bida
v0.9.4
pip install -U bida from bida import ChatLLM
llm = ChatLLM (
model_type = 'openai' , # 调用openai的chat模型
model_name = 'gpt-4' ) # 设定模型为:gpt-4,默认是gpt3.5
result = llm . chat ( "从1加到100等于多少?只计算奇数相加呢?" )
print ( result ) from bida import ChatLLM
llm = ChatLLM (
model_type = "baidu" , # 调用百度文心一言
stream_callback = ChatLLM . stream_callback_func ) # 使用默认的流式输出函数
llm . chat ( "你好呀,请问你是谁?" ) | Vorzeigeunternehmen | Modelltyp | Modellname | Ob unterstützt werden soll | veranschaulichen |
|---|---|---|---|---|
| OpenAI | Chatten | gpt-3.5, gpt-4 | √ | Unterstützt alle gpt3.5- und gpt4-Modelle |
| Textvervollständigung | text-davinci-003 | √ | Klassenmodell zur Textgenerierung | |
| Einbettungen | text-embedding-ada-002 | √ | vektorisiertes Modell | |
| Baidu-Wen Xin Yiyan | Chatten | Ernie-Bot, Ernie-Bot-Turbo | √ | Baidu kommerzielles Chat-Modell |
| Einbettungen | Einbettung_v1 | √ | Kommerzielles Vektorisierungsmodell von Baidu | |
| Gehostetes Modell | Verschiedene Open-Source-Modelle | √ | Für verschiedene von Baidu gehostete Open-Source-Modelle konfigurieren Sie diese bitte selbst mit dem Modellzugriffsprotokoll eines Drittanbieters. Weitere Informationen finden Sie im Abschnitt zum Modellzugriff weiter unten. | |
| Alibaba Cloud-Tongyi Qianwen | Chatten | qwen-v1, qwen-plus-v1, qwen-7b-chat-v1 | √ | Kommerzielle und Open-Source-Chat-Modelle von Alibaba Cloud |
| Einbettungen | Texteinbettung-v1 | √ | Kommerzielles Vektorisierungsmodell von Alibaba Cloud | |
| Gehostetes Modell | Verschiedene Open-Source-Modelle | √ | Für andere Arten von Open-Source-Modellen, die von Alibaba Cloud gehostet werden, konfigurieren Sie diese bitte selbst mithilfe des Alibaba Cloud-Modellzugriffsprotokolls von Drittanbietern. Weitere Informationen finden Sie im Abschnitt zum Modellzugriff weiter unten. | |
| MiniMax | Chatten | abab5, abab5.5 | √ | MiniMax kommerzielles Chat-Modell |
| Chat Pro | abab5.5 | √ | Das kommerzielle MiniMax-Chat-Modell, das den benutzerdefinierten Chatcompletion-Pro-Modus verwendet, unterstützt Konversationsszenarien für mehrere Personen und mehrere Bots, Beispielkonversationen, Rückgabeformatbeschränkungen, Funktionsaufrufe, Plug-Ins und andere Funktionen | |
| Einbettungen | embo-01 | √ | Kommerzielles MiniMax-Vektormodell | |
| Weisheit AI-ChatGLM | Chatten | ChatGLM-Pro, Std, Lite, Characterglm | √ | Zhipu AI kommerzielles Großmodell mit mehreren Versionen |
| Einbettungen | Texteinbettung | √ | Zhipu AI kommerzielles Textvektormodell | |
| iFlytek-Spark | Chatten | SparkDesk V1.5, V2.0 | √ | iFlytek Spark Cognitive großes Modell |
| Einbettungen | Einbettung | √ | iFlytek Spark-Textvektormodell | |
| SenseTime-RiRiXin | Chatten | nova-ptc-xl-v1, nova-ptc-xs-v1 | √ | SenseNova SenseTime täglich neues großes Modell |
| Baichuan-Geheimdienst | Chatten | baichuan-53b-v1.0.0 | √ | Baichuan 53B großes Modell |
| Tencent-Hunyuan | Chatten | Tencent Hunyuan | √ | Tencent Hunyuan großes Modell |
| Selbst bereitgestelltes Open-Source-Modell | Chat, Vervollständigung, Einbettungen | Verschiedene Open-Source-Modelle | √ | Unter Verwendung von Open-Source-Modellen, die von FastChat und anderen Bereitstellungen bereitgestellt werden, folgt die bereitgestellte Web-API-Schnittstelle OpenAI-kompatiblen RESTful-APIs und kann direkt unterstützt werden. Weitere Informationen finden Sie im folgenden Kapitel zum Modellzugriff. |
Beachten :
Die beiden Technologien Model LLM und Prompt Word in AIGC sind sehr neu und entwickeln sich rasant weiter. Der verwendete Technologie-Stack weist kaum Überschneidungen mit der Erfahrung aktueller Mainstream-Entwickler auf :
| Einstufung | Aktuelle Mainstream-Entwicklung | Schnelles Projekt | Modelle entwickeln, Modelle verfeinern |
|---|---|---|---|
| Entwicklungssprache | Java, .Net, Javascript, ABAP usw. | Natürliche Sprache, Python | Python |
| Entwicklungstools | Sehr viel und ausgereift | keiner | Reifen |
| Entwicklungsschwelle | niedriger und reifer | niedrig, aber sehr unreif | sehr hoch |
| Entwicklungstechnologie | klar und stabil | Der Einstieg ist einfach, aber es ist sehr schwierig, eine konstante Leistung zu erzielen | komplex und abwechslungsreich |
| Häufig verwendete Techniken | Objektorientiert, Datenbank, Big Data | Prompt-Tuning, Inkontext-Lernen, Einbettung | Transformator, RLHF, Feinabstimmung, LoRA |
| Open-Source-Unterstützung | reich und reif | Auf der unteren Ebene sehr verwirrend | reich, aber unreif |
| Entwicklungskosten | Niedrig | höher | sehr hoch |
| Entwickler | Reich | Extrem selten | sehr knapp |
| Entwickeln Sie ein Kooperationsmodell | Entwickeln Sie gemäß den vom Produktmanager bereitgestellten Dokumenten | Eine Person oder ein minimalistisches Team kann alle Vorgänge von der Anforderung bis zur Lieferung abwickeln | Entwickelt nach theoretischen Forschungsrichtungen |
Derzeit gehen fast alle Technologieunternehmen, Internetunternehmen und Big-Data-Unternehmen alle in diese Richtung, aber traditionellere Unternehmen befinden sich immer noch in einem Zustand der Verwirrung. Es ist nicht so, dass traditionelle Unternehmen es nicht brauchen, aber: 1) sie haben keine technischen Talentreserven und wissen daher nicht, was sie tun sollen; 2) sie haben keine Hardwarereserven, und das tun sie auch nicht die Fähigkeit dazu haben; 3) Der Grad der Geschäftsdigitalisierung ist gering und die AIGC-Transformation und -Aktualisierung hat einen langen Zyklus und langsame Ergebnisse.
Derzeit gibt es zu viele kommerzielle und Open-Source-Modelle im In- und Ausland, und die APIs und Datenobjekte der Modelle unterscheiden sich daher Neue Version), wir müssen die Entwicklungsdokumente lesen und Ihren eigenen Anwendungscode anpassen, um ihn anzupassen. Ich glaube, dass jeder Anwendungsentwickler viele Modelle getestet hat und darunter gelitten haben muss.
Obwohl die Modellfunktionen unterschiedlich sind, sind die Modi zur Bereitstellung von Funktionen im Allgemeinen dieselben. Daher ist es für viele Entwickler zu einem dringenden Bedarf geworden, über ein Framework zu verfügen, das sich an eine große Anzahl von Modell-APIs anpassen und einen einheitlichen Aufrufmodus bereitstellen kann.
Zunächst einmal soll Bida Langchain nicht ersetzen, aber auch seine Zielpositionierung und Entwicklungskonzepte sind sehr unterschiedlich:
| Einstufung | langchain | bida |
|---|---|---|
| Zielgruppe | Die gesamte Entwickler-Crowd in Richtung AIGC | Entwickler, die dringend AIGC mit Anwendungsentwicklung kombinieren müssen |
| Modellunterstützung | Unterstützt verschiedene Modelle für die lokale oder Remote-Bereitstellung | Es werden nur Modellaufrufe unterstützt, die eine Web-API bereitstellen. Derzeit können die meisten kommerziellen Modelle auch eine Web-API bereitstellen, nachdem sie mithilfe von Frameworks wie FastChat bereitgestellt wurden. |
| Rahmenstruktur | Da es viele Funktionen und eine sehr komplexe Struktur bietet, umfasst der Kerncode (Stand August 2023) mehr als 1.700 Dateien und 150.000 Codezeilen, und die Lernschwelle ist hoch. | Es gibt mehr als zehn Kerncodes und etwa 2.000 Codezeilen. Der Code ist relativ einfach zu erlernen und zu ändern. |
| Funktionsunterstützung | Bieten Sie eine vollständige Abdeckung verschiedener Modelle, Technologien und Anwendungsbereiche in Richtung AIGC | Derzeit bietet es Unterstützung für ChatCompletions, Completions, Embeddings, Function Call und andere Funktionen wie Sprache und Bild, die in naher Zukunft veröffentlicht werden. |
| Prompt | Es werden Eingabeaufforderungsvorlagen bereitgestellt, die von den eigenen Funktionen verwendeten Eingabeaufforderungen sind jedoch in den Code eingebettet, was das Debuggen und Ändern erschwert. | Derzeit gibt es keine integrierte Funktion zur Verwendung von Prompt. Bei zukünftiger Verwendung wird der konfigurationsbasierte Nachlademodus verwendet, um Benutzeranpassungen zu erleichtern. |
| Konversation und Erinnerung | Unterstützt und stellt mehrere Speicherverwaltungsmethoden bereit | Unterstützung, Unterstützung der Konversationspersistenz (in duckdb gespeichert), Speicher bietet begrenzte Archivierungssitzungsfunktionen und andere Funktionen können durch das Erweiterungsframework erweitert werden |
| Funktion & Plugin | Unterstützt und bietet umfangreiche Erweiterungsmöglichkeiten, der Nutzungseffekt hängt jedoch von den eigenen Fähigkeiten des großen Modells ab | Kompatibel mit großen Modellen, die die Function Call-Spezifikation von OpenAI verwenden |
| Agent & Kette | Unterstützt und bietet umfangreiche Erweiterungsmöglichkeiten, der Nutzungseffekt hängt jedoch von den eigenen Fähigkeiten des großen Modells ab | Wird nicht unterstützt, planen wir, ein weiteres Projekt zu eröffnen, um es umzusetzen, oder wir können es auf der Grundlage des aktuellen Frameworks selbst erweitern und weiterentwickeln. |
| Andere Funktionen | Unterstützt viele andere Funktionen, wie z. B. die Dokumentenaufteilung (die Einbettung erfolgt nach der Aufteilung und wird zur Implementierung von ChatPDF und anderen ähnlichen Funktionen verwendet). | Derzeit gibt es keine weiteren Funktionen, die durch Öffnen eines neuen kompatiblen Projekts implementiert werden können. Derzeit können sie mit der Kombination der von anderen Produkten bereitgestellten Funktionen implementiert werden. |
| Betriebseffizienz | Viele Entwickler berichten, dass es langsamer ist als der direkte Aufruf der API, und der Grund ist unbekannt. | Es kapselt nur den aufrufenden Prozess und vereinheitlicht die aufrufende Schnittstelle. Die Leistung unterscheidet sich nicht vom direkten Aufruf der API. |
Als führendes Open-Source-Projekt in der Branche hat langchain einen großen Beitrag zur Förderung großer Modelle und AGI geleistet. Gleichzeitig haben wir bei der Entwicklung auf viele seiner Modelle und Ideen zurückgegriffen bida. Langchain möchte jedoch ein großes und umfassendes Tool sein, was zwangsläufig zu vielen Mängeln führt. Die folgenden Artikel vertreten ähnliche Meinungen: Max Woolf – Chinesisch, Hacker News – Chinesisch.
Ein beliebtes Sprichwort in der Szene bringt es sehr gut auf den Punkt: Langchain ist ein Lehrbuch, das jeder lernt, aber irgendwann wegwirft.
Installieren Sie die neueste Bida von Pip oder Pip3
pip install -U bidaKlonen Sie den Projektcode von Github in das lokale Verzeichnis:
git clone https://github.com/pfzhou/bida.git
pip install -r requirements.txtÄndern Sie die Datei im aktuellen Code-Stammverzeichnis: Die Erweiterung „.env.template“ wird zur Umgebungsvariablendatei „.env“ . Bitte konfigurieren Sie den Schlüssel des verwendeten Modells gemäß den Anweisungen in der Datei.
Bitte beachten Sie : Diese Datei wurde zur Ignorierliste hinzugefügt und wird nicht an den Git-Server übertragen.
Beispiele1.Initialisierungsumgebung.ipynb
Der folgende Demonstrationscode verwendet eine Vielzahl von Modellen, die von bida unterstützt werden. Bitte ändern Sie den Wert **[model_type]** im Code entsprechend dem von Ihnen gekauften Modell für Erfahrung:
# 更多信息参看bidamodels*.json中的model_type配置
# openai
llm = ChatLLM ( model_type = "openai" )
# baidu
llm = ChatLLM ( model_type = "baidu" )
# baidu third models(llama-2...)
llm = ChatLLM ( model_type = "baidu-third" )
# aliyun
llm = ChatLLM ( model_type = "aliyun" )
# minimax
llm = ChatLLM ( model_type = "minimax" )
# minimax ccp
llm = ChatLLM ( model_type = "minimax-ccp" )
# zhipu ai
llm = ChatLLM ( model_type = "chatglm2" )
# xunfei xinghuo
llm = ChatLLM ( model_type = "xfyun" )
# senstime
llm = ChatLLM ( model_type = "senstime" )
# baichuan ai
llm = ChatLLM ( model_type = "baichuan" )
# tencent ai
llm = ChatLLM ( model_type = "tencent" )Chat-Modus: ChatCompletion, der aktuelle Mainstream-LLM-Interaktionsmodus, unterstützt Sitzungsverwaltung, Persistenz und Speicherverwaltung.
from bida import ChatLLM
llm = ChatLLM ( model_type = 'baidu' )
result = llm . chat ( "你好呀,请问你是谁?" )
print ( result ) from bida import ChatLLM
# stream调用
llm = ChatLLM ( model_type = "baidu" , stream_callback = ChatLLM . stream_callback_func )
result = llm . chat ( "你好呀,请问你是谁?" ) from bida import ChatLLM
llm = ChatLLM ( model_type = "baidu" , stream_callback = ChatLLM . stream_callback_func )
result = llm . chat ( "你是一个服务助理,请简洁回答我的问题。我的名字是老周。" )
result = llm . chat ( "我的名字是?" )Den obigen detaillierten Code und weitere Funktionsbeispiele finden Sie im folgenden NoteBook:
Beispiele2.1.Chat mode.ipynb
Erstellen Sie einen Chatbot mit Farbverlauf
Gradio ist ein sehr beliebtes Schnittstellen-Framework für die Verarbeitung natürlicher Sprache
bida + grario kann mit nur wenigen Codezeilen eine nutzbare Anwendung erstellen
import gradio as gr
from bida import ChatLLM
llm = ChatLLM ( model_type = 'openai' )
def predict ( message , history ):
answer = llm . chat ( message )
return answer
gr . ChatInterface ( predict ). launch ()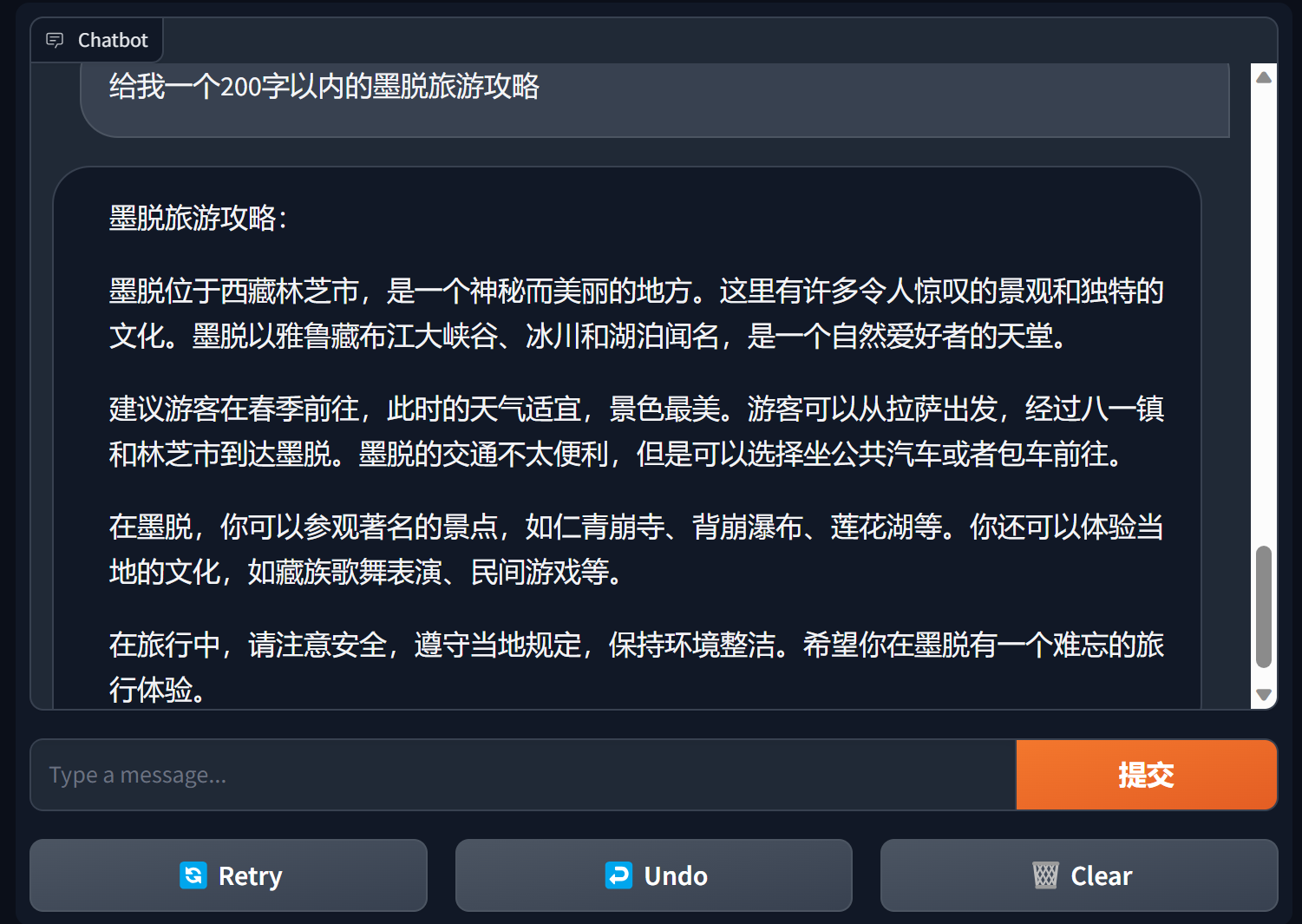
Weitere Informationen finden Sie in der Chatbot-Demo von bida+gradio
Abschlussmodus: Completions oder TextCompletions, der LLM-Interaktionsmodus der vorherigen Generation, unterstützen nur Einzelgespräche, speichern keine Chat-Datensätze und jeder Anruf ist eine neue Kommunikation.
Bitte beachten Sie: Im Artikel von OpenAI vom 6. Juli 2023 wurde klargestellt, dass dieses Modell im Grunde genommen nicht mehr verfügbar ist. Selbst unterstützte Modelle folgen voraussichtlich OpenAI und werden voraussichtlich schrittweise auslaufen Zukunft. .
from bida import TextLLM
llm = TextLLM ( model_type = "openai" )
result = llm . completion ( "你是一个服务助理,请简洁回答我的问题。我的名字是老周。" )
print ( result )Einzelheiten zum Beispielcode finden Sie unter:
Beispiele2.2.Completion mode.ipynb
Das Prompt-Wort Prompt ist die wichtigste Funktion im großen Sprachmodell. Es untergräbt das traditionelle objektorientierte Entwicklungsmodell und transformiert es in: Prompt-Projekt . Dieses Framework wird mithilfe von „Prompt Templete“ implementiert, das Funktionen wie das Ersetzen von Tags, das Festlegen verschiedener Eingabeaufforderungswörter für mehrere Modelle und das automatische Ersetzen unterstützt, wenn das Modell eine Interaktion durchführt.
PromptTemplate_Text wird derzeit bereitgestellt: unterstützt die Verwendung von Zeichenfolgentext zum Generieren von Prompt-Vorlagen, bida unterstützt auch flexible benutzerdefinierte Vorlagen und plant, in Zukunft die Möglichkeit bereitzustellen, Vorlagen aus JSON und Datenbanken zu laden.
Detaillierten Beispielcode finden Sie in der folgenden Datei:
Beispiele2.3.Prompt prompt word.ipynb
Wichtige Hinweise in den Aufforderungsworten
Im Allgemeinen wird empfohlen, dass Aufforderungswörter einer dreiteiligen Struktur folgen: Rollen festlegen, Aufgaben klären und Kontext angeben (zugehörige Informationen oder Beispiele) . Sie können sich auf die Schreibmethode in den Beispielen beziehen.
Andrew Ngs Kursreihe https://learn.deeplearning.ai/login, chinesische Version, Interpretation
Openai-Kochbuch https://github.com/openai/openai-cookbook
Microsoft Azure-Dokumentation: Einführung in Tip Engineering, Tip Engineering-Technologie
Der beliebteste Prompt Engineering Guide auf Github, chinesische Version
Funktionsaufruf ist eine Funktion, die am 13. Juni 2023 von OpenAI veröffentlicht wurde. Wir alle wissen, dass die von ChatGPT trainierten Daten auf Daten aus der Zeit vor 2021 basieren. Wenn Sie Fragen zu Echtzeit stellen, können wir Ihnen keine Antwort geben und funktionieren Anrufe ermöglichen den Echtzeit-Abruf von Netzwerkdaten, z. B. die Überprüfung von Wettervorhersagen, die Überprüfung von Lagerbeständen, die Empfehlung aktueller Filme usw.
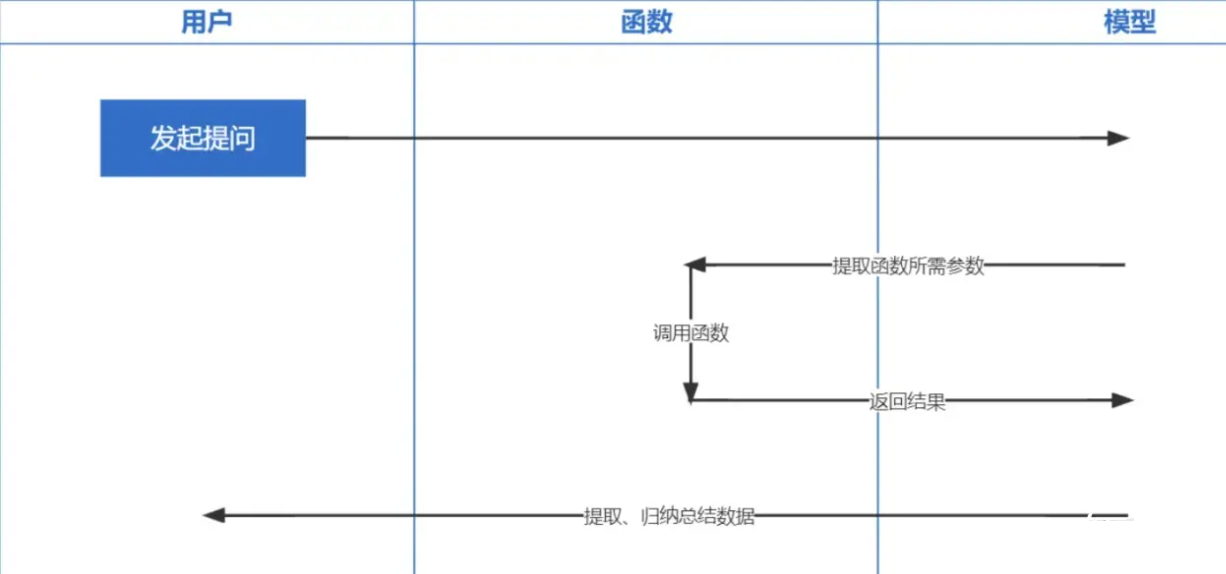
Die Einbettungstechnologie ist die wichtigste Technologie zur Implementierung von Prompt inContext Learning und stellt im Vergleich zum vorherigen Schlüsselwortabruf einen weiteren Schritt nach vorne dar.
Hinweis : Die Dateneinbettung aus verschiedenen Modellen ist nicht universell, daher muss beim Abruf das gleiche Modell für die Einbettung der Frage verwendet werden.
| Modellname | Ausgabedimensionen | Anzahl der Chargenprotokolle | Limit für einzelne Text-Token |
|---|---|---|---|
| OpenAI | 1536 | Keine Begrenzung | 8191 |
| Baidu | 384 | 16 | 384 |
| Ali | 1536 | 10 | 2048 |
| MiniMax | 1536 | Keine Begrenzung | 4096 |
| Weisheitsspektrum KI | 1024 | Einzel | 512 |
| iFlytek Spark | 1024 | Einzel | 256 |
Hinweis: Die Einbettungsschnittstelle von bida unterstützt die Stapelverarbeitung. Wenn das Stapelverarbeitungslimit des Modells überschritten wird, wird es automatisch stapelweise verarbeitet und zusammen zurückgegeben. Wenn der Inhalt eines einzelnen Textstücks die begrenzte Anzahl von Token überschreitet, melden einige je nach Logik des Modells einen Fehler und andere kürzen ihn.
Ausführliche Beispiele finden Sie unter: examples2.6.Embeddingsembeddingmodel.ipynb
├─bida # bida框架主目录
│ ├─core # bida框架核心代码
│ ├─functions # 自定义function文件
│ ├─ *.json # function定义
│ ├─ *.py # 对应的调用代码
│ ├─models # 接入模型文件
│ ├─ *.json # 模型配置定义:openai.json、baidu.json等
│ ├─ *_api.py # 模型接入代码:openai_api.py、baidu_api.py等
│ ├─ *_sdk.py # 模型sdk代码:baidu_sdk.py等
│ ├─prompts # 自定义prompt模板文件
│ ├─*.py # 框架其他代码文件
├─docs # 帮助文档
├─examples # 演示代码、notebook文件和相关数据文件
├─test # pytest测试代码
│ .env.template # .env的模板
│ LICENSE # MIT 授权文件
│ pytest.ini # pytest配置文件
│ README.md # 本说明文件
│ requirements.txt # 相关依赖包
Wir hoffen, uns an weitere Modelle anpassen zu können und freuen uns über Ihre wertvollen Meinungen, um Entwicklern gemeinsam bessere Produkte anbieten zu können!


