fastsag
1.0.0
Dies ist eine PyTorch/GPU-Implementierung des IJCAI 2024-Papiers FastSAG: Towards Fast Non-Autoregressive Singing Accompaniment Generation. Die Demoseite finden Sie unter Demo.
@article{chen2024fastsag,
title={FastSAG: Towards Fast Non-Autoregressive Singing Accompaniment Generation},
author={Chen, Jianyi and Xue, Wei and Tan, Xu and Ye, Zhen and Liu, Qifeng and Guo, Yike},
journal={arXiv preprint arXiv:2405.07682},
year={2024}
}Laden Sie diesen Code herunter:
git clone https://github.com/chenjianyi/fastsag/ cd fastsag
Laden Sie den Fastsag-Checkpoint hier herunter und geben Sie alle Gewichte in Fastsag/Gewichte ein
BigvGAN-Checkpoints können von BigvGAN heruntergeladen werden. Der von uns verwendete Prüfpunkt ist „bigvgan_24khz_100band“. Ich aktualisiere BigvGAN auf BigvGAN-v2 und die Prüfpunkte werden automatisch heruntergeladen.
Vorab trainierte MERT-Kontrollpunkte würden automatisch von Huggingface heruntergeladen. Bitte stellen Sie sicher, dass Ihr Server auf Huggingface zugreifen kann.
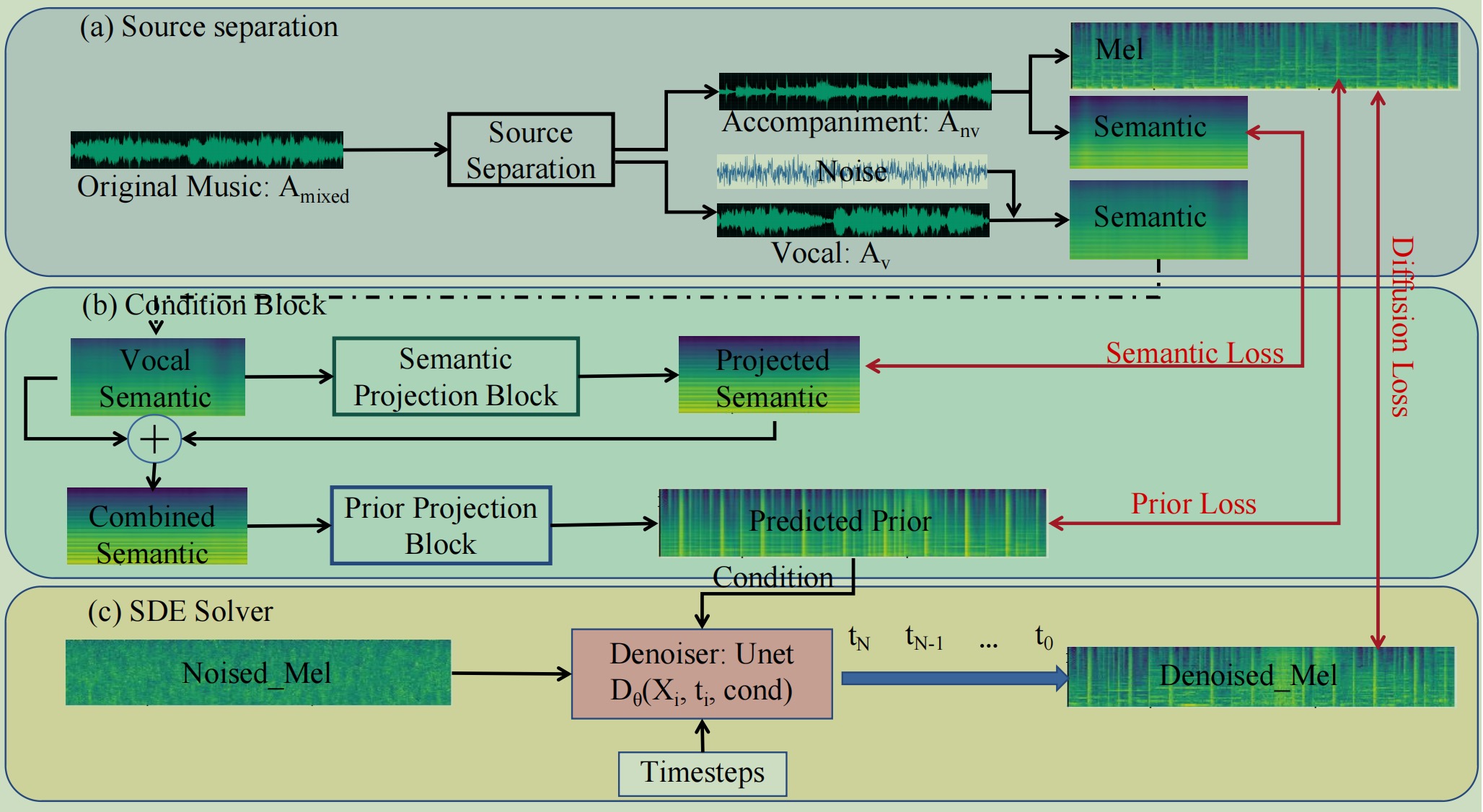
Quellentrennung:
cd preprocessing python3 demucs_processing.py # you may need to change root_dir and out_dir in this file
Clipping auf 10 Sekunden und Filtern hervorstechender Clips
python3 clip_to_10s.py # change src_root and des_root for your dataset
cd ../sde_diffusion python3 train.py --data_dir YOUR_TRAIN_DATA --data_dir_testset YOUR_TEST_DATA --results_folder RESULTS
python3 generate.py --ckpt TRAINED_MODEL --data_dir DATA_DIR --result_dir OUTPUT
Grad-TTS.
CoMoSpeech


