airllm
1.0.0

Schnellstart | Konfigurationen | MacOS | Beispiel-Notizbücher | FAQ
AirLLM optimiert die Nutzung des Inferenzspeichers und ermöglicht die Ausführung von Inferenzen für 70 B große Sprachmodelle auf einer einzigen 4-GB-GPU-Karte ohne Quantisierung, Destillation und Bereinigung. Und Sie können 405B Llama3.1 jetzt auf 8 GB VRAM ausführen.
[20.08.2024] v2.11.0: Unterstützt Qwen2.5
[18.08.2024] v2.10.1 Unterstützt CPU-Inferenz. Unterstützt nicht fragmentierte Modelle. Danke @NavodPeiris für die tolle Arbeit!
[30.07.2024] Unterstützt Llama3.1 405B (Beispiel-Notebook). Unterstützt 8-Bit/4-Bit-Quantisierung .
[20.04.2024] AirLLM unterstützt Llama3 bereits nativ. Führen Sie Llama3 70B auf einer 4-GB-Einzel-GPU aus.
[25.12.2023] v2.8.2: Unterstützt MacOS mit 70 Milliarden großen Sprachmodellen.
[20.12.2023] v2.7: Unterstützt AirLLMMixtral.
[20.12.2023] v2.6: AutoModel hinzugefügt, Modelltyp automatisch erkennen, keine Notwendigkeit, eine Modellklasse bereitzustellen, um das Modell zu initialisieren.
[18.12.2023] v2.5: Vorabruf hinzugefügt, um das Laden und Berechnen des Modells zu überlappen. 10 % Geschwindigkeitsverbesserung.
[03.12.2023] Unterstützung für ChatGLM , QWen , Baichuan , Mistral und InternLM hinzugefügt!
[02.12.2023] Unterstützung für Safetensoren hinzugefügt. Unterstützt jetzt alle Top-10-Modelle in der Open-LM-Bestenliste.
[01.12.2023] airllm 2.0. Unterstützt Komprimierungen: 3-fache Laufzeitbeschleunigung!
[20.11.2023] airllm Erstversion!
Installieren Sie zunächst das Airllm-Pip-Paket.
pip install airllmInitialisieren Sie dann AirLLMLlama2, übergeben Sie die Huggingface-Repo-ID des verwendeten Modells oder den lokalen Pfad, und die Inferenz kann ähnlich wie bei einem regulären Transformatormodell durchgeführt werden.
( Sie können den Pfad zum Speichern des geteilten Schichtmodells auch über „layer_shards_ saving_path“ angeben, wenn Sie AirLLMLlama2 initieren.
from airllm import AutoModel
MAX_LENGTH = 128
# could use hugging face model repo id:
model = AutoModel . from_pretrained ( "garage-bAInd/Platypus2-70B-instruct" )
# or use model's local path...
#model = AutoModel.from_pretrained("/home/ubuntu/.cache/huggingface/hub/models--garage-bAInd--Platypus2-70B-instruct/snapshots/b585e74bcaae02e52665d9ac6d23f4d0dbc81a0f")
input_text = [
'What is the capital of United States?' ,
#'I like',
]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH ,
padding = False )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 20 ,
use_cache = True ,
return_dict_in_generate = True )
output = model . tokenizer . decode ( generation_output . sequences [ 0 ])
print ( output )Hinweis: Bei der Inferenz wird das Originalmodell zunächst schichtweise zerlegt und gespeichert. Bitte stellen Sie sicher, dass im Huggingface-Cache-Verzeichnis ausreichend Speicherplatz vorhanden ist.
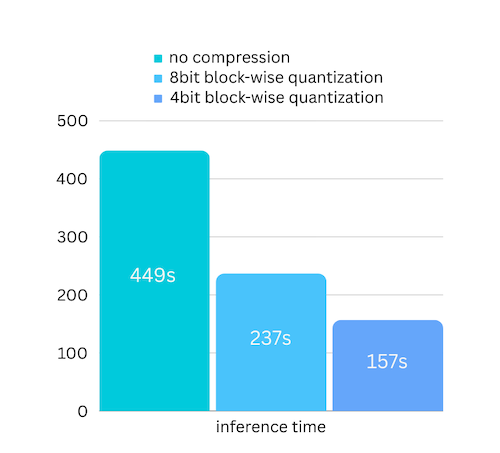
Wir haben gerade eine Modellkomprimierung hinzugefügt, die auf einer blockweisen Quantisierung basierenden Modellkomprimierung basiert. Dadurch kann die Inferenzgeschwindigkeit um bis zu das Dreifache gesteigert werden, bei nahezu vernachlässigbarem Genauigkeitsverlust! (Weitere Informationen zur Leistungsbewertung und warum wir in diesem Artikel blockweise Quantisierung verwenden)
pip install -U bitsandbytes bitsandbytes sicher, dass Sie bitsandbytes installiert habenpip install -U airllm model = AutoModel . from_pretrained ( "garage-bAInd/Platypus2-70B-instruct" ,
compression = '4bit' # specify '8bit' for 8-bit block-wise quantization
)Bei der Quantisierung müssen normalerweise sowohl Gewichte als auch Aktivierungen quantisiert werden, um die Dinge wirklich zu beschleunigen. Dadurch wird es schwieriger, die Genauigkeit aufrechtzuerhalten und die Auswirkungen von Ausreißern bei allen Arten von Eingaben zu vermeiden.
Während in unserem Fall der Engpass hauptsächlich beim Laden der Festplatte liegt, müssen wir nur die Ladegröße des Modells verkleinern. Wir können also nur den Gewichtsanteil quantisieren, was die Genauigkeit einfacher gewährleistet.
Bei der Initialisierung des Modells unterstützen wir die folgenden Konfigurationen:
Installieren Sie einfach airllm und führen Sie den Code genauso aus wie unter Linux. Weitere Informationen finden Sie im Schnellstart.
Beispiel [Python-Notebook] (https://github.com/lyogavin/airllm/blob/main/air_llm/examples/run_on_macos.ipynb)
Beispiel-Colabs hier:
from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel . from_pretrained ( "THUDM/chatglm3-6b-base" )
input_text = [ 'What is the capital of China?' ,]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH ,
padding = True )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 5 ,
use_cache = True ,
return_dict_in_generate = True )
model . tokenizer . decode ( generation_output . sequences [ 0 ]) from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel . from_pretrained ( "Qwen/Qwen-7B" )
input_text = [ 'What is the capital of China?' ,]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 5 ,
use_cache = True ,
return_dict_in_generate = True )
model . tokenizer . decode ( generation_output . sequences [ 0 ]) from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel . from_pretrained ( "baichuan-inc/Baichuan2-7B-Base" )
#model = AutoModel.from_pretrained("internlm/internlm-20b")
#model = AutoModel.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
input_text = [ 'What is the capital of China?' ,]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 5 ,
use_cache = True ,
return_dict_in_generate = True )
model . tokenizer . decode ( generation_output . sequences [ 0 ])Ein Großteil des Codes basiert auf der großartigen Arbeit von SimJeg beim Kaggle-Prüfungswettbewerb. Großes Lob an SimJeg:
GitHub-Konto @SimJeg, der Code auf Kaggle, die zugehörige Diskussion.
safetensors_rust.SafetensorError: Fehler beim Deserialisieren des Headers: MetadataIncompleteBuffer
Wenn dieser Fehler auftritt, liegt die wahrscheinlichste Ursache darin, dass Ihnen der Speicherplatz ausgeht. Der Prozess der Aufteilung des Modells ist sehr datenträgerintensiv. Sehen Sie sich das an. Möglicherweise müssen Sie Ihren Speicherplatz erweitern, den Huggingface-Cache löschen und erneut ausführen.
Höchstwahrscheinlich laden Sie das QWen- oder ChatGLM-Modell mit der Llama2-Klasse. Versuchen Sie Folgendes:
Für QWen-Modell:
from airllm import AutoModel #<----- instead of AirLLMLlama2
AutoModel . from_pretrained (...)Für das ChatGLM-Modell:
from airllm import AutoModel #<----- instead of AirLLMLlama2
AutoModel . from_pretrained (...)Einige Modelle sind Gated-Modelle und erfordern ein Huggingface-API-Token. Sie können hf_token bereitstellen:
model = AutoModel . from_pretrained ( "meta-llama/Llama-2-7b-hf" , #hf_token='HF_API_TOKEN')Der Tokenizer einiger Modelle verfügt nicht über ein Padding-Token. Sie können also ein Padding-Token festlegen oder einfach die Padding-Konfiguration deaktivieren:
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH ,
padding = False #<----------- turn off padding
)Wenn Sie AirLLM für Ihre Recherche nützlich finden und es zitieren möchten, verwenden Sie bitte den folgenden BibTex-Eintrag:
@software{airllm2023,
author = {Gavin Li},
title = {AirLLM: scaling large language models on low-end commodity computers},
url = {https://github.com/lyogavin/airllm/},
version = {0.0},
year = {2023},
}
Willkommene Beiträge, Ideen und Diskussionen!
Wenn Sie es nützlich finden, bitte oder spendieren Sie mir einen Kaffee!


