gen ai document sumarization
1.0.0
Dieses Projekt untersucht das Potenzial generativer Open-Source-KI-Modelle, insbesondere solcher, die auf der Transformer-Architektur basieren, zur Automatisierung der Zusammenfassung von Dokumentinhalten. Ziel ist es, bestehende generative KI-Modelle zu evaluieren und anzuwenden, um den Kontext zu analysieren, zu verstehen und Zusammenfassungen für unstrukturierte Dokumente zu erstellen.
Um dies zu erreichen, habe ich zwei prominente Modelle verfeinert: t5-small und facebook/bart-base, wobei ich mich auf die Verbesserung ihrer Zusammenfassungsleistung konzentriert habe.
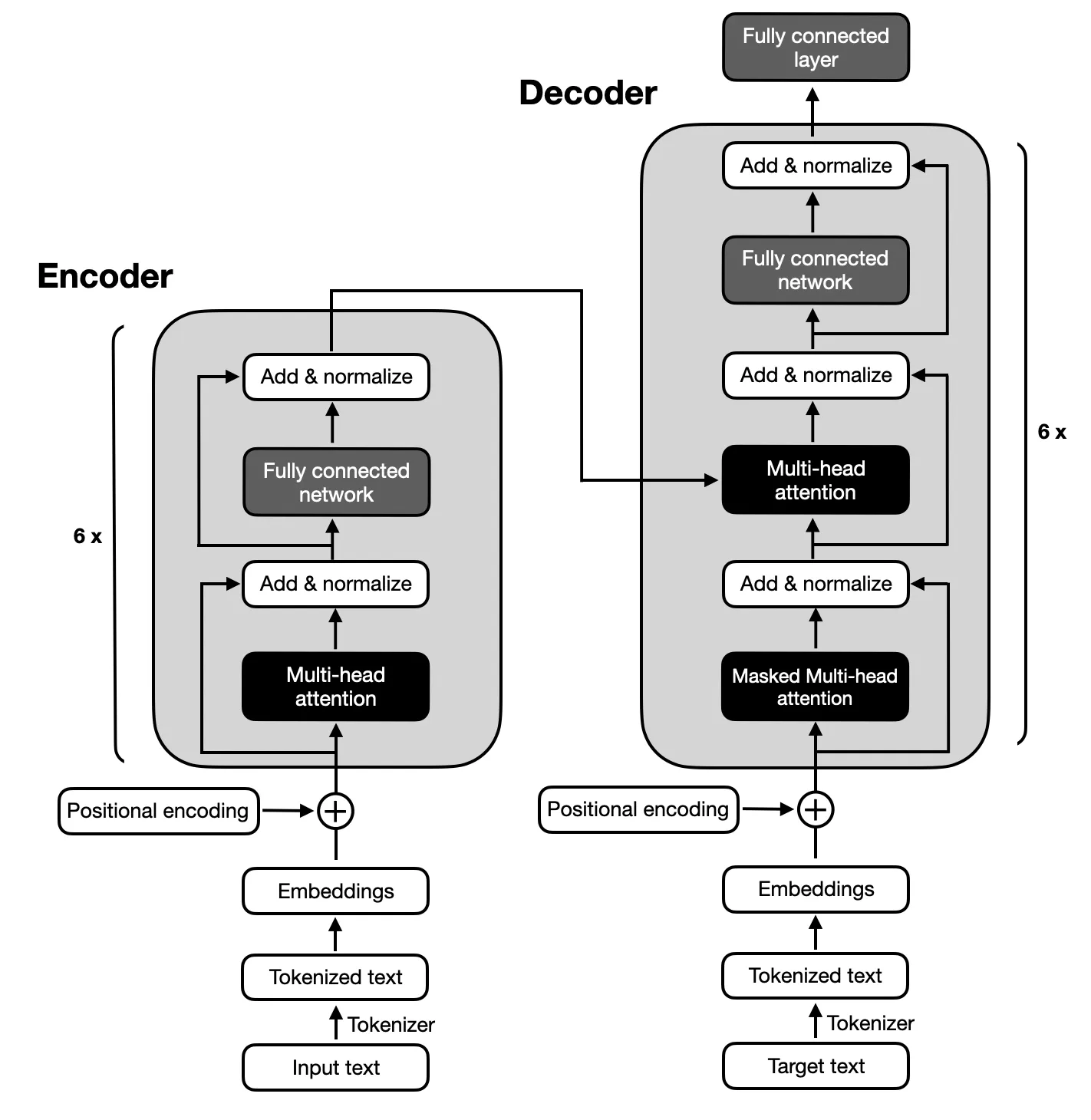
Der Schwerpunkt liegt auf Encoder-Decoder-Modellen, die der von den ursprünglichen Transformers vorgeschlagenen Architektur folgen, da für die Textzusammenfassung eine komplexe Zuordnung zwischen Eingabe- und Ausgabesequenzen erforderlich ist. Encoder-Decoder-Modelle sind in der Lage, Beziehungen innerhalb dieser Sequenzen zu erfassen und sind daher für diese Aufgabe geeignet.
Stellen Sie sicher, dass Python 3.x auf Ihrem System installiert ist . Führen Sie dann die folgenden Schritte aus, um Ihre Umgebung einzurichten:
$ xcode-select --install
$ pip3 install --upgrade pip
$ pip3 install --upgrade setuptools$ pip3 install -r requirements.txt
python3 main.pyDas Projekt umfasst sechs Hauptphasen:
Der für die Feinabstimmung der T5- und BART-Modelle verwendete Datensatz war der Big Patent Dataset, der aus 1,3 Millionen US-Patentdokumenten und ihren von Menschen verfassten abstrakten Zusammenfassungen besteht. Jedes Dokument in diesem Datensatz ist nach einem Cooperative Patent Classification (CPC)-Code kategorisiert, der ein breites Themenspektrum von menschlichen Notwendigkeiten bis hin zu Physik und Elektrizität abdeckt. Diese Vielfalt stellt sicher, dass die Modelle auf eine große Vielfalt an Sprachgebrauch und Fachjargon stoßen, was für die Entwicklung einer robusten Zusammenfassungsfähigkeit von entscheidender Bedeutung ist.
Der Big Patent Dataset wurde aufgrund seiner Relevanz für das Projektziel, komplexe Dokumente zusammenzufassen, ausgewählt. Patente sind von Natur aus detailliert und technisch, was sie zu einer idealen Herausforderung macht, um die Fähigkeit der Modelle zu testen, Informationen zu verdichten und gleichzeitig den Kerninhalt und -kontext zu bewahren. Das strukturierte Format des Datensatzes und das Vorhandensein hochwertiger Zusammenfassungen bilden eine solide Grundlage für das Training und die Bewertung der Leistung der Modelle bei der Erstellung genauer und kohärenter Zusammenfassungen.
Die Leistung der Modelle wurde anhand der ROUGE-Metrik bewertet, wobei ihre Fähigkeit hervorgehoben wurde, Zusammenfassungen zu erstellen, die eng an von Menschen verfassten Zusammenfassungen ausgerichtet sind. Sowohl das BART- als auch das T5-Modell wurden mithilfe des Big Patent Datasets verfeinert, wobei der Schwerpunkt auf der Erzielung einer qualitativ hochwertigen abstrakten Zusammenfassung lag.
| Metrisch | Wert |
|---|---|
| Bewertungsverlust (Eval Loss) | 1.9244 |
| Rouge-1 | 0,5007 |
| Rouge-2 | 0,2704 |
| Rouge-L | 0,3627 |
| Rouge-Lsum | 0,3636 |
| Durchschnittliche Generationslänge (Gen Len) | 122.1489 |
| Laufzeit (Sekunden) | 1459.3826 |
| Proben pro Sekunde | 1.312 |
| Schritte pro Sekunde | 0,164 |
| Metrisch | Wert |
|---|---|
| Bewertungsverlust (Eval Loss) | 1,9984 |
| Rouge-1 | 0,503 |
| Rouge-2 | 0,286 |
| Rouge-L | 0,3813 |
| Rouge-Lsum | 0,3813 |
| Durchschnittliche Generationslänge (Gen Len) | 151.918 |
| Laufzeit (Sekunden) | 714.4344 |
| Proben pro Sekunde | 2.679 |
| Schritte pro Sekunde | 0,336 |


