SimplyRetrieve
Dependencies Update
? Neuigkeiten : 21. August 2023 – Benutzer können jetzt über die neu hinzugefügte Knowledge Tab in der GUI Wissen im Handumdrehen erstellen und anhängen. Außerdem wurden Fortschrittsbalken in den Registerkarten „Konfiguration“ und „Wissen“ hinzugefügt.
SimplyRetrieve ist ein Open-Source-Tool mit dem Ziel, der Community des maschinellen Lernens eine vollständig lokalisierte, leichte und benutzerfreundliche GUI- und API-Plattform für den Retrieval-Centric Generation (RCG)-Ansatz bereitzustellen.
Erstellen Sie ein Chat-Tool mit Ihren Dokumenten und Sprachmodellen, das hochgradig anpassbar ist. Merkmale sind:
Ein technischer Bericht zu diesem Tool ist bei arXiv verfügbar.
Ein kurzes Video zu diesem Tool ist auf YouTube verfügbar.
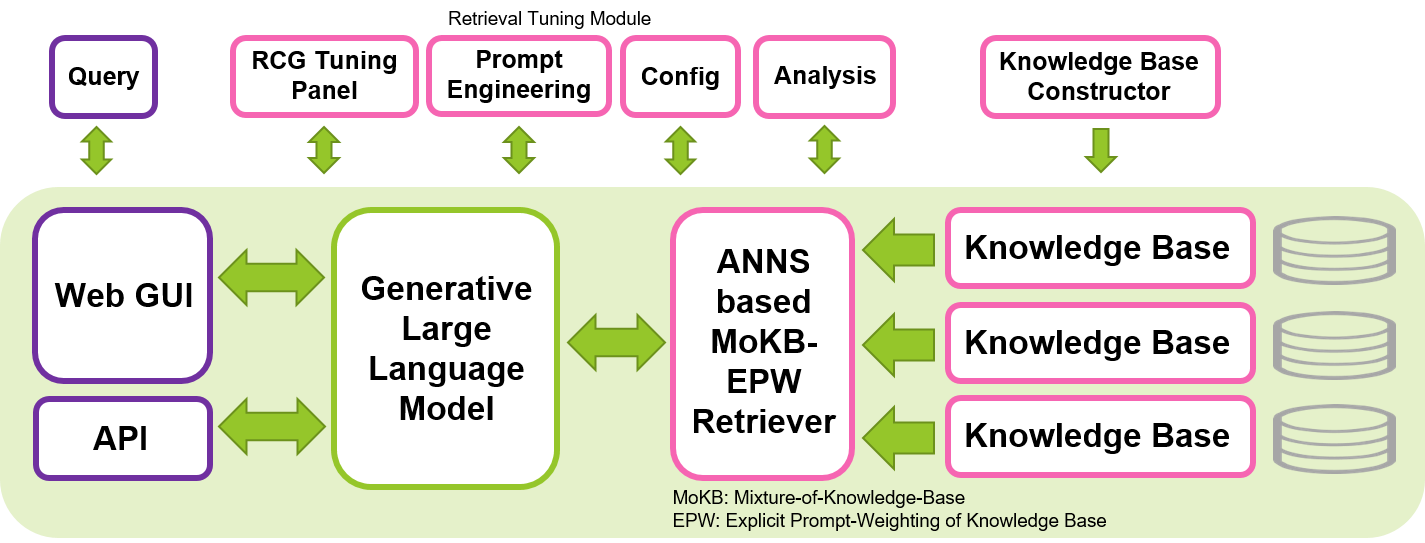
Unser Ziel ist es, zur Entwicklung sicherer, interpretierbarer und verantwortungsvoller LLMs beizutragen, indem wir unser Open-Source-Tool zur Umsetzung des RCG-Ansatzes teilen. Wir hoffen, dass dieses Tool es der Community für maschinelles Lernen ermöglicht, die Verwendung von LLMs effizienter zu erkunden und gleichzeitig den Datenschutz und die lokale Implementierung zu wahren. Retrieval-Centric Generation, die auf dem Retrieval-Augmented Generation (RAG)-Konzept aufbaut, indem sie die entscheidende Rolle der LLMs bei der Kontextinterpretation betont und die Wissensspeicherung der Retriever-Komponente anvertraut, hat das Potenzial, eine effizientere und interpretierbarere Generierung zu erzeugen und zu reduzieren der Umfang der LLMs, die für generative Aufgaben erforderlich sind. Dieses Tool kann auf einer einzelnen Nvidia-GPU ausgeführt werden, beispielsweise auf der T4, V100 oder A100, wodurch es für eine breite Palette von Benutzern zugänglich ist.
Dieses Tool basiert hauptsächlich auf den großartigen und bekannten Bibliotheken Hugging Face, Gradio, PyTorch und Faiss. Das in diesem Tool konfigurierte Standard-LLM ist der anweisungsfein abgestimmte Wizard-Vicuna-13B-Uncensored. Das Standardeinbettungsmodell für Retriever ist multilingual-e5-base. Wir haben festgestellt, dass diese Modelle in diesem System gut funktionieren, ebenso wie in vielen anderen verschiedenen Größen von Open-Source-LLMs und Retrievern, die in Hugging Face verfügbar sind. Dieses Tool kann neben Englisch auch in anderen Sprachen ausgeführt werden, indem geeignete LLMs ausgewählt und Eingabeaufforderungsvorlagen entsprechend der Zielsprache angepasst werden.
pip install -r requirements.txtchat/data/ ab und führen Sie das Datenvorbereitungsskript aus ( cd chat/ und dann den folgenden Befehl). CUDA_VISIBLE_DEVICES=0 python prepare.py --input data/ --output knowledge/ --config configs/default_release.json
pdf, txt, doc, docx, ppt, pptx, html, md, csv und können durch Bearbeiten der Konfigurationsdatei einfach erweitert werden. Befolgen Sie die Tipps zu diesem Problem, wenn ein NLTK-bezogener Fehler aufgetreten ist.Knowledge Tab des GUI-Tools verfügbar. Benutzer können jetzt Wissen im laufenden Betrieb hinzufügen. Es ist nicht erforderlich, das obige Skript „prepare.py“ vor der Ausführung des Tools auszuführen. Nachdem Sie die oben genannten Voraussetzungen eingerichtet haben, legen Sie den aktuellen Pfad zum chat Verzeichnis ( cd chat/ ) fest und führen Sie den folgenden Befehl aus. Dann grab a coffee! da das Laden nur wenige Minuten dauert.
CUDA_VISIBLE_DEVICES=0 python chat.py --config configs/default_release.json
Greifen Sie dann über Ihren bevorzugten Browser auf die webbasierte GUI zu, indem Sie zu http://<LOCAL_SERVER_IP>:7860 navigieren. Ersetzen Sie <LOCAL_SERVER_IP> durch die IP-Adresse Ihres GPU-Servers. Und das ist es, Sie können loslegen!
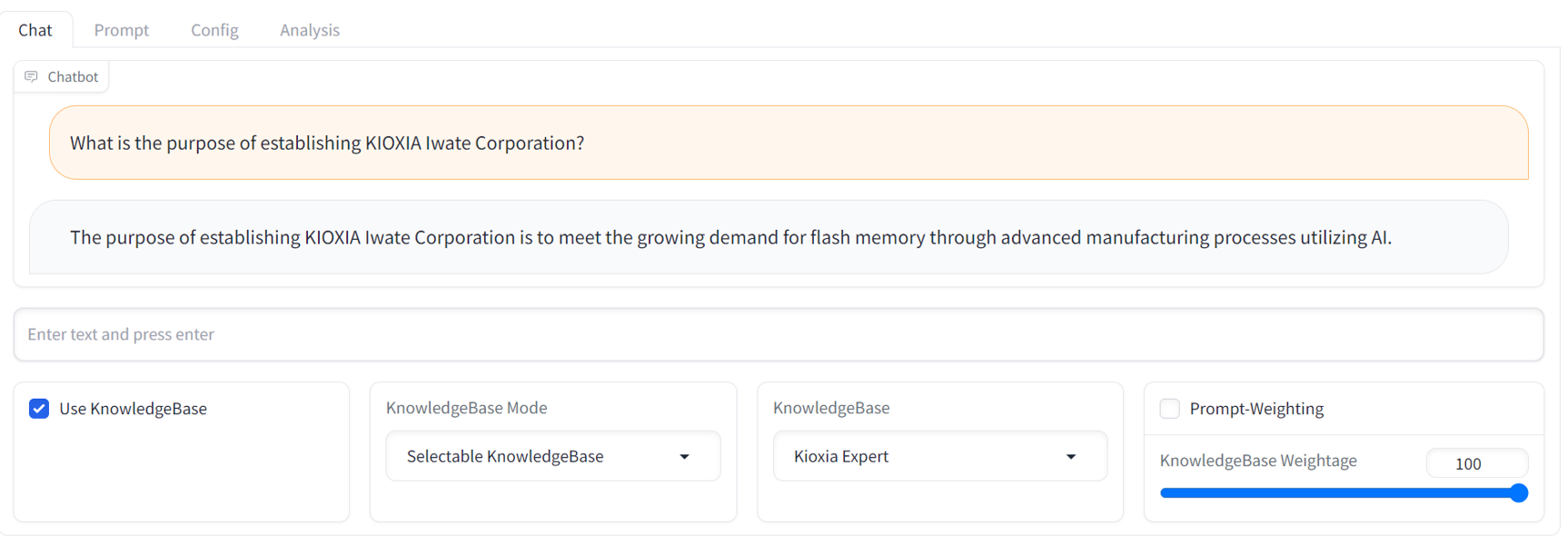
GUI operation manual finden Sie in der GUI-Readme-Datei im Verzeichnis docs/ .API access manual finden Sie in der API-Readme-Datei und den Beispielskripten im Verzeichnis examples/ .Unten finden Sie einen Beispiel-Chat-Screenshot der GUI. Es bietet eine vertraute Streaming-Chatbot-Schnittstelle mit einem umfassenden RCG-Tuning-Panel.
Sie verfügen derzeit nicht über einen lokalen GPU-Server, um dieses Tool auszuführen? Kein Problem. Besuchen Sie dieses Repository. Es zeigt die Anleitung zum Ausprobieren dieses Tools auf der AWS EC2-Cloud-Plattform.
Fühlen Sie sich frei, uns Feedback und Kommentare zu geben. Wir freuen uns sehr über jede Diskussion und jeden Beitrag zu diesem Tool, einschließlich neuer Funktionen, Verbesserungen und besserer Dokumentation. Fühlen Sie sich frei, ein Problem oder eine Diskussion zu eröffnen. Wir haben noch keine Vorlage für ein Problem oder eine Diskussion, daher reicht vorerst alles aus.
Zukünftige Entwicklungen
Es ist wichtig zu beachten, dass dieses Tool keine narrensichere Lösung für die Gewährleistung einer völlig sicheren und verantwortungsvollen Reaktion generativer KI-Modelle bietet, selbst im Rahmen eines abrufzentrierten Ansatzes. Die Entwicklung sichererer, interpretierbarer und verantwortungsvoller KI-Systeme bleibt ein aktiver Forschungsbereich und fortlaufende Bemühungen.
Von diesem Tool generierte Texte können aufgrund des nächsten Token-Vorhersageverhaltens von LLMs der aktuellen Generation Abweichungen aufweisen, auch wenn Eingabeaufforderungen oder Abfragen nur geringfügig geändert werden. Dies bedeutet, dass Benutzer möglicherweise sowohl die Eingabeaufforderungen als auch die Abfragen sorgfältig abstimmen müssen, um optimale Antworten zu erhalten.
Wenn Sie unsere Arbeit nützlich finden, zitieren Sie uns bitte wie folgt:
@article{ng2023simplyretrieve,
title={SimplyRetrieve: A Private and Lightweight Retrieval-Centric Generative AI Tool},
author={Youyang Ng and Daisuke Miyashita and Yasuto Hoshi and Yasuhiro Morioka and Osamu Torii and Tomoya Kodama and Jun Deguchi},
year={2023},
eprint={2308.03983},
archivePrefix={arXiv},
primaryClass={cs.CL},
journal={arXiv preprint arXiv:2308.03983}
}
?️ Zugehörigkeit: Institute of Memory Technology R&D, Kioxia Corporation, Japan


