CDial GPT
1.0.0
Dieses Projekt stellt einen umfangreichen chinesischen Konversationsdatensatz und ein chinesisches Konversations-Vortrainingsmodell (chinesisches GPT-Modell) für diesen Datensatz bereit. Weitere Informationen finden Sie in unserem Artikel.
Der Code dieses Projekts wurde von TransferTransfo modifiziert und verwendet die HuggingFace Pytorch-Version der Transformers-Bibliothek, die zum Vortraining und zur Feinabstimmung verwendet werden kann.
from datasets import load_dataset
dataset = load_dataset ( "lccc" , "base" ) # or "large" Der von uns bereitgestellte Datensatz LCCC (Large-scale Cleaned Chinese Conversation) besteht hauptsächlich aus zwei Teilen: LCCC-base (Baidu Netdisk, Google Drive) und LCCC-large (Baidu Netdisk, Google Drive). Wir haben einen strengen Datenfilterprozess entwickelt Stellen Sie die Qualität der Konversationsdaten in diesem Datensatz sicher. Dieser Datenfilterprozess umfasst eine Reihe manueller Regeln und mehrere Klassifikatoren, die auf Algorithmen des maschinellen Lernens basieren. Zu den Geräuschen, die wir herausfiltern, gehören: Schimpfwörter, Sonderzeichen, Gesichtsausdrücke, grammatikalisch falsche Sätze, kontextirrelevante Dialoge usw.
Die Statistiken dieses Datensatzes sind in der folgenden Tabelle aufgeführt. Unter diesen bezeichnen wir einen Dialog mit nur zwei Sätzen als „Single-Turn-Dialog“ und einen Dialog mit mehr als zwei Sätzen als „Multi-Turn-Dialog“. Verwenden Sie die Jieba-Wortsegmentierung, wenn Sie die Größe der Wortliste zählen.
| LCCC-Basis (Baidu Cloud Disk, Google Drive) | Gespräch in einer Runde | Mehrere Dialogrunden |
|---|---|---|
| totaler Dialog dreht sich | 3.354.232 | 3.466.274 |
| Gesamte Dialogsätze | 6.708.464 | 13.365.256 |
| Gesamtzahl der Zeichen | 68.559.367 | 163.690.569 |
| Wortschatzgröße | 372.063 | 666.931 |
| Durchschnittliche Wortanzahl in Konversationssätzen | 6,79 | 8.32 |
| Durchschnittliche Anzahl Sätze pro Gesprächsrunde | 2 | 3,86 |
Beachten Sie, dass der Reinigungsprozess des LCCC-Basisdatensatzes strenger ist als der von LCCC-groß, sodass seine Größe auch kleiner ist.
| LCCC-groß (Baidu Cloud Disk, Google Drive) | Gespräch in einer Runde | Mehrere Dialogrunden |
|---|---|---|
| totaler Dialog dreht sich | 7.273.804 | 4.733.955 |
| Gesamte Dialogsätze | 14.547.608 | 18.341.167 |
| Gesamtzahl der Zeichen | 162.301.556 | 217.776.649 |
| Wortschatzgröße | 662.514 | 690.027 |
| Anzahl der Bewertungswörter für Konversationssätze | 7.45 | 8.14 |
| Durchschnittliche Anzahl Sätze pro Gesprächsrunde | 2 | 3,87 |
Die ursprünglichen Konversationsdaten im LCCC-Basisdatensatz stammen aus Weibo-Konversationen, und die ursprünglichen Konversationsdaten im LCCC-großen Datensatz werden in andere Open-Source-Konversationsdatensätze integriert, die auf diesen Weibo-Konversationen basieren:
| Datensatz | totaler Dialog dreht sich | Gesprächsbeispiel |
|---|---|---|
| Weibo-Korpus | 79M | F: Ich habe sieben oder acht Mal Hot Pot in Chengdu, Chongqing, gegessen. A: Hahahaha! Dann könnte mein Mund verfaulen! |
| PTT-Klatschkorpus | 0,4 Mio | F: Warum schikanieren Dorfbewohner immer High-School-Schüler? FQ A: Wenn Sie denken, dass Sie zu Bill Gates werden, wenn Sie ein gutes Fach wählen, dann können Sie genauso gut die Schule abbrechen. |
| Untertitelkorpus | 2,74 Mio | F: Die Menschen in der Peking-Oper sind nicht frei. A: Sie sperren die Menschen in Käfige. |
| Xiaohuangji-Korpus | 0,45 Mio | F: Waren Sie jemals verliebt? A: Waren Sie jemals verliebt? Oh, erwähnen Sie es nicht, ich bin traurig ... |
| Tieba-Korpus | 2,32 Mio | F: Erste Reihe, alle Lu-Fans stehen auf, oder? A: Im Titel steht „Vorlagen“, aber nachdem man den Ball gesehen hat, ist das wirklich eine lebendige Ironie. |
| Qingyun-Korpus | 0,1 Mio | F: Offenbar liebst du Geld sehr. A: Oh, wirklich? Dann haben Sie es fast geschafft |
| Douban-Konversationskorpus | 0,5 Mio | F: Lernen Sie reines Englisch, indem Sie sich englische Originalfilme ansehen. A: Ich liebe „Friends“ und habe es mir schon oft angeschaut. F: Ich bin fast erschöpft, wenn ich mir die gleiche CD anschaue. A: Dann sollten Ihre Englischkenntnisse jetzt ziemlich gut sein |
| E-kommerzielles Konversationskorpus | 0,5 Mio | F: Wird das ein gutes Angebot sein? A: Wird es in Zukunft verfügbar sein? A: Bitte achten Sie darauf. |
| Chinesischer Chat-Korpus | 0,5 Mio | F: Meine Beine sind heute nutzlos, also werde ich Steine bewegen. A: Es ist sogar harte Arbeit, um an Weihnachten viel Geld zu verdienen Ich habe keinen Freund, also ist jeder Urlaub gleich. |
Wir bieten auch eine Reihe chinesischer Vortrainingsmodelle (chinesische GPT-Modelle) an. Der Vortrainingsprozess dieser Modelle ist in zwei Schritte unterteilt: zunächst Vortraining für chinesische Romandaten und dann Vortraining für LCCC-Daten Satz.
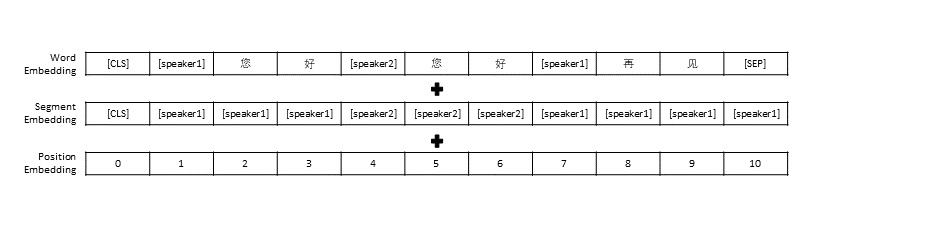
Wir folgten den Datenvorverarbeitungseinstellungen in TransferTransfo, die den gesamten Konversationsverlauf in einen Satz zusammenfügten, und verwendeten diesen Satz dann als Eingabe des Modells, um die Konversationsantwort vorherzusagen. Zusätzlich zur Vektordarstellung jedes Wortes umfasst die Eingabe unseres Modells auch die Sprechervektordarstellung und die Positionsvektordarstellung.
| Vorab trainiertes Modell | Anzahl der Parameter | Daten, die für das Vortraining verwendet werden | beschreiben |
|---|---|---|---|
| GPT- Roman | 95,5 Mio | Chinesische Romandaten | Chinesisches vorab trainiertes GPT-Modell, das auf chinesischen Romandaten basiert (die Romandaten umfassen insgesamt 1,3 Milliarden Wörter) |
| CDial-GPT LCCC-Basis | 95,5 Mio | LCCC-Basis | Basierend auf GPT Novel , verwenden Sie das von LCCC-base trainierte chinesische GPT-Modell |
| CDial-GPT2 LCCC-Basis | 95,5 Mio | LCCC-Basis | Basierend auf GPT Novel , verwenden Sie das chinesische vorab trainierte GPT2-Modell, das mit LCCC-Base trainiert wurde |
| CDial-GPT LCCC-groß | 95,5 Mio | LCCC-groß | Basierend auf GPT Novel , verwenden Sie das von LCCC-large trainierte chinesische GPT-Modell |
Direkt von der Quelle installieren:
git clone https://github.com/thu-coai/CDial-GPT.git
cd CDial-GPT
pip install -r requirements.txt
Schritt 1: Bereiten Sie den für das Vortrainingsmodell und die Feinabstimmung erforderlichen Datensatz vor (z. B. STC-Datensatz oder Spielzeugdaten „data/toy_data.json“ im Projektverzeichnis. Bitte beachten Sie, dass die Daten, wenn sie Englisch enthalten, getrennt werden müssen durch Buchstaben, wie zum Beispiel: Hallo)
# 下载 STC 数据集 中的训练集和验证集 并将其解压至 "data_path" 目录 (如果微调所使用的数据集为 STC)
git lfs install
git clone https://huggingface.co/thu-coai/CDial-GPT_LCCC-large # 您可自行下载模型或者OpenAIGPTLMHeadModel.from_pretrained("thu-coai/CDial-GPT_LCCC-large")
ps: Sie können die folgenden Links verwenden, um den Trainingssatz und den Verifizierungssatz von STC (Baidu Cloud Disk, Google Drive) herunterzuladen.
Schritt 2: Trainieren Sie das Modell
python train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # 使用单个GPU进行训练
oder
python -m torch.distributed.launch --nproc_per_node=8 train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # 以分布式的方式在8块GPU上训练
Der Parameter train_path wird auch in unserem Trainingsskript bereitgestellt, der es Benutzern ermöglicht, reine Textdateien in Slices zu lesen. Wenn Sie ein System mit begrenztem Speicher verwenden, sollten Sie erwägen, diesen Parameter zum Einlesen von Trainingsdaten zu verwenden. Wenn Sie train_path verwenden, müssen Sie data_path leer lassen.
Schritt 3: Text generieren
# YOUR_MODEL_PATH: 你要使用的模型的路径,每次微调后的模型目录保存在./runs/中
python infer.py --model_checkpoint YOUR_MODEL_PATH --datapath data/STC_test.json --out_path STC_result.txt # 在测试数据上生成回复
python interact.py --model_checkpoint YOUR_MODEL_PATH # 在命令行中与模型进行交互
ps: Sie können den folgenden Link verwenden, um das STC-Testset herunterzuladen (Baidu Cloud Disk, Google Drive)
Parameter des Trainingsskripts
| Parameter | Typ | Standardwert | beschreiben |
|---|---|---|---|
| model_checkpoint | str | „“ | Pfad oder URL der Modelldateien (Verzeichnis der Pre-Training-Modell- und Konfigurations-/Vocab-Dateien) |
| vortrainiert | bool | FALSCH | Wenn „False“, dann trainieren Sie das Modell von Grund auf |
| data_path | str | „“ | Pfad des Datensatzes |
| dataset_cache | str | default="dataset_cache" | Pfad oder URL des Datensatzcaches |
| train_path | str | „“ | Pfad des Trainingssatzes für verteilte Datensätze |
| gültiger_Pfad | str | „“ | Pfad des Validierungssatzes für verteilte Datensätze |
| log_file | str | „“ | Protokolle in eine Datei unter diesem Pfad ausgeben |
| num_workers | int | 1 | Anzahl der Unterprozesse zum Laden der Daten |
| n_Epochen | int | 70 | Anzahl der Trainingsepochen |
| train_batch_size | int | 8 | Chargengröße für das Training |
| valid_batch_size | int | 8 | Batchgröße für die Validierung |
| max_history | int | 15 | Anzahl früherer Austausche, die im Verlauf gespeichert werden sollen |
| Planer | str | „noam“ | Methode des Optimierers |
| n_emd | int | 768 | Anzahl der n_emd in der Konfigurationsdatei (für Noam) |
| eval_before_start | bool | FALSCH | Wenn dies zutrifft, beginnen Sie mit der Auswertung vor dem Training |
| warmup_steps | int | 5000 | Aufwärmschritte |
| valid_steps | int | 0 | Führen Sie alle X Schritte eine Validierung durch, wenn der Wert nicht 0 ist |
| gradient_accumulation_steps | int | 64 | Akkumulieren Sie Steigungen auf mehreren Stufen |
| max_norm | schweben | 1,0 | Clipping-Gradientennorm |
| Gerät | str | „cuda“ wenn Torch.cuda.is_available() sonst „cpu“ | Gerät (Cuda oder CPU) |
| fp16 | str | „“ | Für fp16-Training auf O0, O1, O2 oder O3 einstellen (siehe Apex-Dokumentation) |
| local_rank | int | -1 | Lokaler Rang für verteiltes Training (-1: nicht verteilt) |
Wir haben das Dialog-Pre-Training-Modell ausgewertet, das mithilfe des STC-Datensatzes (Trainingssatz/Validierungssatz (Baidu Netdisk, Google Drive), Testsatz (Baidu Netdisk, Google Drive)) verfeinert wurde. Alle Antworten wurden mittels Nucleus Sampling (p=0,9, Temperatur=0,7) erfasst.
| Modell | Modellgröße | PPL | BLEU-2 | BLEU-4 | Dist-1 | Dist-2 | Gieriges Matching | Einbettungsdurchschnitt |
|---|---|---|---|---|---|---|---|---|
| Attn-Seq2seq | 73M | 34.20 | 3,93 | 0,90 | 8.5 | 11.91 | 65,84 | 83,38 |
| Transformator | 113M | 22.10 | 6,72 | 3.14 | 8.8 | 13.97 | 66.06 | 83,55 |
| GPT2-Geplauder | 88M | - | 2.28 | 0,54 | 10.3 | 16.25 | 61,54 | 78,94 |
| GPT- Roman | 95,5 Mio | 21.27 | 5,96 | 2,71 | 8,0 | 11.72 | 66.12 | 83,34 |
| GPT LCCC-Basis | 95,5 Mio | 18.38 | 6.48 | 3.08 | 8.3 | 12.68 | 66.21 | 83,54 |
| GPT2 LCCC-Basis | 95,5 Mio | 22.76 | 5,69 | 2,50 | 7.7 | 10.87 | 66,24 | 83,46 |
| GPT LCCC-groß | 95,5 Mio | 18.23 | 6.63 | 3.20 | 8.3 | 12.71 | 66,25 | 83,63 |
Wir haben für jedes Modell 200 Antworten ausgewählt und drei Kommentatoren auf der Outsourcing-Plattform eingeladen, diese Antworten manuell auszuwerten. Die Bewertungsdimensionen waren Gesprächskompetenz, Kontextrelevanz und Antwortvielfalt. Der Bewertungsbereich für jede Dimension beträgt 2/1/0. Weitere Einzelheiten finden Sie in unserem Dokument.
| Modell | +2 | +1 | +0 | Kappa |
|---|---|---|---|---|
| Attn-Seq2Seq | 27,1 % | 21,4 % | 51,4 % | 0,4544 |
| Transformator | 42,4 % | 23,6 % | 34,0 % | 0,4429 |
| GPT2-Geplauder | 24,3 % | 19,1 % | 56,6 % | 0,3941 |
| GPT LCCC-Basis | 46,7 % | 21,8 % | 31,5 % | 0,3954 |
| GPT LCCC-groß | 48,6 % | 24,5 % | 27,0 % | 0,4203 |
Wir haben 1.000 Konversationsantworten nach dem Zufallsprinzip ausgewählt und die schlechten Antworten unter diesen Antworten gezählt:
| Enthält wiederholte Aussagen | Enthält Schimpfwörter | Andere schlechte Antworten |
|---|---|---|
| dreiundzwanzig | 9 | 2 |
Wir haben die Parameter des GPT LCCC-Large- Modells am STC-Datensatz feinabgestimmt und dieses feinabgestimmte Modell verwendet, um das folgende Konversationsbeispiel zu generieren:
| Post | Antwort |
|---|---|
| Das ist eigentlich Peking, nicht Harbin. | Das Wetter in Harbin scheint besser zu sein als in Peking. Es regnet hier leicht und es weht tagsüber starker Wind. |
| Der Campus-Werbewettbewerb des Betreibers hat so viel Spaß gemacht! Hahaha. | Ich dachte, es sei Jack Ma's Werbung. |
| Delsa S Posa Candy Color Series Hochzeitskleid, rosa, blau, rot und lila, verspielt und frisch, gefällt es dir? | Das letzte ist so schön, so schön! |
Wir haben auch das oben fein abgestimmte Modell verwendet, um die folgenden Interaktionsergebnisse zu erhalten:
| Roel | Antwort |
|---|---|
| Benutzer | Liebe mich nicht ohne Erfolg |
| Bot | Fruchtlose Liebe ist so schmerzhaft. |
| Benutzer | Aber es ist in Ordnung, wenn es dir gefallen hat |
| Bot | Manchmal ist Liebe ein Spiel. |
| Benutzer | Ich verliere immer |
| Bot | Ich liebe dich so sehr, wie ich dich liebe. |
| Benutzer | Kannst du es ziehen? |
| Bot | Du kannst es ziehen. |
| Benutzer | Imitiere mich nicht |
| Bot | Was ich damit sagen will ist, dass du es nicht schaffen kannst. |
| Benutzer | Du zwingst mich dazu, oder? |
| Bot | Nein, ich zwinge dich zum Sprechen, oder? |
Yida Wang, Pei Ke, Yinhe Zheng, Kaili Huang, Yong Jiang, Xiaoyan Zhu, Minlie Huang
Zuoxian Ye, Yao Wang, Yifan Pan
Der von diesem Projekt bereitgestellte LCCC-Datensatz und das vorab trainierte Dialogmodell dienen ausschließlich wissenschaftlichen Forschungszwecken. Die Konversationen im LCCC-Datensatz werden aus verschiedenen Quellen gesammelt. Obwohl wir einen strengen Datenbereinigungsprozess entwickelt haben, können wir nicht garantieren, dass alle unangemessenen Inhalte gefiltert wurden. Alle in diesen Daten enthaltenen Inhalte und Meinungen sind unabhängig von den Autoren dieses Projekts. Das in diesem Projekt bereitgestellte Modell und der Code sind nur ein Bestandteil des vollständigen Dialogsystems. Die von uns bereitgestellten Dekodierungsskripte dienen ausschließlich wissenschaftlichen Forschungszwecken. Sämtliche Dialoginhalte, die mit den Modellen und Skripten in diesem Projekt generiert werden, haben nichts mit dem Autor zu tun dieses Projekt.
Wenn Sie unser Projekt hilfreich finden, zitieren Sie bitte unser Papier:
@inproceedings{wang2020chinese,
title={A Large-Scale Chinese Short-Text Conversation Dataset},
author={Wang, Yida and Ke, Pei and Zheng, Yinhe and Huang, Kaili and Jiang, Yong and Zhu, Xiaoyan and Huang, Minlie},
booktitle={NLPCC},
year={2020},
url={https://arxiv.org/abs/2008.03946}
}
Dieses Projekt stellt einen groß angelegten, bereinigten chinesischen Konversationsdatensatz und ein auf diesem Datensatz vorab trainiertes chinesisches GPT-Modell bereit. Weitere Einzelheiten finden Sie in unserem Artikel.
Unser für das Vortraining verwendeter Code basiert auf dem TransferTransfo-Modell, das auf der Transformers-Bibliothek basiert. Die sowohl für das Vortraining als auch für die Feinabstimmung verwendeten Codes werden in diesem Repository bereitgestellt.
Wir präsentieren ein groß angelegtes bereinigtes chinesisches Konversationskorpus (LCCC), das Folgendes enthält: LCCC-base (Baidu Netdisk, Google Drive) und LCCC-large (Baidu Netdisk, Google Drive). Eine strenge Datenbereinigungspipeline soll die Qualität sicherstellen Korpus. Diese Pipeline umfasst eine Reihe von Regeln und mehrere auf Klassifikatoren basierende Filter, wie z. B. beleidigende oder sensible Wörter, spezielle Symbole, Emojis, grammatikalisch falsche Sätze und inkohärente Konversationen gefiltert.
Die Statistik unseres Korpus wird unten dargestellt. Dialoge mit nur zwei Äußerungen werden als „Single-Turn“-Dialoge und Dialoge mit mehr als drei Äußerungen als „Multi-Turn“-Dialoge betrachtet Jieba wird verwendet, um jede Äußerung in Wörter umzuwandeln.
| LCCC-Basis (Baidu Netdisk, Google Drive) | Singleturn | Multiturn |
|---|---|---|
| Sitzungen | 3.354.382 | 3.466.607 |
| Äußerungen | 6.708.554 | 13.365.268 |
| Charaktere | 68.559.727 | 163.690.614 |
| Vokabular | 372.063 | 666.931 |
| Durchschn. Wörter pro Äußerung | 6,79 | 8.32 |
| Durchschnittliche Äußerungen pro Sitzung | 2 | 3,86 |
Beachten Sie, dass die Reinigung von LCCC-base im Vergleich zu LCCC-large nach strengeren Regeln erfolgt.
| LCCC-groß (Baidu Netdisk, Google Drive) | Singleturn | Multiturn |
|---|---|---|
| Sitzungen | 7.273.804 | 4.733.955 |
| Äußerungen | 14.547.608 | 18.341.167 |
| Charaktere | 162.301.556 | 217.776.649 |
| Vokabular | 662.514 | 690.027 |
| Durchschn. Wörter pro Äußerung | 7.45 | 8.14 |
| Durchschnittliche Äußerungen pro Sitzung | 2 | 3,87 |
Die Rohdialoge für LCCC-base stammen aus einem Weibo-Korpus, den wir von Weibo gecrawlt haben, und die Rohdialoge für LCCC-large werden durch die Kombination mehrerer Konversationsdatensätze zusätzlich zum Weibo-Korpus erstellt:
| Datensatz | Sitzungen | Probe |
|---|---|---|
| Weibo-Korpus | 79M | F: Ich habe sieben oder acht Mal Hot Pot in Chengdu, Chongqing, gegessen. A: Hahahaha! Dann könnte mein Mund verfaulen! |
| PTT-Klatschkorpus | 0,4 Mio | F: Warum schikanieren Dorfbewohner immer High-School-Schüler? FQ A: Wenn Sie denken, dass Sie zu Bill Gates werden, wenn Sie ein gutes Fach wählen, dann können Sie genauso gut die Schule abbrechen. |
| Untertitelkorpus | 2,74 Mio | F: Die Menschen in der Peking-Oper sind nicht frei. A: Sie sperren die Menschen in Käfige. |
| Xiaohuangji-Korpus | 0,45 Mio | F: Warst du jemals verliebt? A: Warst du jemals verliebt? Oh, erwähne es nicht, ich bin traurig ... |
| Tieba-Korpus | 2,32 Mio | F: Erste Reihe, alle Lu-Fans stehen auf, oder? A: Im Titel steht „Vorlagen“, aber nachdem man den Ball gesehen hat, ist das wirklich eine lebendige Ironie. |
| Qingyun-Korpus | 0,1 Mio | F: Es scheint, dass Sie Geld sehr lieben. A: Oh, wirklich? Dann haben Sie es fast geschafft |
| Douban-Konversationskorpus | 0,5 Mio | F: Lernen Sie reines Englisch, indem Sie sich englische Originalfilme ansehen. A: Ich liebe „Friends“ und habe es mir schon oft angeschaut. F: Ich bin fast erschöpft, wenn ich mir die gleiche CD anschaue. A: Dann sollten Ihre Englischkenntnisse jetzt ziemlich gut sein |
| E-kommerzielles Konversationskorpus | 0,5 Mio | F: Wird das ein gutes Angebot sein? A: Wird es in Zukunft verfügbar sein? A: Bitte achten Sie darauf. |
| Chinesischer Chat-Korpus | 0,5 Mio | F: Meine Beine sind heute nutzlos, also werde ich Steine bewegen. A: Es ist sogar harte Arbeit, um an Weihnachten viel Geld zu verdienen Ich habe keinen Freund, also ist jeder Urlaub gleich. |
Wir präsentieren auch eine Reihe chinesischer GPT-Modelle, die zunächst anhand eines chinesischen Romandatensatzes vorab trainiert und dann anhand unseres LCCC-Datensatzes nachtrainiert werden.
Ähnlich wie bei TransferTransfo verketten wir alle Dialogverläufe in einem Kontextsatz und verwenden diesen Satz, um die Antwort vorherzusagen. Die Eingabe unseres Modells besteht aus der Worteinbettung, der Sprechereinbettung und der Positionseinbettung jedes Wortes.
| Modelle | Parametergröße | Datensatz vor dem Training | Beschreibung |
|---|---|---|---|
| GPT- Roman | 95,5 Mio | Chinesischer Roman | Ein GPT-Modell, das auf dem chinesischen Romandatensatz vorab trainiert wurde (1,3 Milliarden Wörter, beachten Sie, dass wir die Details dieses Modells nicht angeben). |
| CDial-GPT LCCC-Basis | 95,5 Mio | LCCC-Basis | Ein GPT-Modell, das auf dem LCCC-basierten Datensatz von GPT Novel nachtrainiert wurde |
| CDial-GPT2 LCCC-Basis | 95,5 Mio | LCCC-Basis | Ein GPT2-Modell, das auf dem LCCC-basierten Datensatz von GPT Novel nachtrainiert wurde |
| CDial-GPT LCCC-groß | 95,5 Mio | LCCC-groß | Ein GPT-Modell, das auf einem LCCC-großen Datensatz von GPT Novel nachtrainiert wurde |
Von den Quellcodes installieren:
git clone https://github.com/thu-coai/CDial-GPT.git
cd CDial-GPT
pip install -r requirements.txt
Schritt 1: Bereiten Sie die Daten für die Feinabstimmung vor (z. B. STC-Datensatz oder „data/toy_data.json“ in unserem Repository) und das vorab getestete Modell:
# Download the STC dataset and unzip into "data_path" dir (fine-tuning on STC)
git lfs install
git clone https://huggingface.co/thu-coai/CDial-GPT_LCCC-large # or OpenAIGPTLMHeadModel.from_pretrained("thu-coai/CDial-GPT_LCCC-large")
ps: Sie können den Zug und die gültige Aufteilung von STC über die folgenden Links herunterladen: (Baidu Netdisk, Google Drive)
Schritt 2: Trainieren Sie das Modell
python train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # Single GPU training
oder
python -m torch.distributed.launch --nproc_per_node=8 train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # Training on 8 GPUs
Hinweis: Wir haben im Trainingsskript auch das Argument train_path bereitgestellt, um den Datensatz im Klartext zu lesen, der aufgeteilt und verteilt verarbeitet wird. Sie können dieses Argument verwenden, wenn der Datensatz zu groß für den Speicher Ihres Systems ist. Denken Sie daran, das Argument data_path leer zu lassen, wenn Sie train_path verwenden.
Schritt 3: Inferenzmodus
# YOUR_MODEL_PATH: the model path used for generation
python infer.py --model_checkpoint YOUR_MODEL_PATH --datapath data/STC_test.json --out_path STC_result.txt # Do Inference on a corpus
python interact.py --model_checkpoint YOUR_MODEL_PATH # Interact on the terminal
ps: Sie können den Test-Split von STC über die folgenden Links herunterladen: (Baidu Netdisk, Google Drive)
Trainingsargumente
| Argumente | Typ | Standardwert | Beschreibung |
|---|---|---|---|
| model_checkpoint | str | „“ | Pfad oder URL der Modelldateien (Verzeichnis der Pre-Training-Modell- und Konfigurations-/Vokabeldateien) |
| vortrainiert | bool | FALSCH | Wenn „False“, dann trainieren Sie das Modell von Grund auf |
| data_path | str | „“ | Pfad des Datensatzes |
| dataset_cache | str | default="dataset_cache" | Pfad oder URL des Datensatzcaches |
| train_path | str | „“ | Pfad des Trainingssatzes für verteilte Datensätze |
| gültiger_Pfad | str | „“ | Pfad des Validierungssatzes für verteilte Datensätze |
| log_file | str | „“ | Protokolle in eine Datei unter diesem Pfad ausgeben |
| num_workers | int | 1 | Anzahl der Unterprozesse zum Laden der Daten |
| n_Epochen | int | 70 | Anzahl der Trainingsepochen |
| train_batch_size | int | 8 | Chargengröße für das Training |
| valid_batch_size | int | 8 | Batchgröße für die Validierung |
| max_history | int | 15 | Anzahl früherer Austausche, die im Verlauf gespeichert werden sollen |
| Planer | str | „noam“ | Methode des Optimierers |
| n_emd | int | 768 | Anzahl der n_emd in der Konfigurationsdatei (für Noam) |
| eval_before_start | bool | FALSCH | Wenn dies zutrifft, beginnen Sie mit der Auswertung vor dem Training |
| warmup_steps | int | 5000 | Aufwärmschritte |
| valid_steps | int | 0 | Führen Sie alle X Schritte eine Validierung durch, wenn der Wert nicht 0 ist |
| gradient_accumulation_steps | int | 64 | Akkumulieren Sie Steigungen auf mehreren Stufen |
| max_norm | schweben | 1,0 | Clipping-Gradientennorm |
| Gerät | str | „cuda“ wenn Torch.cuda.is_available() sonst „cpu“ | Gerät (Cuda oder CPU) |
| fp16 | str | „“ | Für fp16-Training auf O0, O1, O2 oder O3 einstellen (siehe Apex-Dokumentation) |
| local_rank | int | -1 | Lokaler Rang für verteiltes Training (-1: nicht verteilt) |
Die Auswertung erfolgt anhand von Ergebnissen, die durch fein abgestimmte Modelle generiert wurden
STC-Datensatz (Train/Valid-Split (Baidu Netdisk, Google Drive), Test-Split (Baidu Netdisk, Google Drive)). Alle Antworten werden mithilfe des Nucleus-Sampling-Schemas mit einem Schwellenwert von 0,9 und einer Temperatur von 0,7 generiert.
| Modelle | Modellgröße | PPL | BLEU-2 | BLEU-4 | Dist-1 | Dist-2 | Gieriges Matching | Einbettungsdurchschnitt |
|---|---|---|---|---|---|---|---|---|
| Attn-Seq2seq | 73M | 34.20 | 3,93 | 0,90 | 8.5 | 11.91 | 65,84 | 83,38 |
| Transformator | 113M | 22.10 | 6,72 | 3.14 | 8.8 | 13.97 | 66.06 | 83,55 |
| GPT2-Geplauder | 88M | - | 2.28 | 0,54 | 10.3 | 16.25 | 61,54 | 78,94 |
| GPT- Roman | 95,5 Mio | 21.27 | 5,96 | 2,71 | 8,0 | 11.72 | 66.12 | 83,34 |
| GPT LCCC-Basis | 95,5 Mio | 18.38 | 6.48 | 3.08 | 8.3 | 12.68 | 66.21 | 83,54 |
| GPT2 LCCC-Basis | 95,5 Mio | 22.76 | 5,69 | 2,50 | 7.7 | 10.87 | 66,24 | 83,46 |
| GPT LCCC-groß | 95,5 Mio | 18.23 | 6.63 | 3.20 | 8.3 | 12.71 | 66,25 | 83,63 |
Wir haben außerdem drei Crowdsourcing-Annotatoren eingesetzt, um 200 Beispiele jedes Modells auf der Grundlage eines 2/1/0-Bewertungsschemas hinsichtlich Sprachkompetenz, Relevanz und Diversität zu bewerten. Weitere Einzelheiten finden Sie in unserem Artikel.
| Modelle | +2 | +1 | +0 | Kappa |
|---|---|---|---|---|
| Attn-Seq2Seq | 27,1 % | 21,4 % | 51,4 % | 0,4544 |
| Transformator | 42,4 % | 23,6 % | 34,0 % | 0,4429 |
| GPT2-Geplauder | 24,3 % | 19,1 % | 56,6 % | 0,3941 |
| GPT LCCC-Basis | 46,7 % | 21,8 % | 31,5 % | 0,3954 |
| GPT LCCC-groß | 48,6 % | 24,5 % | 27,0 % | 0,4203 |
Wir wählen zufällig 1000 generierte Proben aus und erstellen eine Statistik der toxischen Entstehung:
| Wiederholung | Schmutziges Wort | Andere schlimme Fälle |
|---|---|---|
| dreiundzwanzig | 9 | 2 |
Single-Turn-generierte Beispiele aus dem STC-Datensatz (feinabgestimmt auf STC):
| Post | Antwort |
|---|---|
| Das ist eigentlich Peking, nicht Harbin. | Das Wetter in Harbin scheint besser zu sein als in Peking. Es regnet hier leicht und es weht tagsüber starker Wind. |
| Der Campus-Werbewettbewerb des Betreibers hat so viel Spaß gemacht! Hahaha. | Ich dachte, es sei Jack Ma's Werbung. |
| Delsa S Posa Candy Color Series Hochzeitskleid, rosa, blau, rot und lila, verspielt und frisch, gefällt es dir? | Das letzte ist so schön, so schön! |
Beispiele für die Generierung mehrerer Runden mithilfe des interaktiven Skripts:
| Roel | Antwort |
|---|---|
| Benutzer | Liebe mich nicht ohne Erfolg |
| Bot | Fruchtlose Liebe ist so schmerzhaft. |
| Benutzer | Aber es ist in Ordnung, wenn es dir gefallen hat |
| Bot | Manchmal ist Liebe ein Spiel. |
| Benutzer | Ich verliere immer |
| Bot | Ich liebe dich so sehr, wie ich dich liebe. |
| Benutzer | Kannst du es ziehen? |
| Bot | Du kannst es ziehen. |
| Benutzer | Imitiere mich nicht |
| Bot | Was ich damit sagen will ist, dass du es nicht schaffen kannst. |
| Benutzer | Du zwingst mich dazu, oder? |
| Bot | Nein, ich zwinge dich zum Sprechen, oder? |
Yida Wang, Pei Ke, Yinhe Zheng, Kaili Huang, Yong Jiang, Xiaoyan Zhu, Minlie Huang
Zuoxian Ye, Yao Wang, Yifan Pan
Der LCCC-Datensatz und die vorab trainierten Modelle sollen die Recherche zur Konversationsgenerierung erleichtern. Der in diesem Repository bereitgestellte LCCC-Datensatz stammt aus verschiedenen Quellen. Obwohl ein strenger Bereinigungsprozess durchgeführt wurde, gibt es keine Garantie dafür, dass alle unangemessenen Inhalte vorhanden sind Alle in diesem Datensatz enthaltenen Inhalte stellen nicht die Meinung der Autoren dar. Dieses Repository enthält nur einen Teil der Modellierungsmaschinerie, die zur tatsächlichen Erstellung eines Dialogmodells erforderlich ist . Wir sind nicht verantwortlich für alle mit unserem Modell generierten Inhalte.
Bitte zitieren Sie unser Papier, wenn Sie die Datensätze oder Modelle in Ihrer Forschung verwenden:
@inproceedings{wang2020chinese,
title={A Large-Scale Chinese Short-Text Conversation Dataset},
author={Wang, Yida and Ke, Pei and Zheng, Yinhe and Huang, Kaili and Jiang, Yong and Zhu, Xiaoyan and Huang, Minlie},
booktitle={NLPCC},
year={2020},
url={https://arxiv.org/abs/2008.03946}
}


