Tutorbot Spock
1.0.0
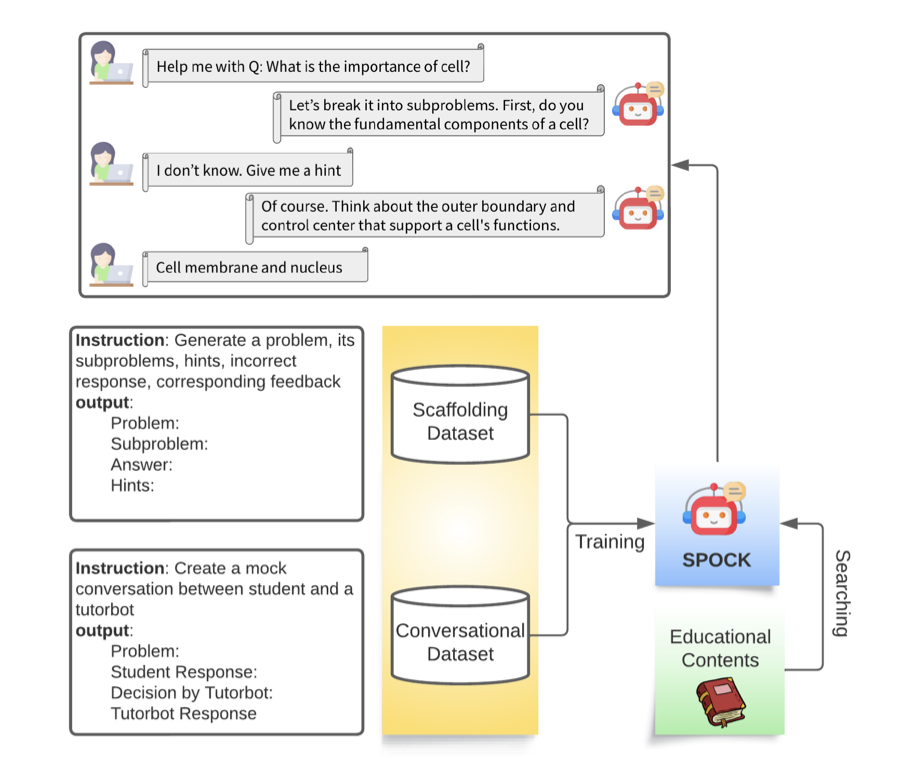
KLASSE: Ein Design-Framework für den Aufbau intelligenter Nachhilfesysteme basierend auf lernwissenschaftlichen Prinzipien (EMNLP 2023)
Shashank Sonkar, Naiming Liu, Debshila Basu Mallick, Richard G. Baraniuk
Papier: https://arxiv.org/abs/2305.13272
Branche: KLASSE
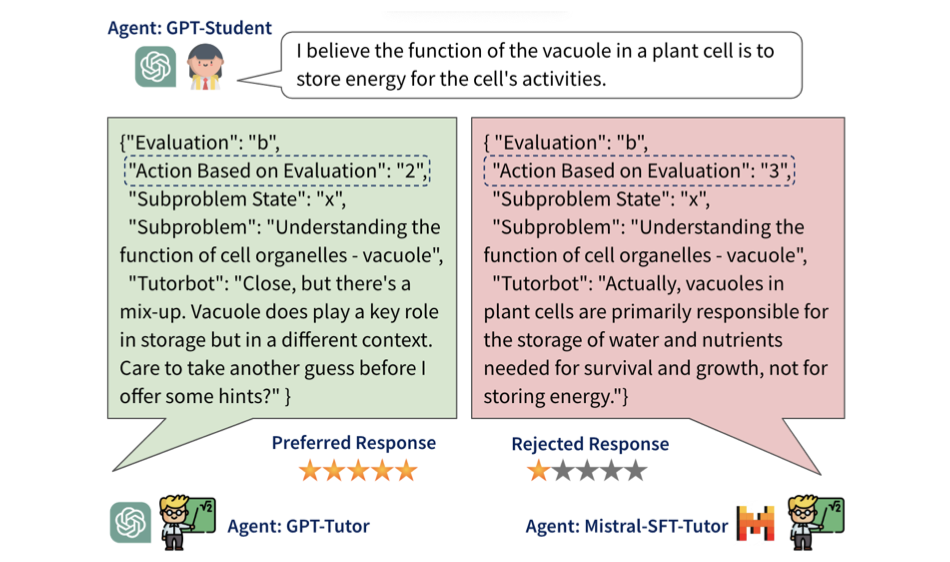
Pädagogische Ausrichtung großer Sprachmodelle (EMNLP 2024)
Shashank Sonkar*, Kangqi Ni*, Sapana Chaudhary, Richard G. Baraniuk
Papier: https://arxiv.org/abs/2402.05000
Zweig: Hauptzweig
Dieses Repo zielt darauf ab, effektive intelligente Nachhilfeagenten zu entwickeln, die den Schülern helfen, kritisches Denken und Fähigkeiten zur Problemlösung zu entwickeln.
Sehen Sie sich bitte scripts/run.sh als Beispiel an, das das Training und die Evaluierung eines ausgewählten Modells mit 4*A100-GPUs ausführt. Um dieses Beispiel ohne Training auszuführen, laden Sie die Modelle aus dem folgenden Abschnitt herunter und lesen Sie scripts/run_no-train.sh . In den folgenden Unterabschnitten wird scripts/run.sh mit detaillierteren Erklärungen aufgeschlüsselt.
Für das Training und die Auswertung werden bio-dataset-1.json, bio-dataset-2.json, bio-dataset-3.json und bio-dataset-ppl.json aus dem Datensatzordner verwendet. Jedes enthält Scheingespräche zwischen einem Studenten und einem Tutor, die auf Biologiekonzepten basieren, die aus GPT-4 von OpenAI generiert wurden. Diese Daten werden dann in die erforderlichen Formate für Trainings- und Bewertungsdatensätze vorverarbeitet. Anweisungen zur Generierung dieser Daten finden Sie im Zweig CLASS.
Legen Sie die Benutzerparameter fest:
FULL_MODEL_PATH="meta-llama/Meta-Llama-3.1-8B-Instruct"
MODEL_DIR="models"
DATA_DIR="datasets"
SFT_OPTION="transformers" # choices: ["transformers", "fastchat"]
ALGO="dpo" # choices: ["dpo", "ipo", "kto"]
BETA=0.1 # choices: [0.0 - 1.0]
Daten vorverarbeiten:
python src/preprocess_sft_data.py --data_dir $DATA_DIR
Wir bieten 2 Optionen für SFT: (1) Transformers (2) FastChat.
(1) SFT mit Transformern ausführen:
CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --nproc_per_node=4 --master_port=20001 src/train/train_sft.py
--model_path $FULL_MODEL_PATH
--train_dataset_path $SFT_DATASET_PATH
--eval_dataset_path ${DATA_DIR}/bio-test.json
--output_dir $SFT_MODEL_PATH
--cache_dir cache
--bf16
--num_train_epochs 3
--per_device_train_batch_size 2
--per_device_eval_batch_size 1
--gradient_accumulation_steps 2
--evaluation_strategy "epoch"
--eval_accumulation_steps 50
--save_strategy "epoch"
--seed 42
--learning_rate 2e-5
--weight_decay 0.05
--warmup_ratio 0.1
--lr_scheduler_type "cosine"
--logging_steps 1
--max_seq_length 4096
--gradient_checkpointing
(2) SFT mit FastChat ausführen:
CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --nproc_per_node=4 --master_port=20001 FastChat/fastchat/train/train.py
--model_name_or_path $FULL_MODEL_PATH
--data_path $SFT_DATASET_PATH
--eval_data_path ${DATA_DIR}/bio-test.json
--output_dir $SFT_MODEL_PATH
--cache_dir cache
--bf16 True
--num_train_epochs 3
--per_device_train_batch_size 2
--per_device_eval_batch_size 1
--gradient_accumulation_steps 2
--evaluation_strategy "epoch"
--eval_accumulation_steps 50
--save_strategy "epoch"
--seed 42
--learning_rate 2e-5
--weight_decay 0.05
--warmup_ratio 0.1
--lr_scheduler_type "cosine"
--logging_steps 1
--tf32 True
--model_max_length 4096
--gradient_checkpointing True
Präferenzdaten generieren:
CUDA_VISIBLE_DEVICES=0,1,2,3 python src/evaluate/generate_responses.py --model_path $SFT_MODEL_PATH --output_dir ${SFT_MODEL_PATH}/final_checkpoint-dpo --test_dataset_path $DPO_DATASET_PATH --batch_size 256
python src/preprocess/preprocess_dpo_data.py --response_file ${SFT_MODEL_PATH}/final_checkpoint-dpo/responses.csv --data_file $DPO_PREF_DATASET_PATH
Führen Sie die Präferenzausrichtung aus:
DPO_MODEL_PATH="${MODEL_DIR}_dpo/${MODEL_NAME}_bio-tutor_${ALGO}"
CUDA_VISIBLE_DEVICES=0,1,2,3 accelerate launch --config_file=ds_config/deepspeed_zero3.yaml --num_processes=4 train/train_dpo.py
--train_data $DPO_PREF_DATASET_PATH
--model_path $SFT_MODEL_PATH
--output_dir $DPO_MODEL_PATH
--beta $BETA
--loss $ALGO
--gradient_checkpointing
--bf16
--gradient_accumulation_steps 4
--per_device_train_batch_size 2
--num_train_epochs 3
Bewerten Sie die Genauigkeit und F1-Scores von SFT- und Aligned-Modellen:
# Generate responses from the SFT model
CUDA_VISIBLE_DEVICES=0,1,2,3 python src/evaluate/generate_responses.py --model_path $SFT_MODEL_PATH --output_dir ${SFT_MODEL_PATH}/final_checkpoint-eval --test_dataset_path $TEST_DATASET_PATH --batch_size 256
# Generate responses from the Aligned model
CUDA_VISIBLE_DEVICES=0,1,2,3 python src/evaluate/generate_responses.py --model_path $DPO_MODEL_PATH --output_dir ${DPO_MODEL_PATH}/final_checkpoint-eval --test_dataset_path $TEST_DATASET_PATH --batch_size 256
# Evaluate the SFT model
echo "Metrics of the SFT Model:"
python src/evaluate/evaluate_responses.py --response_file ${SFT_MODEL_PATH}/final_checkpoint-eval/responses.csv
# Evaluate the Aligned model
echo "Metrics of the RL Model:"
python src/evaluate/evaluate_responses.py --response_file ${DPO_MODEL_PATH}/final_checkpoint-eval/responses.csv
Bewerten Sie die Anzahl der SFT- und Aligned-Modelle:
CUDA_VISIBLE_DEVICES=0,1 python src/evaluate/evaluate_ppl.py --model_path $SFT_MODEL_PATH
CUDA_VISIBLE_DEVICES=0,1 python src/evaluate/evaluate_ppl.py --model_path $DPO_MODEL_PATH
Um den Zugriff auf die Modelle zu erleichtern, laden Sie sie von Hugging Face herunter.
SFT-Modelle:
Ausgerichtete Modelle:
Wenn Sie unsere Arbeit nützlich finden, zitieren Sie bitte:
@misc{sonkar2023classdesignframeworkbuilding,
title={CLASS: A Design Framework for building Intelligent Tutoring Systems based on Learning Science principles},
author={Shashank Sonkar and Naiming Liu and Debshila Basu Mallick and Richard G. Baraniuk},
year={2023},
eprint={2305.13272},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2305.13272},
}
@misc{sonkar2024pedagogical,
title={Pedagogical Alignment of Large Language Models},
author={Shashank Sonkar and Kangqi Ni and Sapana Chaudhary and Richard G. Baraniuk},
year={2024},
eprint={2402.05000},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2402.05000},
}


