder minderwertige Beispiele herausgefiltert.
ShareGPT ist ein Ort, an dem Sie Ihre wildesten ChatGPT-Gespräche mit einem Klick teilen können. Bisher wurden 198.404 Gespräche geteilt.
FastChat ist eine offene Plattform zum Trainieren, Bereitstellen und Bewerten großer, auf Sprachmodellen basierender Chatbots.
Haystack ist ein Open-Source-NLP-Framework zur Interaktion mit Ihren Daten mithilfe von Transformer-Modellen und LLMs (GPT-4, ChatGPT und ähnliche). Es bietet produktionsbereite Tools zum schnellen Erstellen komplexer Anwendungen für Entscheidungsfindung, Fragebeantwortung, semantische Suche, Textgenerierung und mehr.
StableLM (Stability AI Language Models) ist eine StableLM-Reihe von Sprachmodellen und wird kontinuierlich mit neuen Prüfpunkten aktualisiert.
Databricks‘ Dolly ist ein anweisungenfolgendes, großes Sprachmodell, das auf der Databricks-Plattform für maschinelles Lernen trainiert wurde und für die kommerzielle Nutzung lizenziert ist.
GPTCach ist eine Bibliothek zum Erstellen eines semantischen Caches für LLM-Abfragen.
AlaC ist ein Infrastructure-as-Code-Generator für künstliche Intelligenz.
Adrenaline ist ein Tool, mit dem Sie mit Ihrer Codebasis kommunizieren können. Es basiert auf statischer Analyse, Vektorsuche und großen Sprachmodellen.
OpenAssistant ist ein chatbasierter Assistent, der Aufgaben versteht, mit Drittsystemen interagieren kann und dazu dynamisch Informationen abruft.
DoctorGPT ist eine leichte, eigenständige Binärdatei, die Ihre Anwendungsprotokolle auf Probleme überwacht und diese diagnostiziert.
HttpGPT ist ein Unreal Engine 5-Plugin, das die Integration mit den GPT-basierten Diensten von OpenAI (ChatGPT und DALL-E) durch asynchrone REST-Anfragen erleichtert und Entwicklern die Kommunikation mit diesen Diensten erleichtert. Es enthält außerdem Editor-Tools zur Integration der Chat-GPT- und DALL-E-Bildgenerierung direkt in die Engine.
PaLM 2 ist ein großes Sprachmodell der nächsten Generation, das auf Googles Erbe bahnbrechender Forschung im Bereich maschinelles Lernen und verantwortungsvolle KI aufbaut. Es umfasst fortgeschrittene Denkaufgaben, einschließlich Code und Mathematik, Klassifizierung und Beantwortung von Fragen, Übersetzung und Mehrsprachigkeit sowie die Generierung natürlicher Sprache, die besser ist als unsere vorherigen hochmodernen LLMs.
Med-PaLM ist ein großes Sprachmodell (LLM), das qualitativ hochwertige Antworten auf medizinische Fragen liefern soll. Es nutzt die Leistungsfähigkeit der großen Sprachmodelle von Google, die wir mit einer Reihe sorgfältig zusammengestellter Demonstrationen medizinischer Experten auf den medizinischen Bereich abgestimmt haben.
Sec-PaLM ist ein großes Sprachmodell (LLM), das die Fähigkeit beschleunigt, Menschen zu helfen, die für die Sicherheit ihrer Organisationen verantwortlich sind. Diese neuen Modelle bieten den Menschen nicht nur eine natürlichere und kreativere Möglichkeit, Sicherheit zu verstehen und zu verwalten.
Zurück nach oben
Zurück nach oben
Zurück nach oben
Localai ist eine selbst gehostete, gemeinschaftsgetriebene örtliche OpenAI-kompatible API. Drop-In-Austausch für OpenAI-Running LLMs auf Hardware für Verbraucherqualität ohne GPU erforderlich. Es ist eine API, um GGML-kompatible Modelle auszuführen: Lama, Gpt4all, RWKV, Whisper, Vicuna, Koala, GPT4all-J, Cerebras, Falcon, Dolly, StarCoder und viele andere.
llama.cpp ist ein Port des Lama -Modells von Facebook in C/C ++.
Ollama ist ein Werkzeug, um mit LLAMA 2 und anderen großen Sprachmodellen lokal zu laufen.
Localai ist eine selbst gehostete, gemeinschaftsgetriebene örtliche OpenAI-kompatible API. Drop-In-Austausch für OpenAI-Running LLMs auf Hardware für Verbraucherqualität ohne GPU erforderlich. Es ist eine API, um GGML-kompatible Modelle auszuführen: Lama, Gpt4all, RWKV, Whisper, Vicuna, Koala, GPT4all-J, Cerebras, Falcon, Dolly, StarCoder und viele andere.
Serge ist eine Weboberfläche zum Chatten mit Alpaka über Lama.cpp. Vollständig selbst gehostet und dockiert, mit einer einfach zu verwendenden API.
Openllm ist eine offene Plattform für den Betrieb von Großsprachemodellen (LLMs) in der Produktion. Feinabstimmung, servieren, bereitstellen und überwachen Sie alle LLMs mühelos.
Lama-gpt ist ein selbstwertiger, offline-Chatgpt-ähnlicher Chatbot. Angetrieben von Lama 2. 100% privat, ohne dass Daten Ihr Gerät verlassen.
LLAMA2 Webui ist ein Tool, um Lama 2 lokal mit Gradio UI an GPU oder CPU von überall (Linux/Windows/Mac) auszuführen. Verwenden Sie llama2-wrapper als Ihr lokales Lama2-Backend für Generativmakler/Apps.
LLAMA2.c ist ein Werkzeug, um die LLM-Architektur LLA 2 LLM in Pytorch zu trainieren und sie dann mit einer einfachen 700-Linie-C-Datei (Run.C) zu inferenzen.
Alpaca.cpp ist ein schnelles Chatgpt-ähnliches Modell vor Ort auf Ihrem Gerät. Es kombiniert das Modell der LLAMA Foundation mit einer offenen Reproduktion von Stanford Alpaca, einem Feinabstimmung des Basismodells, um Anweisungen zu befolgen (ähnlich wie die RLHF, die zum Training von Chatgpt verwendet wurde) und eine Reihe von Modifikationen an llama.cpp, um eine Chat-Schnittstelle hinzuzufügen.
GPT4ALL ist ein Ökosystem von Open-Source-Chatbots, die auf massiven Sammlungen sauberer Assistenten geschult wurden, darunter Code, Geschichten und Dialoge, die auf Lama basieren.
MiniGPT-4 ist ein verbessertes Verständnis für die Visionsprachen mit fortgeschrittenen großen Sprachmodellen
Lollms Webui ist ein Hub für LLM -Modelle (großes Sprachmodell). Ziel ist es, eine benutzerfreundliche Schnittstelle zur Verfügung zu stellen, um verschiedene LLM-Modelle für eine Vielzahl von Aufgaben zuzugreifen und zu verwenden. Unabhängig davon, ob Sie Hilfe beim Schreiben, Codieren, Organisieren von Daten, Generieren von Bildern oder beim Suche nach Antworten auf Ihre Fragen benötigen.
LM Studio ist ein Tool zum Entdecken, Herunterladen und Ausführen lokaler LLMs.
Die Gradio Web UI ist ein Werkzeug für Großsprachmodelle. Unterstützt Transformers, GPTQ, LLAMA.CPP (GGML/GGUF), LLAMA -Modelle.
OpenPlayground ist ein Spiel für das Ausführen von Chatgpt-ähnlichen Modellen lokal auf Ihrem Gerät.
Vicuna ist ein Open -Source -Chatbot, das von Fine Tuning Lama trainiert wurde. Es erreicht anscheinend mehr als 90% der Qualität von ChatGPT und kostet 300 US -Dollar für den Training.
Yeagar AI ist ein Schöpfer von Langchain Agent, der Ihnen dabei helfen soll, mit Leichtigkeit von AI-betriebenen Agenten aufzubauen, zu prototypen und bereitzustellen.
KoboldCPP ist eine benutzerfreundliche AI-Text-Generation-Software für GGML-Modelle. Es ist ein einzelnes Selbst, das aus Concedo verteilt ist, das lama.cpp aufbaut, und einen vielseitigen Kobold -API -Endpunkt, zusätzliche Formatunterstützung, Rückwärtskompatibilität sowie eine schicke Benutzeroberfläche mit anhaltenden Geschichten, Bearbeitung von Tools, Speichern, Speicher, Memory, Welt hinzu Info, Anmerkung des Autors, Charaktere und Szenarien.
Zurück nach oben
Fuzzy Logic ist ein heuristischer Ansatz, der eine fortgeschrittenere Entscheidungsbaumverarbeitung und eine bessere Integration in die Regeln basierende Programmierung ermöglicht.
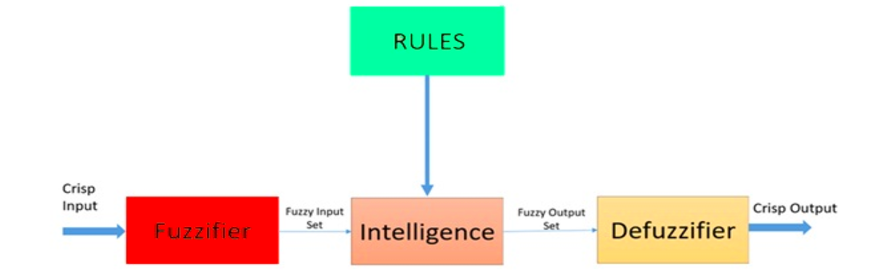
Architektur eines unscharfen Logiksystems. Quelle: ResearchGate
Support Vector Machine (SVM) ist ein überwachtes maschinelles Lernmodell, das Klassifizierungsalgorithmen für Klassifizierungsprobleme mit zwei Gruppen verwendet.

Unterstützen Sie die Vektormaschine (SVM). Quelle: openClipart
Neuronale Netze sind eine Untergruppe des maschinellen Lernens und sind das Herzstück von Deep -Lern -Algorithmen. Der Name/die Struktur wird von dem menschlichen Gehirn inspiriert, der den Prozess kopiert, den biologische Neuronen/Knoten einander signalisieren.
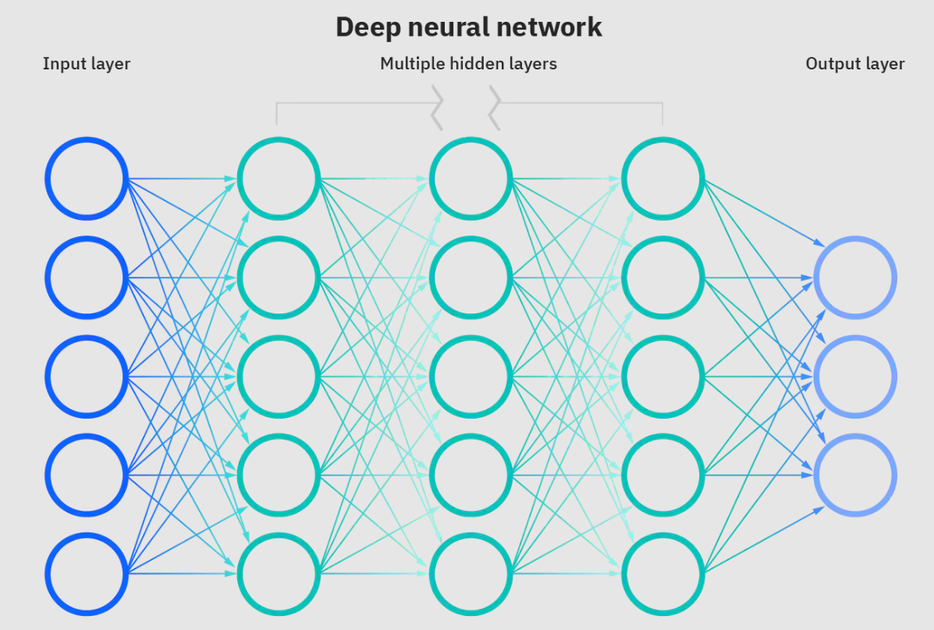
Tiefes neuronales Netzwerk. Quelle: IBM
Faltungsnetzwerke (R-CNN) ist ein Objekterkennungsalgorithmus, der zuerst das Bild zum Finden potenzieller relevanter Begrenzungsboxen segmentiert und dann den Erkennungsalgorithmus ausführt, um die meisten wahrscheinlichen Objekte in diesen Begrenzungsboxen zu finden.
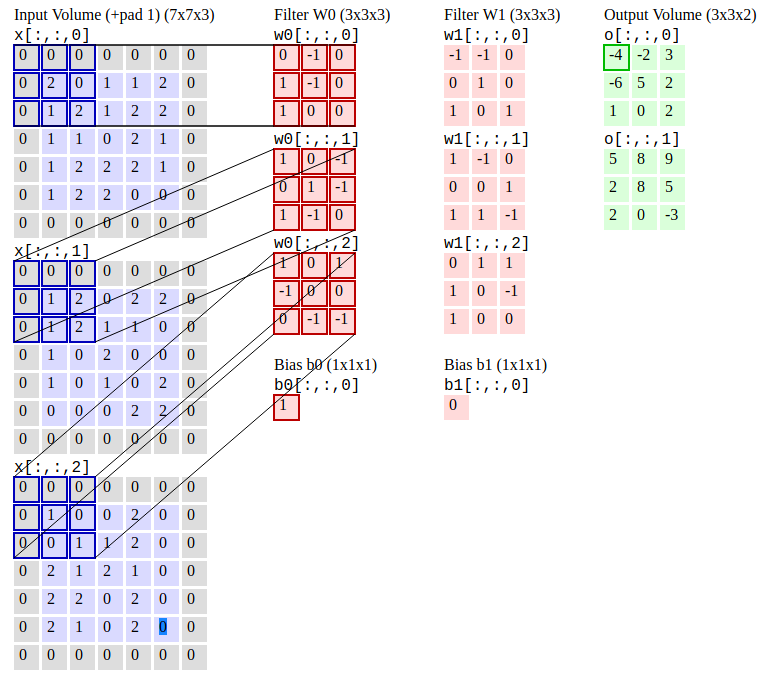
Faltungsnetzwerke. Quelle: CS231N
Recurrent Neural Networks (RNNs) ist eine Art künstlicher neuronaler Netzwerk, das sequentielle Daten- oder Zeitreihendaten verwendet.
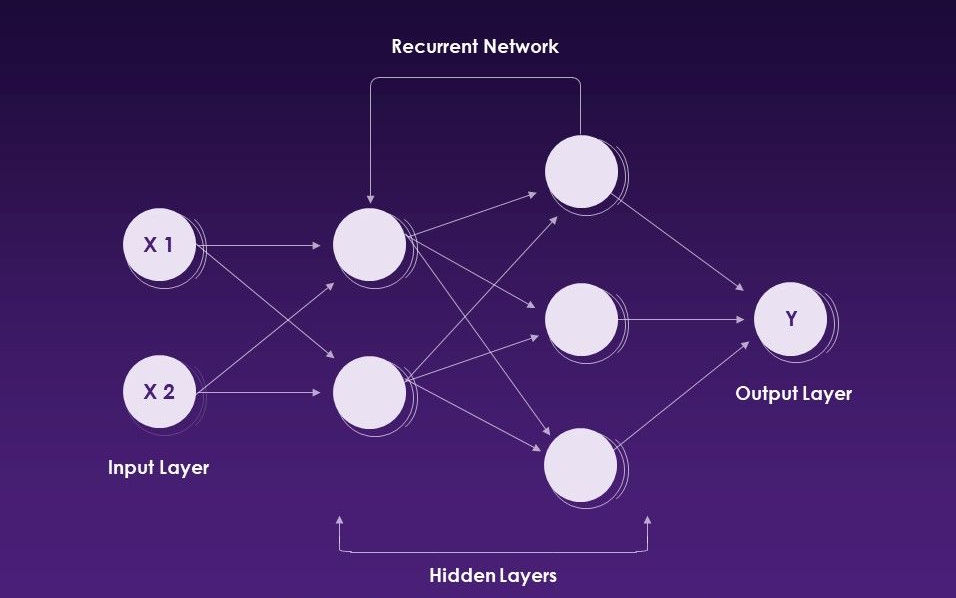
Wiederkehrende neuronale Netzwerke. Quelle: Slideteam
Mehrschichtige Perzeptrons (MLPs) ist mehrschichtige neuronale Netzwerke, die aus mehreren Wahrnehmungsschichten mit einer Schwellenwertaktivierung bestehen.
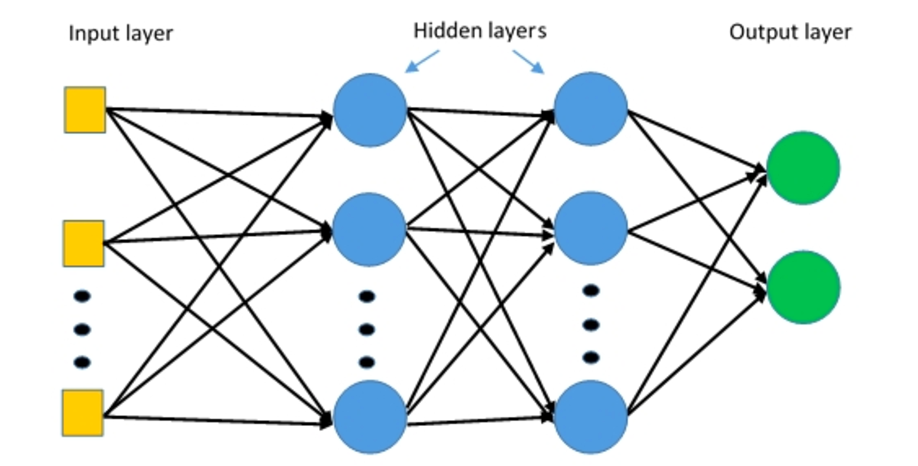
Mehrschichtige Perzeptrons. Quelle: Deepai
Zufälliger Wald ist ein häufig verwendeter Algorithmus für maschinelles Lernen, der die Ausgabe mehrerer Entscheidungsbäume kombiniert, um ein einzelnes Ergebnis zu erzielen. Ein Entscheidungsbaum in einem Wald kann nicht zur Probenahme und damit für die Vorhersageauswahl beschnitten werden. Seine Benutzerfreundlichkeit und Flexibilität haben seine Einführung angeheizt, da sie sowohl Klassifizierungs- als auch Regressionsprobleme behandelt.
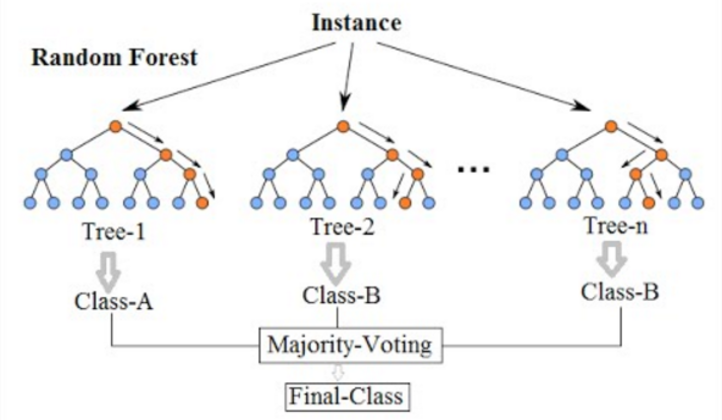
Zufallswald. Quelle: Wikimedia
Entscheidungsbäume sind baumstrukturierte Modelle für die Klassifizierung und Regression.
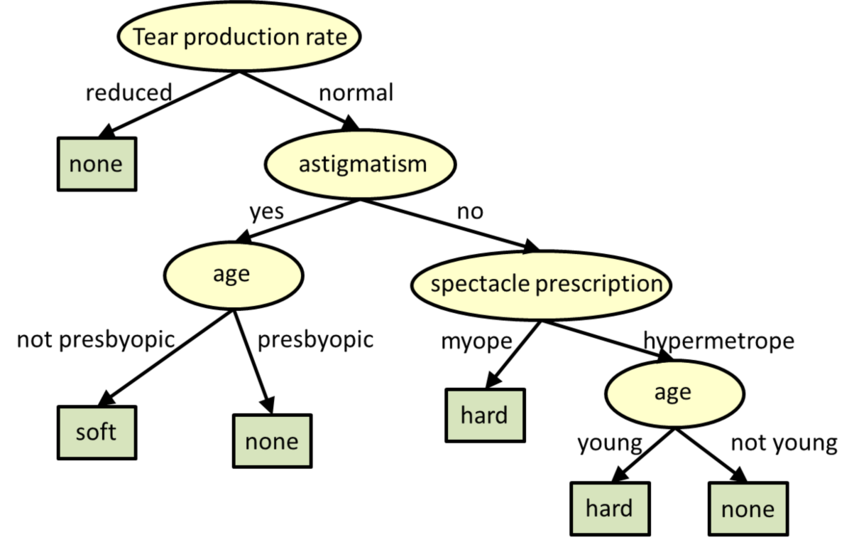
** Entscheidungsbäume. Quelle: CMU
Naive Bayes ist ein Algorithmus für maschinelles Lernen, der gelöste CALSSIFIFIZATION -Probleme verwendet wird. Es basiert auf der Anwendung von Bayes 'Theorem mit starken Unabhängigkeitsannahmen zwischen den Merkmalen.

Bayes 'Theorem. Quelle: Mathisfun
Zurück nach oben

Pytorch ist ein Open-Source-Deep-Lern-Rahmen, der den Weg von der Forschung zur Produktion beschleunigt, die für Anwendungen wie Computer Vision und natürliche Sprachverarbeitung verwendet wird. Pytorch wird vom AI -Forschungslabor von Facebook entwickelt.
Erste Schritte mit Pytorch
Pytorch -Dokumentation
Pytorch -Diskussionsforum
Top -Pytorch -Kurse online | Coursera
Top -Pytorch -Kurse online | Udemy
Lernen Sie Pytorch mit Online -Kursen und Klassen | edX
Pytorch -Grundlagen - Lernen | Microsoft-Dokumente
Intro zum tiefgreifenden Lernen mit Pytorch | Udacity
Pytorch -Entwicklung im Visual Studio Code
Pytorch on Azure - Deep Learning mit Pytorch | Microsoft Azure
Pytorch - Azure Databricks | Microsoft-Dokumente
Tiefes Lernen mit Pytorch | Amazon Web Services (AWS)
Erste Schritte mit Pytorch auf Google Cloud
Pytorch Mobile ist ein End-to-End-ML-Workflow vom Training bis zur Bereitstellung für iOS- und Android-Mobilgeräte.
Torchscript ist eine Möglichkeit, serialisierbare und optimierbare Modelle aus Pytorch -Code zu erstellen. Auf diese Weise kann jedes Torchscript -Programm aus einem Python -Prozess gespeichert und in einem Prozess geladen werden, bei dem keine Python -Abhängigkeit vorhanden ist.
TorchServe ist ein flexibles und einfach zu verwendendes Werkzeug zum Servieren von Pytorch -Modellen.
Keras ist eine hochrangige neuronale Netzwerke-API, die in Python geschrieben wurde und in der Lage ist, auf Tensorflow, CNTK oder Theano zu laufen. Es ist in der Lage, auf Tensorflow, Microsoft Cognitive Toolkit, R, Theano oder Plaidml zu laufen.
Die OnNX-Laufzeit ist eine plattformübergreifende, leistungsstarke ML-Inferenz- und Trainingsbeschleunigerin. Es unterstützt Modelle aus Deep-Learning-Frameworks wie Pytorch und TensorFlow/Keras sowie klassischen Bibliotheken für maschinelles Lernen wie Scikit-Learn, LightGBM, Xgboost usw.
Kornia ist eine differenzierbare Computer -Vision -Bibliothek, die aus einer Reihe von Routinen und differenzierbaren Modulen besteht, um generische CV -Probleme (Computer Vision) zu lösen.
Pytorch-NLP ist eine Bibliothek für die Verarbeitung natürlicher Sprache (NLP) in Python. Es wurde mit den neuesten Forschungsarbeiten aufgebaut und wurde vom ersten Tag an zur Unterstützung Rapid Prototyping entwickelt. Pytorch-NLP verfügt über ausgebildete Einbettungen, Sampler, Datensatzlader, Metriken, neuronale Netzwerkmodule und Textcodierer.
Ignite ist eine hochrangige Bibliothek, die bei der Ausbildung und Bewertung neuronaler Netzwerke in Pytorch flexibel und transparent hilft.
Hummingbird ist eine Bibliothek zum Zusammenstellen geschulter traditioneller ML -Modelle in Tensorberechnungen. Es ermöglicht Benutzern, neuronale Netzwerk -Frameworks (wie Pytorch) nahtlos zu nutzen, um herkömmliche ML -Modelle zu beschleunigen.
Die Deep Graph Library (DGL) ist ein Python -Paket, das für die einfache Implementierung der Grafik -Netzwerkmodellfamilie neben Pytorch und anderen Frameworks erstellt wurde.
Tensory ist eine API auf hoher Ebene für Tensormethoden und tief geprägte neuronale Netzwerke in Python, die das Tensor -Lernen einfach machen soll.
GPYTORCH ist eine mit Pytorch implementierte Gaußsche Prozessbibliothek, die zum Erstellen skalierbarer, flexibler Gaußscher Prozessmodelle entwickelt wurde.
Poutyne ist ein kerasähnliches Rahmen für Pytorch und verarbeitet einen Großteil des Code, der für die Ausbildung neuronaler Netzwerke benötigt wird.
Forte ist ein Toolkit zum Erstellen von NLP-Pipelines mit komponierbaren Komponenten, bequemen Datenschnittstellen und Kreuzungsinteraktion.
TorchMetrics ist ein maschinelles Lernen für verteilte, skalierbare Pytorch -Anwendungen.
Captum ist eine Open -Source -Bibliothek für Modellinterpretierbarkeit, die auf Pytorch basiert.
Transformator ist eine modernste natürliche Sprachverarbeitung für Pytorch, Tensorflow und Jax.
Hydra ist ein Rahmen für die elegant konfigurierte Konfiguration komplexer Anwendungen.
Accelerate ist eine einfache Möglichkeit, Pytorch-Modelle mit Multi-GPU, TPU und gemischter Präzision zu trainieren und zu verwenden.
Ray ist ein schnelles und einfaches Framework zum Erstellen und Ausführen verteilter Anwendungen.
Parlai ist eine einheitliche Plattform zum Teilen, Training und Bewertung von Dialogmodellen über viele Aufgaben.
Pytorchvideo ist eine Deep -Learning -Bibliothek für das Verständnis von Videoverständnissen. Moderiert verschiedene Video-ausgerichtete Modelle, Datensätze, Trainingspipelines und mehr.
Opacus ist eine Bibliothek, die es ermöglicht, Pytorch -Modelle mit unterschiedlicher Privatsphäre zu schulen.
Pytorch Lightning ist eine Keras-ähnliche ML-Bibliothek für Pytorch. Es überlässt Ihnen eine Kerntraining- und Validierungslogik und automatisiert den Rest.
Die geometrische Pytorch -Temporal ist eine zeitliche (dynamische) Erweiterungsbibliothek für pytorch geometrische.
PytOrch Geometric ist eine Bibliothek für tiefes Lernen für unregelmäßige Eingabedaten wie Diagramme, Punktwolken und Verteiler.
Raster Vision ist ein Open -Source -Rahmen für tiefes Lernen auf Satelliten- und Luftbildern.
Crypten ist ein Rahmen für die Privatsphäre, die ML aufbewahrt. Sein Ziel ist es, sichere Computertechniken für ML -Praktiker zugänglich zu machen.
Optuna ist ein Open -Source -Hyperparameter -Optimierungsrahmen, um die Hyperparameter -Suche zu automatisieren.
Pyro ist eine universelle probabilistische Programmiersprache (PPL), die in Python geschrieben und von Pytorch im Backend unterstützt wird.
Albumentations ist eine schnelle und erweiterbare Bildvergrößerungsbibliothek für verschiedene CV -Aufgaben wie Klassifizierung, Segmentierung, Objekterkennung und Posenschätzung.
Skorch ist eine hochrangige Bibliothek für Pytorch, die eine umfassende Kompatibilität für die SCIKIT-LARN bietet.
MMF ist ein modularer Rahmen für die multimodale Forschung von Vision & Language von Facebook AI Research (Fair).
AdaptDL ist ein ressourcenadaptiver Deep-Learning-Trainings- und Planungsrahmen.
Polyaxon ist eine Plattform zum Aufbau, Training und Überwachung großer Deep-Learning-Anwendungen.
Textbrewer ist ein pytorchbasiertes Wissensdestillations-Toolkit für die Verarbeitung natürlicher Sprache
Advertorch ist eine Toolbox für die Forschung für kontroverse Robustheit. Es enthält Module zur Erzeugung von widersprüchlichen Beispielen und zur Verteidigung gegen Angriffe.
Nemo ist ein AA -Toolkit für die Konversations -KI.
Clinicadl ist ein Rahmen für die reproduzierbare Klassifizierung der Alzheimer -Krankheit
Stabile Baseline3 (SB3) ist eine Reihe zuverlässiger Implementierungen von Verstärkungslernen -Algorithmen in Pytorch.
Torchio ist eine Reihe von Tools, um 3D -medizinische Bilder in Pytorch geschrieben zu lesen, vorzuproben, zu probieren, zu erweitern und zu schreiben.
Pysyft ist eine Python -Bibliothek für verschlüsseltes, Datenschutz, um tiefes Lernen zu erhalten.
Flair ist ein sehr einfacher Rahmen für die modernste natürliche Sprachverarbeitung (NLP).
Glow ist ein ML -Compiler, der die Leistung von Deep -Learning -Frameworks auf verschiedenen Hardware -Plattformen beschleunigt.
Fairscale ist eine Pytorch -Erweiterungsbibliothek für Hochleistungen und ein großes Training auf einem oder mehreren Maschinen/Knoten.
Monai ist ein Deep-Learning-Rahmen, der domänenoptimierte grundlegende Fähigkeiten für die Entwicklung von Workflows für die Bildung von Gesundheitsbildern bietet.
PFRL ist eine tiefe Bibliothek für Verstärkung, die verschiedene hochmoderne tiefe Verstärkungsalgorithmen in Python mit Pytorch implementiert.
Einops ist ein flexibler und leistungsstarker Tensor -Operationen für lesbare und zuverlässige Code.
Pytorch3d ist eine Deep -Learning -Bibliothek, die effiziente, wiederverwendbare Komponenten für die 3D -Computer -Vision -Forschung mit Pytorch bietet.
Ensemble Pytorch ist ein einheitliches Ensemble -Rahmen für Pytorch, um die Leistung und Robustheit Ihres Deep -Lern -Modells zu verbessern.
Leicht ein Computer-Vision-Framework für das selbstbewertete Lernen.
Höher ist eine Bibliothek, die die Implementierung von willkürlich komplexen Gradienten-basierten Meta-Learning-Algorithmen und verschachtelten Optimierungsschleifen mit nahezu Vanilla-Pytorch erleichtert.
Horovod ist eine verteilte Trainingsbibliothek für Deep -Learning -Frameworks. Horovod zielt darauf ab, verteilte DL schnell und einfach zu bedienen.
Pennylane ist eine Bibliothek für Quanten-ML, automatische Differenzierung und Optimierung von hybriden quantenklassischen Berechnungen.
DETECTRON2 ist die Plattform der nächsten Generation von Fair für die Objekterkennung und -segmentierung.
Fastai ist eine Bibliothek, die das Training Fast und genaue neuronale Netze mit modernen Best Practices vereinfacht.
Zurück nach oben

TensorFlow ist eine End-to-End-Open-Source-Plattform für maschinelles Lernen. Es verfügt über ein umfassendes, flexibles Ökosystem aus Tools, Bibliotheken und Community-Ressourcen, mit dem die Forscher die hochmoderne in ML und Entwickler problemlos ML-Antriebsanwendungen erstellen und bereitstellen können.
Erste Schritte mit Tensorflow
TensorFlow-Tutorials
TensorFlow Developer Certificate | TensorFlow
Tensorflow Community
Tensorflow -Modelle und Datensätze
Tensorflow Cloud
Ausbildung für maschinelles Lernen | TensorFlow
Top TensorFlow -Kurse online | Coursera
Top TensorFlow -Kurse online | Udemy
Tiefes Lernen mit Tensorflow | Udemy
Tiefes Lernen mit Tensorflow | edX
Intro in TensorFlow für Deep Learning | Udacity
Intro to TensorFlow: Crashkurs für maschinelles Lernen | Google -Entwickler
Trainieren und bereitstellen ein TensorFlow -Modell - Azure Machine Learning
Wenden Sie maschinelle Lernmodelle in Azurefunktionen mit Python und Tensorflow | an | Microsoft Azure
Tiefes Lernen mit Tensorflow | Amazon Web Services (AWS)
Tensorflow - Amazon EMR | AWS -Dokumentation
TensorFlow Enterprise | Google Cloud
TensorFlow Lite ist ein Open -Source -Deep -Lern -Framework für die Bereitstellung maschineller Lernmodelle auf mobilen und IoT -Geräten.
TensorFlow.js ist eine JavaScript -Bibliothek, mit der Sie ML -Modelle in JavaScript entwickeln oder ausführen können und ML direkt auf der Browser -Clientseite, Serverseite über node.js, mobile native über React Native, Desktop Native über Elektron und sogar auf IoT verwenden können Geräte über node.js auf Raspberry pi.
TensorFlow_Macos ist eine von Mac-optimierte Version von TensorFlow- und TensorFlow-Addons für MacOS 11.0+, die mit dem ML-Rechens-Framework von Apple beschleunigt wurden.
Google Colaboratory ist eine kostenlose Jupyter -Notebook -Umgebung, für die kein Setup erforderlich ist und ausschließlich in der Cloud ausgeführt wird, sodass Sie den TensorFlow -Code in Ihrem Browser mit einem einzigen Klick ausführen können.
Was-wäre-wenn-Tool ist ein Tool für die codfreie Prüfung von maschinellen Lernmodellen, die für das Verständnis von Modellen, das Debuggen und die Fairness nützlich sind. Erhältlich in Tensorboard und Jupyter- oder Colab -Notizbüchern.
Tensorboard ist eine Reihe von Visualisierungstools, um TensorFlow -Programme zu verstehen, zu debuggen und zu optimieren.
Keras ist eine hochrangige neuronale Netzwerke-API, die in Python geschrieben wurde und in der Lage ist, auf Tensorflow, CNTK oder Theano zu laufen. Es ist in der Lage, auf Tensorflow, Microsoft Cognitive Toolkit, R, Theano oder Plaidml zu laufen.
XLA (beschleunigte lineare Algebra) ist ein domänenspezifischer Compiler für lineare Algebra, der Tensorflow-Berechnungen optimiert. Die Ergebnisse sind Verbesserungen in Geschwindigkeit, Speichernutzung und Portabilität auf Server- und Mobilfunkplattformen.
ML Perf ist eine breite ML -Benchmark -Suite zur Messung der Leistung von ML -Software -Frameworks, ML -Hardware -Beschleunigern und ML -Cloud -Plattformen.
TensorFlow Playground ist eine Entwicklungsumgebung, die mit einem neuronalen Netzwerk in Ihrem Browser herumbastelt.
TPU Research Cloud (TRC) ist ein Programm ermöglicht es Forschern, den Zugriff auf eine Cluster von mehr als 1.000 Cloud -TPUs ohne Ladung zu beantragen, um die nächste Welle von Forschungsbräumen zu beschleunigen.
MLIR ist eine neue Zwischendarstellung und ein Compiler -Rahmen.
Das Gitter ist eine Bibliothek für flexible, kontrollierte und interpretierbare ML-Lösungen mit Gewohnheitsverhältnissen.
TensorFlow Hub ist eine Bibliothek für wiederverwendbares maschinelles Lernen. Laden Sie die neuesten geschulten Modelle mit einer minimalen Menge an Code herunter und verwenden Sie sie wieder.
TensorFlow Cloud ist eine Bibliothek, in der Ihre lokale Umgebung mit Google Cloud verbunden wird.
Das TensorFlow -Modelloptimierungs -Toolkit ist eine Reihe von Tools zur Optimierung von ML -Modellen für die Bereitstellung und Ausführung.
TensorFlow Empfehlungen sind eine Bibliothek zum Erstellen von Empfehlungssystemmodellen.
Der TensorFlow-Text ist eine Sammlung von Klassen und OPs im Zusammenhang mit Text und NLP, die mit TensorFlow 2 verwendet werden können.
TensorFlow Graphics ist eine Bibliothek von Computergrafikfunktionen, die von Kameras, Lichtern und Materialien bis hin zu Renderern reichen.
TensorFlow Federated ist ein Open -Source -Framework für maschinelles Lernen und andere Berechnungen zu dezentralen Daten.
Die Tensorflow -Wahrscheinlichkeit ist eine Bibliothek für probabilistisches Denken und statistische Analyse.
Tensor2tensor ist eine Bibliothek von Deep -Learning -Modellen und Datensätzen, mit denen Deep -Lernen zugänglicher und ml -Forschung zugänglicher wird.
TensorFlow Privacy ist eine Python -Bibliothek, die Implementierungen von Tensorflow -Optimierern für die Schulung maschineller Lernmodelle mit unterschiedlicher Privatsphäre umfasst.
TensorFlow-Ranking ist eine Bibliothek für Lern-Rang-Techniken (Lern-to-Rank) auf der Tensorflow-Plattform.
Tensorflow Agents ist eine Bibliothek zum Verstärkungslernen im Tensorflow.
TensorFlow Addons ist ein Repository von Beiträgen, die gut etablierten API-Mustern entsprechen, aber neue Funktionen implementieren, die in Kernzensorflow nicht verfügbar sind, die von SIG-Addons aufrechterhalten werden. TensorFlow unterstützt nativ eine große Anzahl von Betreibern, Schichten, Metriken, Verlusten und Optimierern.
Die TensorFlow I/O ist ein Datensatz-, Streaming- und Dateisystemerweiterungen, der von SIG IO gepflegt wird.
Tensorflow Quantum ist eine Bibliothek für maschinelles Lernen für maschinelles Lernen für schnelle Prototypen von hybrid-quantenklassischen ML-Modellen.
Dopamin ist ein Forschungsrahmen für schnelle Prototypen von Verstärkungslernenalgorithmen.
TRFL ist eine Bibliothek für Verstärkungslernbausteine, die von DeepMind erstellt wurden.
Mesh Tensorflow ist eine Sprache für verteiltes Deep -Lernen, das eine breite Klasse verteilter Tensorberechnungen angeben kann.
Raggedtensors ist eine API, die es einfach macht, Daten mit ungleichmäßiger Form zu speichern und zu manipulieren, einschließlich Text (Wörter, Sätze, Zeichen) und Chargen mit variabler Länge.
Unicode OPS ist eine API, die die Arbeit mit Unicode -Text direkt im Tensorflow unterstützt.
Magenta ist ein Forschungsprojekt, das die Rolle des maschinellen Lernens bei der Schaffung von Kunst und Musik untersucht.
Nucleus ist eine Bibliothek mit Python- und C ++ - Code, mit denen Daten in gemeinsamen Genomik -Dateiformaten wie SAM und VCF gelesen, geschrieben und analysiert werden können.
Sonett ist eine Bibliothek von DeepMind für den Bau neuronaler Netzwerke.
Neuronales strukturiertes Lernen ist ein Lernrahmen, um neuronale Netzwerke zu schulen, indem strukturierte Signale zusätzlich zu Eingaben genutzt werden.
Die Modellsanierung ist eine Bibliothek, mit der Modelle erstellt und trainiert, die den Benutzer von Benutzern, die sich aus zugrunde liegenden Leistungsverzerrungen ergeben, reduziert oder beseitigt.
Fairness-Indikatoren sind eine Bibliothek, die eine einfache Berechnung der allgemein identifizierten Fairness-Metriken für Binär- und Multiclas-Klassifizierer ermöglicht.
Decision Forests ist ein hochmoderner Algorithmen zum Training, Servieren und Interpretieren von Modellen, die Entscheidungswälder für Klassifizierung, Regression und Rangliste verwenden.
Zurück nach oben

Core ML ist ein Apple -Framework für die Integration von maschinellen Lernmodellen in Apps, die auf Apple -Geräten ausgeführt werden (einschließlich iOS, WatchOS, MacOS und TVOS). Core ML führt ein öffentliches Dateiformat (.mlmodel) für eine breite Reihe von ML -Methoden vor, darunter tiefe neuronale Netzwerke (sowohl Faltungs- als auch wiederkehrende), Baumsensembles mit Boosting und verallgemeinerte lineare Modelle. Modelle in diesem Format können direkt über Xcode in Apps integriert werden.
Einführung in den Kern -ML
Integration eines Kern -ML -Modells in Ihre App
Kern -ML -Modelle
Kern -ML -API -Referenz
Kern -ML -Spezifikation
Apple Developer -Foren für Core ML
Top Core ML -Kurse online | Udemy
Top Core ML -Kurse online | Coursera
IBM Watson Services für Kern ML | IBM
Generieren Sie Kern -ML -Assets mit IBM Maximo Visual Inspection | IBM
Core ML Tools ist ein Projekt, das unterstützende Tools für die Konvertierung, Bearbeitung und Validierung von ML -ML -Modellen für Kernmls enthält.
Create ML ist ein Tool, das neue Möglichkeiten für maschinelles Lernmodelle auf Ihrem Mac bietet. Es nimmt die Komplexität aus dem Modelltraining heraus, während sie leistungsstarke Kern -ML -Modelle erzeugt.
TensorFlow_macos ist eine Mac-optimierte Version von Tensorfl


