Kosmos X
0.0.1

pip3 install --upgrade kosmosx import torch
from kosmosx . model import Kosmos
# Create a sample text token tensor
text_tokens = torch . randint ( 0 , 32002 , ( 1 , 50 ), dtype = torch . long )
# Create a sample image tensor
images = torch . randn ( 1 , 3 , 224 , 224 )
# Instantiate the model
model = Kosmos ()
text_tokens = text_tokens . long ()
# Pass the sample tensors to the model's forward function
output = model . forward (
text_tokens = text_tokens ,
images = images
)
# Print the output from the model
print ( f"Output: { output } " ) Richten Sie Ihre Konfiguration mit accelerate config und dann accelerate launch train.py ein
KOSMOS-1 verwendet eine reine Decoder-Transformer-Architektur auf Basis von Magneto (Foundation Transformers), d. ln) Kombinieren der Vorteile beider Ansätze für die Sprachmodellierung bzw. das Bildverständnis. Das Modell wird außerdem gemäß einer spezifischen Metrik initialisiert, die ebenfalls im Dokument beschrieben wird, was ein stabileres Training bei höheren Lernraten ermöglicht.
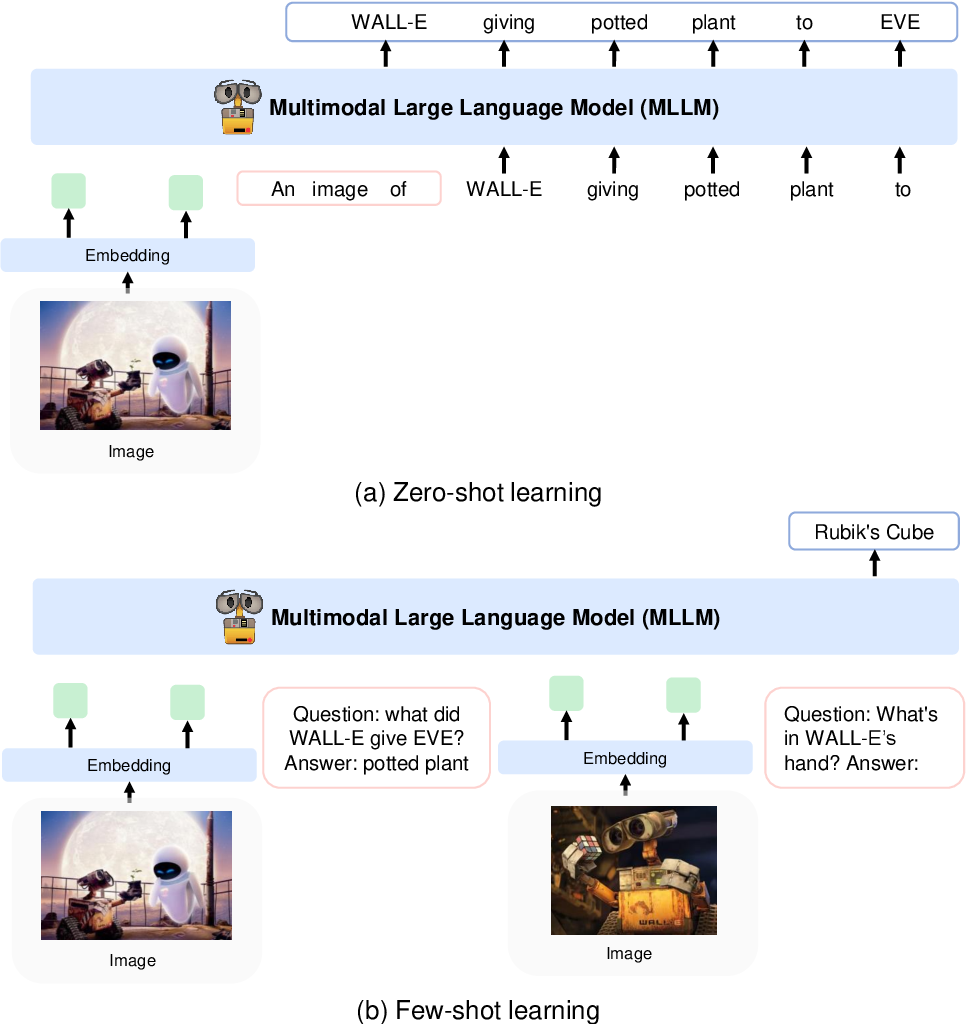
Sie kodieren Bilder mithilfe eines CLIP VIT-L/14-Modells in Bildmerkmale und verwenden einen in Flamingo eingeführten Perceptor-Resampler, um die Bildmerkmale aus 256 -> 64 Token zu bündeln. Die Bildfunktionen werden mit den Token-Einbettungen kombiniert, indem sie der Eingabesequenz hinzugefügt werden, die von speziellen Tokens <image> und </image> umgeben ist. Ein Beispiel ist <s> <image> image_features </image> text </s> . Dadurch können Bilder in derselben Reihenfolge mit Text verwoben werden.
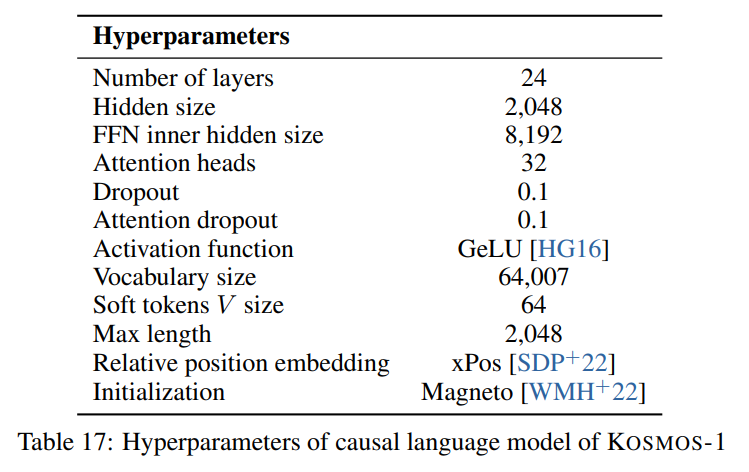
Wir folgen den im Papier beschriebenen Hyperparametern, die im folgenden Bild sichtbar sind:
Wir verwenden die Torchscale-Implementierung der reinen Decoder-Transformer-Architektur von Foundation Transformers:
from torchscale . architecture . config import DecoderConfig
from torchscale . architecture . decoder import Decoder
config = DecoderConfig (
decoder_layers = 24 ,
decoder_embed_dim = 2048 ,
decoder_ffn_embed_dim = 8192 ,
decoder_attention_heads = 32 ,
dropout = 0.1 ,
activation_fn = "gelu" ,
attention_dropout = 0.1 ,
vocab_size = 32002 ,
subln = True , # sub-LN approach
xpos_rel_pos = True , # rotary positional embeddings
max_rel_pos = 2048
)
decoder = Decoder (
config ,
embed_tokens = embed ,
embed_positions = embed_positions ,
output_projection = output_projection
)Für das Bildmodell (CLIP VIT-L/14) verwenden wir ein vorab trainiertes OpenClip-Modell:
from transformers import CLIPModel
clip_model = CLIPModel . from_pretrained ( "laion/CLIP-ViT-L-14-laion2B-s32B-b82K" ). vision_model
# projects image to [batch_size, 256, 1024]
features = clip_model ( pixel_values = images )[ "last_hidden_state" ]Wir folgen den Standard-Hyperparamen für den Wahrnehmer-Resampler, da in der Arbeit keine Hyperparame angegeben sind:
from flamingo_pytorch import PerceiverResampler
perceiver = PerceiverResampler (
dim = 1024 ,
depth = 2 ,
dim_head = 64 ,
heads = 8 ,
num_latents = 64 ,
num_media_embeds = 256
)
# projects image features to [batch_size, 64, 1024]
self . perceive ( images ). squeeze ( 1 ) Da das Modell eine verborgene Dimension von 2048 erwartet, verwenden wir eine nn.Linear Ebene, um die Bildmerkmale auf die richtige Dimension zu projizieren und sie gemäß dem Initialisierungsschema von Magneto zu initialisieren:
image_proj = torch . nn . Linear ( 1024 , 2048 , bias = False )
torch . nn . init . normal_ (
image_proj . weight , mean = 0 , std = 2048 ** - 0.5
)
scaled_image_features = image_proj ( image_features ) Das Papier beschreibt ein SentencePiece mit einem Vokabular von 64007 Token. Der Einfachheit halber (da uns das Trainingskorpus nicht zur Verfügung steht) verwenden wir die nächstbeste Open-Source-Alternative, den vorab trainierten T5-Large-Tokenizer von HuggingFace. Dieser Tokenizer verfügt über ein Vokabular von 32002 Token.
from transformers import T5Tokenizer
tokenizer = T5Tokenizer . from_pretrained (
"t5-large" ,
additional_special_tokens = [ "<image>" , "</image>" ],
extra_ids = 0 ,
model_max_length = 1984 # 2048 - 64 (image features)
) Anschließend betten wir die Token mit einer nn.Embedding Ebene ein. Wir verwenden tatsächlich ein bnb.nn.Embedding von bitandbytes, das es uns ermöglicht, später 8-Bit-AdamW zu verwenden.
import bitsandbytes as bnb
embed = bnb . nn . Embedding (
32002 , # Num embeddings
2048 , # Embedding dim
padding_idx
)Für Positionseinbettungen verwenden wir:
from torchscale . component . embedding import PositionalEmbedding
embed_positions = PositionalEmbedding (
2048 , # Num embeddings
2048 , # Embedding dim
padding_idx
)Außerdem fügen wir eine Ausgabeprojektionsebene hinzu, um die verborgene Dimension auf die Vokabulargröße zu projizieren und sie gemäß dem Initialisierungsschema von Magneto zu initialisieren:
output_projection = torch . nn . Linear (
2048 , 32002 , bias = False
)
torch . nn . init . normal_ (
output_projection . weight , mean = 0 , std = 2048 ** - 0.5
) Ich musste einige geringfügige Änderungen am Decoder vornehmen, damit er bereits eingebettete Funktionen im Vorwärtsdurchlauf akzeptieren konnte. Dies war notwendig, um die oben beschriebene komplexere Eingabesequenz zu ermöglichen. Die Änderungen sind im folgenden Diff in Zeile 391 von torchscale/architecture/decoder.py sichtbar:
+ if kwargs.get("passed_x", None) is None:
+ x, _ = self.forward_embedding(
+ prev_output_tokens, token_embeddings, incremental_state
+ )
+ else:
+ x = kwargs["passed_x"]
- x, _ = self.forward_embedding(
- prev_output_tokens, token_embeddings, incremental_state
- )Hier ist eine Markdown-Tabelle mit Metadaten für die im Artikel erwähnten Datensätze:
| Datensatz | Beschreibung | Größe | Link |
|---|---|---|---|
| Der Haufen | Vielfältiges englisches Textkorpus | 800 GB | Umarmendes Gesicht |
| Gemeinsames Kriechen | Web-Crawling-Daten | - | Gemeinsames Kriechen |
| LAION-400M | Bild-Text-Paare von Common Crawl | 400 Mio. Paare | Umarmendes Gesicht |
| LAION-2B | Bild-Text-Paare von Common Crawl | 2B-Paare | ArXiv |
| COYO | Bild-Text-Paare von Common Crawl | 700 Millionen Paare | Github |
| Konzeptionelle Bildunterschriften | Bild-Alt-Textpaare | 15 Mio. Paare | ArXiv |
| Verschachtelte CC-Daten | Text und Bilder von Common Crawl | 71 Millionen Dokumente | Benutzerdefinierter Datensatz |
| StoryCloze | Gesunder Menschenverstand | 16.000 Beispiele | ACL-Anthologie |
| HellaSwag | Commonsense NLI | 70.000 Beispiele | ArXiv |
| Winograd-Schema | Wortmehrdeutigkeit | 273 Beispiele | PKRR 2012 |
| Winogrande | Wortmehrdeutigkeit | 1,7.000 Beispiele | AAAI 2020 |
| PIQA | Physisch vernünftige Qualitätssicherung | 16.000 Beispiele | AAAI 2020 |
| BoolQ | Qualitätssicherung | 15.000 Beispiele | ACL 2019 |
| CB | Rückschluss auf natürliche Sprache | 250 Beispiele | Sinn und Bedeutung 2019 |
| COPA | Kausales Denken | 1k Beispiele | AAAI Frühjahrssymposium 2011 |
| RelativeSize | Gesunder Menschenverstand | 486 Paare | ArXiv 2016 |
| MemoryColor | Gesunder Menschenverstand | 720 Beispiele | ArXiv 2021 |
| Farbbedingungen | Gesunder Menschenverstand | 320 Beispiele | ACL 2012 |
| IQ-Test | Nonverbale Argumentation | 50 Beispiele | Benutzerdefinierter Datensatz |
| COCO-Bildunterschriften | Bildunterschrift | 413.000 Bilder | PAMI 2015 |
| Flickr30k | Bildunterschrift | 31.000 Bilder | TACL 2014 |
| VQAv2 | Visuelle Qualitätssicherung | 1 Mio. QA-Paare | CVPR 2017 |
| VizWiz | Visuelle Qualitätssicherung | 31.000 QA-Paare | CVPR 2018 |
| WebSRC | Web-QA | 1,4.000 Beispiele | EMNLP 2021 |
| ImageNet | Bildklassifizierung | 1,28 Millionen Bilder | CVPR 2009 |
| CUB | Bildklassifizierung | 200 Vogelarten | TOG 2011 |
APACHE


