langchain opensearch rag
1.0.0
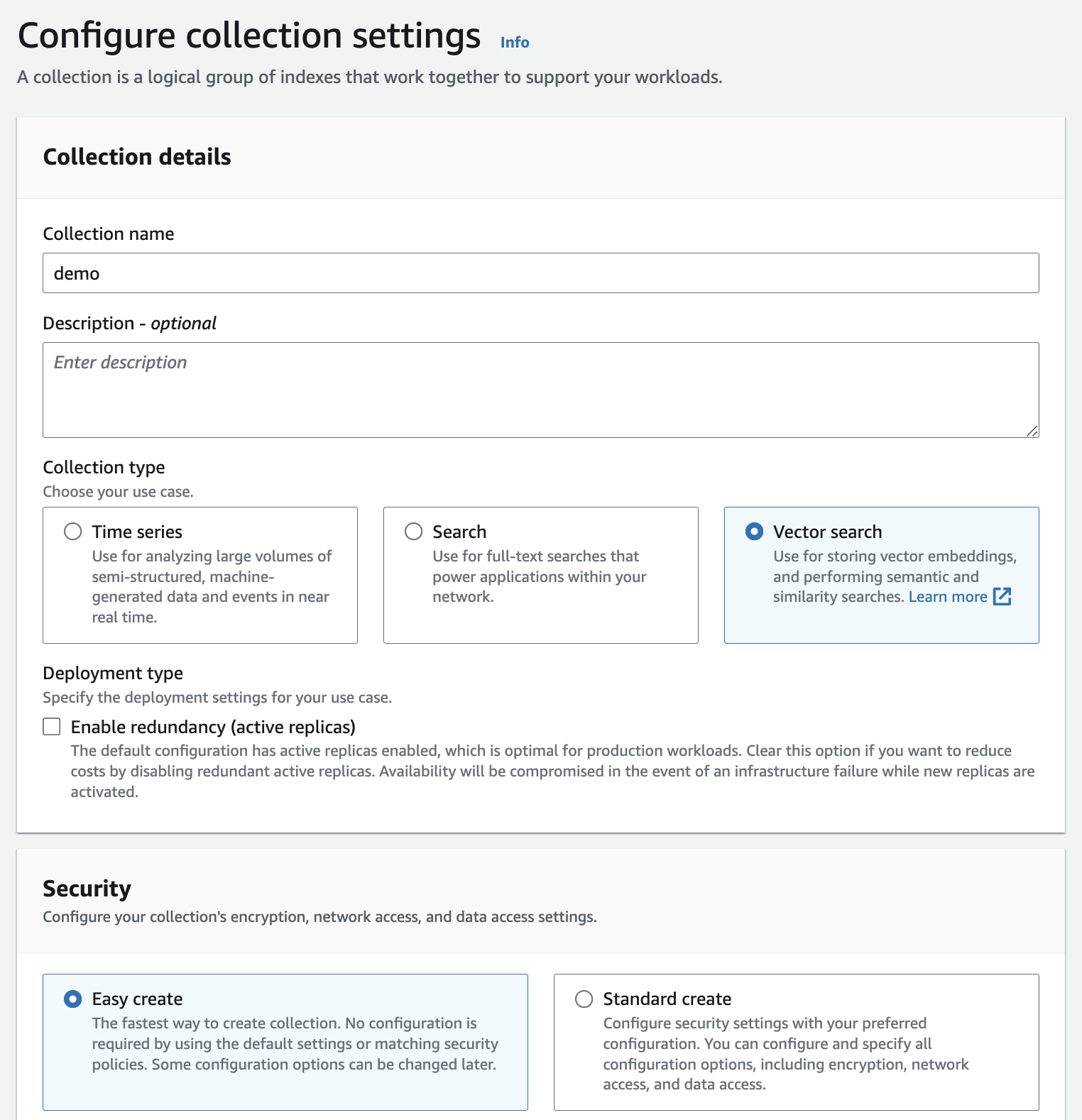
Erstellen Sie eine Amazon OpenSearch Serverless-Sammlung (geben Sie Vector search ein und wählen Sie die Option „Easy create“ ) – Dokumentation.
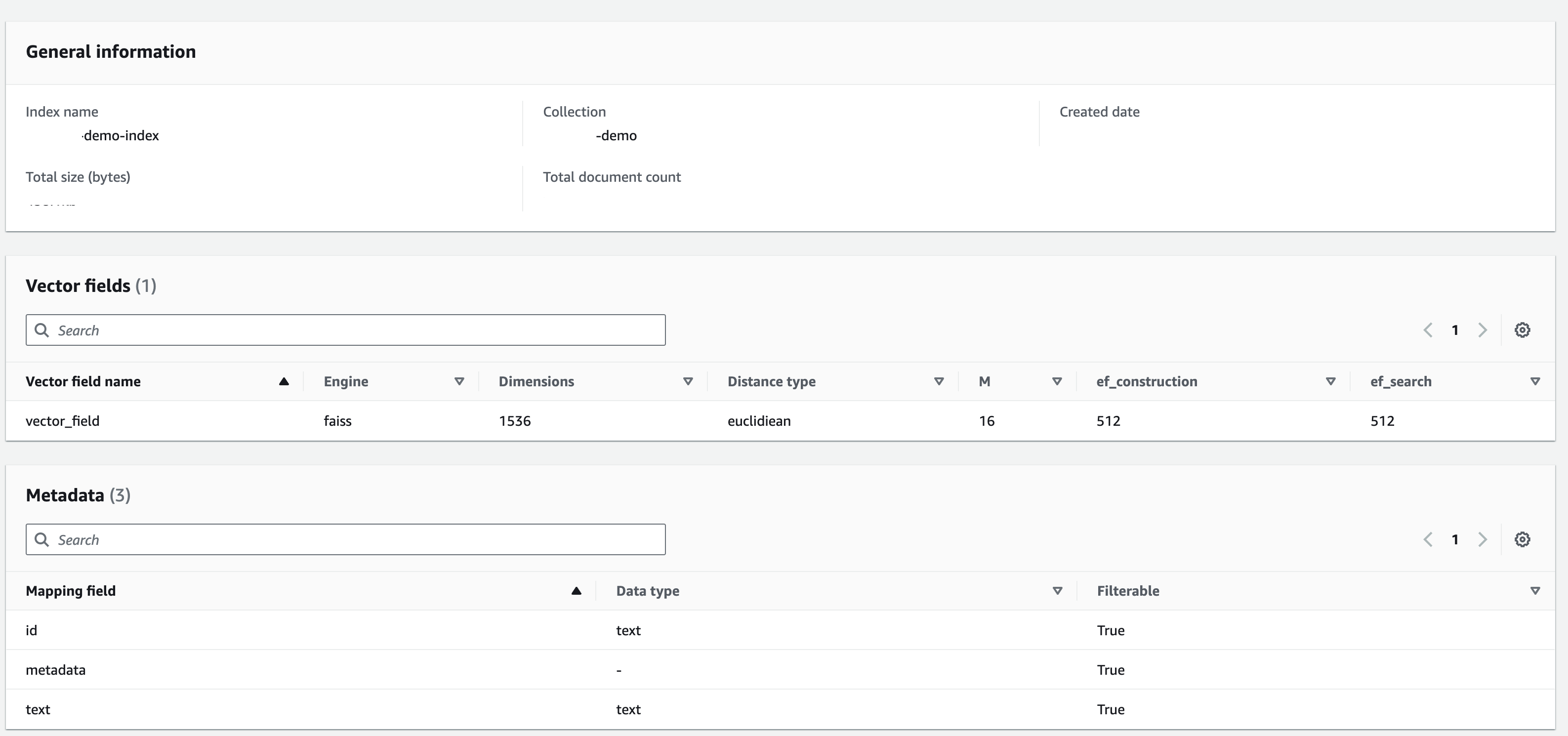
Erstellen Sie einen Index mit der folgenden Konfiguration:
Laden Sie den Amazon-Aktionärsbrief 2022 herunter und platzieren Sie ihn im selben Verzeichnis.
Erstellen Sie eine .env Datei und geben Sie die folgenden Informationen zu Ihrem Amazon OpenSearch-Setup an:
opensearch_index_name= ' <enter name> '
opensearch_url= ' <enter URL> '
engine= ' faiss '
vector_field= ' vector_field '
text_field= ' text '
metadata_field= ' metadata ' Stellen Sie sicher, dass Sie Amazon Bedrock für den Zugriff von Ihrem lokalen Computer aus konfiguriert haben. Außerdem benötigen Sie Zugriff auf das Einbettungsmodell amazon.titan-embed-text-v1 und das Modell anthropic.claude-v2 in Amazon Bedrock – befolgen Sie diese Anweisungen für Details.
PDF-Daten laden:
python3 -m venv myenv
source myenv/bin/activate
pip3 install -r requirements.txt
python3 load.pyÜberprüfen Sie die Daten in der OpenSearch-Sammlung
streamlit run app_semantic_search.py --server.port 8080Sie können Fragen stellen, wie zum Beispiel:
What is Amazon ' s doing in the field of generative AI?
What were the key challenges Amazon faced in 2022?
What were some of the important investments and initiatives mentioned in the letter? 
In einem anderen Terminal:
source myenv/bin/activate
streamlit run app_rag.py --server.port 8081Sie können Fragen stellen, wie zum Beispiel:
What is Amazon ' s doing in the field of generative AI?
What were the key challenges Amazon faced in 2022?
What were some of the important investments and initiatives mentioned in the letter? 


