mengzi retrieval lm
1.0.0
Bei Langboat Technology konzentrieren wir uns auf die Verbesserung vorab trainierter Modelle, um sie leichter zu machen und den tatsächlichen Anforderungen der Industrie gerecht zu werden. Ein abrufbasierter Ansatz (wie RETRO, REALM und RAG) ist entscheidend, um dieses Ziel zu erreichen.
Dieses Repository ist eine experimentelle Implementierung des abrufgestützten Sprachmodells. Derzeit wird die Retrieval-Anpassung nur auf GPT-Neo unterstützt.
Wir haben Huggingface Transformers und lm-evaluation-harness gespalten, um Abrufunterstützung hinzuzufügen. Der Indexierungsteil ist als HTTP-Server implementiert, um Abruf und Training besser zu entkoppeln.
Der größte Teil der Modellimplementierung wird von RETRO-pytorch und GPT-Neo kopiert. Wir verwenden transformers-cli um ein neues Modell namens Re_gptForCausalLM basierend auf GPT-Neo hinzuzufügen und ihm dann einen Abrufteil hinzuzufügen.
Wir haben das auf EleutherAI/gpt-neo-125M angepasste Modell mithilfe der 200G-Abrufbibliothek hochgeladen.
Sie können ein Modell wie folgt initialisieren:
from transformers import Re_gptForCausalLM
model = Re_gptForCausalLM . from_pretrained ( 'Langboat/ReGPT-125M-200G' )Und bewerten Sie das Modell wie folgt:
python main.py
--model retrieval
--model_args pretrained=model_path
--device 0
--tasks wikitext,lambada,winogrande,mathqa,pubmedqa
--batch_size 1Wir berechnen die Ähnlichkeit mithilfe der Einbettung von sent_transformers als Textdarstellung. Sie können ein Satz-BERT-Modell wie folgt initialisieren:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer ( 'all-MiniLM-L12-v2' )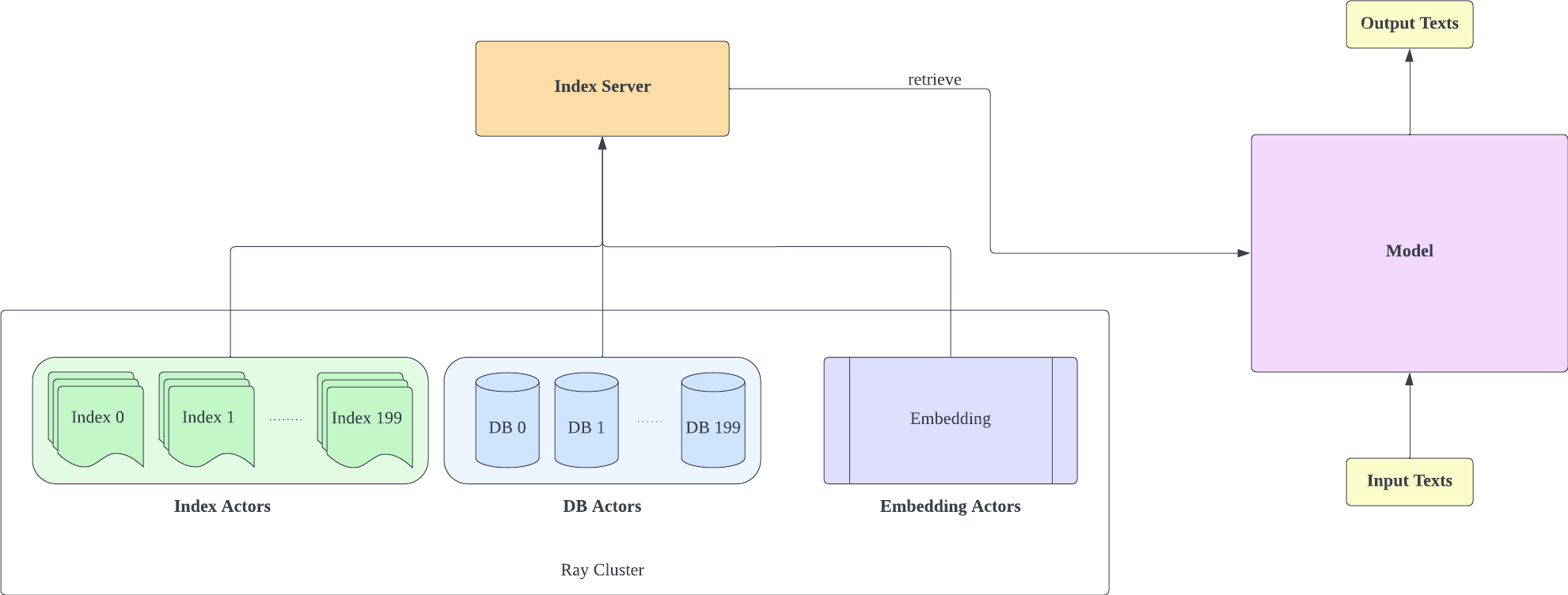
conda create -n mengzi-retrieval-fit python=3.7
conda activate mengzi-retrieval-fit
conda install pytorch torchvision torchaudio cudatoolkit=11.1 -c pytorch-lts -c nvidia
git clone https://github.com/Langboat/mengzi-retrieval-lm.git
cd mengzi-retrieval-lm
git submodule update --init --recursive
pip install -r requirement.txt
cd transformers/
pip install -e .
cd ..
python -c " from sentence_transformers import SentenceTransformer; model = SentenceTransformer('all-MiniLM-L12-v2') " Mit IVF1024PQ48 als Faiss-Indexfabrik haben wir den Index und die Datenbank auf den Huggingface-Modellhub hochgeladen, der mit dem folgenden Befehl heruntergeladen werden kann.
In download_index_db.py können Sie die Anzahl der Indizes und Datenbanken angeben, die Sie herunterladen möchten.
python -u download_index_db.py --num 200Sie können das angepasste Modell hier manuell herunterladen: https://huggingface.co/Langboat/ReGPT-125M-200G
Der Indexserver basiert auf FastAPI und Ray. Mit Ray's Actor werden rechenintensive Aufgaben asynchron gekapselt, sodass wir CPU- und GPU-Ressourcen mit nur einer FastAPI-Serverinstanz effizient nutzen können. Sie können einen Indexserver wie folgt initialisieren:
cd index-server/
ray start --head
python -u api.py
--config config_IVF1024PQ48.json
--db_path ../db/models—Langboat—Pile-DB/snapshots/fd35bcce75db5c1b7385a28018029f7465b4e966
- Beachten Sie, dass die Shard-Anzahl der Konfiguration IVF1024PQ48.json mit der Anzahl der heruntergeladenen Indizes übereinstimmen muss. Sie können die aktuell heruntergeladene Indexnummer unter db_path anzeigen
- Diese Konfiguration wurde auf dem A100-40G getestet. Wenn Sie also eine andere GPU haben, empfehlen wir, diese an Ihre Hardware anzupassen.
- Nach der Bereitstellung des Indexservers müssen Sie den request_server in lm-evaluation-harness/config.json und train/config.json ändern.
- Sie können den Encoder_actor_count in config_IVF1024PQ48.json reduzieren, um die erforderlichen Speicherressourcen zu reduzieren.
· db_path: Der Download-Speicherort der Datenbank von Huggingface. „../db/models – Langboat – Pile-DB/snapshots/fd35bcce75db5c1b7385a28018029f7465b4e966“ ist ein Beispiel.
Dieser Befehl lädt die Datenbank- und Indexdaten von Huggingface herunter.
Ändern Sie den Indexordner in der Konfigurationsdatei (config IVF1024PQ48), sodass er auf den Pfad des Indexordners verweist, und senden Sie die Snapshots des Datenbankordners als Datenbankpfad an das api.py-Skript.
Stoppen Sie den Indexserver mit dem folgenden Befehl
ray stop
- Beachten Sie, dass Sie den Indexserver während des Trainings, der Evaluierung und der Inferenz aktiviert lassen müssen
Verwenden Sie train/train.py, um das Training zu implementieren. train/config.json kann geändert werden, um die Trainingsparameter zu ändern.
Sie können das Training wie folgt initialisieren:
cd train
python -u train.py
- Da der Indexserver Speicherressourcen nutzen muss, sollten Sie den Indexserver und das Modelltraining besser auf verschiedenen GPUs bereitstellen
Verwenden Sie train/inference.py als Schlussfolgerung, um den Verlust eines Textes und seine Verwirrung zu bestimmen.
cd train
python -u inference.py
--model_path Langboat/ReGPT-125M-200G
--file_name data/test_data.json
- test_data.json und train_data.json im Datenordner sind derzeit unterstützte Dateiformate. Sie können Ihre Daten in dieses Format ändern.
Verwenden Sie lm-evaluation-harness als Bewertungsmethode
Wir setzen die seq_len des lm-evaluation-harness auf 1025 als Anfangseinstellung für den Modellvergleich, da die seq_len unseres Modelltrainings 1025 ist.
cd lm-evaluation-harness
python setup.py installpython main.py
--model retrieval
--model_args pretrained=Langboat/ReGPT-125M-200G
--device 0
--tasks wikitext
--batch_size 1· model_path: der passende Modellpfad
python main.py
--model gpt2
--model_args pretrained=EleutherAI/gpt-neo-125M
--device 0
--tasks wikitext
--batch_size 1Die Ergebnisse der Bewertung sind wie folgt
| Modell | Wikitext word_perplexity |
|---|---|
| EleutherAI/gpt-neo-125M | 35.8774 |
| Langboot/ReGPT-125M-200G | 22.115 |
| EleutherAI/gpt-neo-1.3B | 17.6979 |
| Langboot/ReGPT-125M-400G | 14.1327 |
@software { mengzi-retrieval-lm-library ,
title = { {Mengzi-Retrieval-LM} } ,
author = { Wang, Yulong and Bo, Lin } ,
url = { https://github.com/Langboat/mengzi-retrieval-lm } ,
month = { 9 } ,
year = { 2022 } ,
version = { 0.0.1 } ,
}

