JoyVASA
1.0.0
Xuyang Cao 1* Guoxin Wang 12* Sheng Shi 1* Jun Zhao 1 Yang Yao 1
Jintao Fei 1 Minyu Gao 1
1 JD Health International Inc. 2 Zhejiang-Universität
Audiogesteuerte Porträtanimationen haben mit diffusionsbasierten Modellen erhebliche Fortschritte gemacht und die Videoqualität und Lippensynchronisationsgenauigkeit verbessert. Die zunehmende Komplexität dieser Modelle hat jedoch zu Ineffizienzen beim Training und bei der Inferenz sowie zu Einschränkungen bei der Videolänge und der Kontinuität zwischen Bildern geführt. In diesem Artikel schlagen wir JoyVASA vor, eine diffusionsbasierte Methode zur Erzeugung von Gesichtsdynamik und Kopfbewegungen in audiogesteuerten Gesichtsanimationen. Konkret führen wir in der ersten Phase ein entkoppeltes Gesichtsdarstellungs-Framework ein, das dynamische Gesichtsausdrücke von statischen 3D-Gesichtsdarstellungen trennt. Durch diese Entkopplung kann das System längere Videos generieren, indem es eine beliebige statische 3D-Gesichtsdarstellung mit dynamischen Bewegungssequenzen kombiniert. Anschließend wird in der zweiten Stufe ein Diffusionstransformator darauf trainiert, Bewegungssequenzen direkt aus Audiohinweisen zu generieren, unabhängig von der Charakteridentität. Schließlich nutzt ein im ersten Schritt trainierter Generator die 3D-Gesichtsdarstellung und die generierten Bewegungssequenzen als Eingaben, um hochwertige Animationen zu rendern. Mit der entkoppelten Gesichtsdarstellung und dem identitätsunabhängigen Bewegungsgenerierungsprozess geht JoyVASA über menschliche Porträts hinaus und animiert Tiergesichter nahtlos. Das Modell wird auf einem Hybriddatensatz aus privaten chinesischen und öffentlichen englischen Daten trainiert, was eine mehrsprachige Unterstützung ermöglicht. Experimentelle Ergebnisse bestätigen die Wirksamkeit unseres Ansatzes. Zukünftige Arbeiten werden sich auf die Verbesserung der Echtzeitleistung und die Verfeinerung der Ausdruckskontrolle konzentrieren, um die Anwendungen des Frameworks in der Porträtanimation weiter zu erweitern.
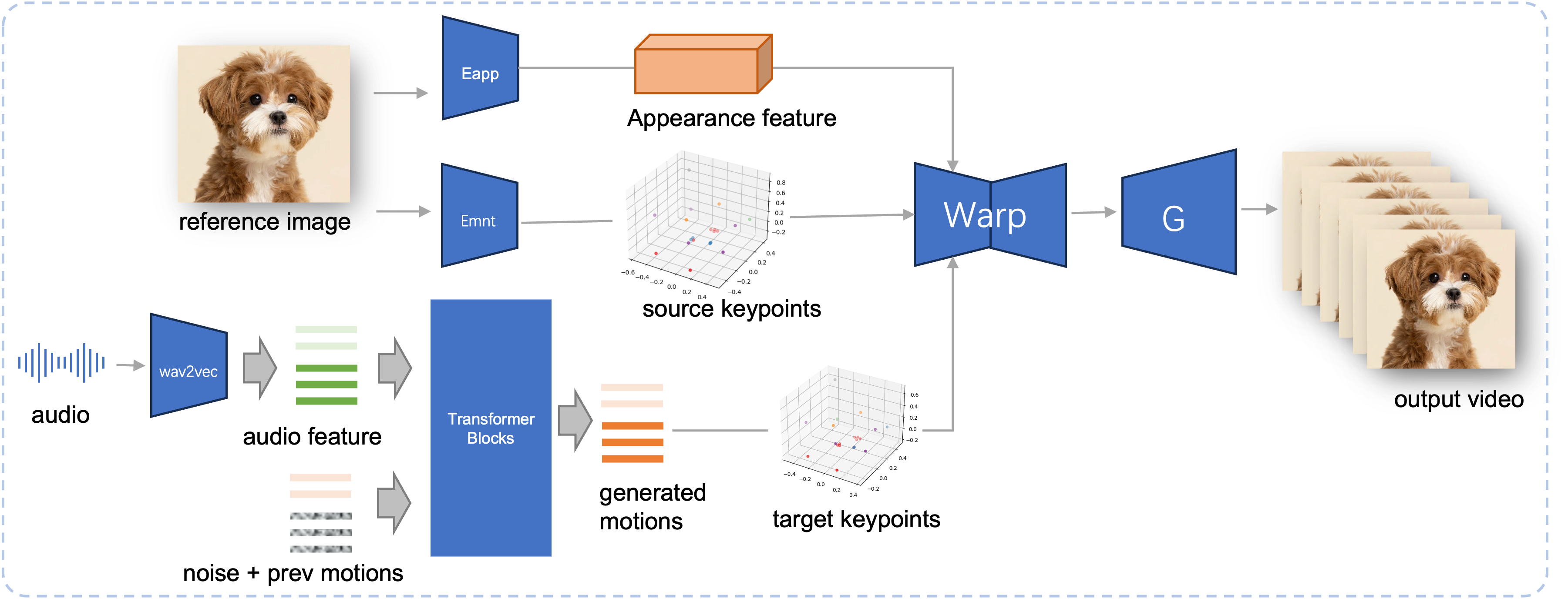
Inferenzpipeline des vorgeschlagenen JoyVASA. Ausgehend von einem Referenzbild extrahieren wir zunächst das 3D-Gesichtserscheinungsmerkmal mithilfe des Erscheinungsbild-Encoders in LivePortrait sowie eine Reihe erlernter 3D-Schlüsselpunkte mithilfe des Bewegungs-Encoders. Für die Eingabesprache werden die Audiomerkmale zunächst mit dem wav2vec2-Encoder extrahiert. Die audiogesteuerten Bewegungssequenzen werden dann mithilfe eines Diffusionsmodells abgetastet, das in der zweiten Stufe im Schiebefenstermodus trainiert wurde. Unter Verwendung der 3D-Schlüsselpunkte des Referenzbilds und der abgetasteten Zielbewegungssequenzen werden die Zielschlüsselpunkte berechnet. Schließlich wird die 3D-Gesichtserscheinungsfunktion basierend auf den Quell- und Ziel-Schlüsselpunkten verzerrt und von einem Generator gerendert, um das endgültige Ausgabevideo zu erzeugen.
Systemanforderungen:
Ubuntu:
Getestet auf Ubuntu 20.04, Cuda 11.3
Getestete GPUs: A100
Windows:
Getestet unter Windows 11, CUDA 12.1
Getestete GPUs: RTX 4060 Laptop 8 GB VRAM GPU
Umgebung erstellen:
# 1. Basisumgebung erstellenconda create -n joyvasa python=3.10 -y Conda aktiviert Joyvasa # 2. Installieren Sie „requirementspip install -r require.txt“# 3. Installieren Sie das ffmpegsudo apt-get update sudo apt-get install ffmpeg -y# 4. Installieren Sie MultiScaleDeformableAttentioncd src/utils/dependencies/XPose/models/UniPose/ops python setup.py build installcd - # gleich cd ../../../../../../../
Stellen Sie sicher, dass Sie git-lfs installiert haben und laden Sie alle folgenden Prüfpunkte auf pretrained_weights herunter:
git lfs installieren Git-Klon https://huggingface.co/jdh-algo/JoyVASA
Wir unterstützen zwei Arten von Audio-Encodern, darunter wav2vec2-base und hubert-chinese.
Führen Sie die folgenden Befehle aus, um vorab trainierte Hubert-Chinese-Gewichte herunterzuladen:
git lfs installieren Git-Klon https://huggingface.co/TencentGameMate/chinese-hubert-base
Führen Sie die folgenden Befehle aus, um die vorab trainierten Gewichte von wav2vec2-base zu erhalten:
git lfs installieren Git-Klon https://huggingface.co/facebook/wav2vec2-base-960h
Notiz
Das Bewegungsgenerierungsmodell mit wav2vec2-Encoder wird später unterstützt.
# !pip install -U "huggingface_hub[cli]"huggingface-cli download KwaiVGI/LivePortrait --local-dir pretrained_weights --exclude "*.git*" "README.md" "docs"
Weitere Download-Methoden finden Sie unter Liveportrait.
pretrained_weights Das endgültige Verzeichnis pretrained_weights sollte wie folgt aussehen:
./pretrained_weights/
├── insightface
│ └── models
│ └── buffalo_l
│ ├── 2d106det.onnx
│ └── det_10g.onnx
├── JoyVASA
│ ├── motion_generator
│ │ └── iter_0020000.pt
│ └── motion_template
│ └── motion_template.pkl
├── liveportrait
│ ├── base_models
│ │ ├── appearance_feature_extractor.pth
│ │ ├── motion_extractor.pth
│ │ ├── spade_generator.pth
│ │ └── warping_module.pth
│ ├── landmark.onnx
│ └── retargeting_models
│ └── stitching_retargeting_module.pth
├── liveportrait_animals
│ ├── base_models
│ │ ├── appearance_feature_extractor.pth
│ │ ├── motion_extractor.pth
│ │ ├── spade_generator.pth
│ │ └── warping_module.pth
│ ├── retargeting_models
│ │ └── stitching_retargeting_module.pth
│ └── xpose.pth
├── TencentGameMate:chinese-hubert-base
│ ├── chinese-hubert-base-fairseq-ckpt.pt
│ ├── config.json
│ ├── gitattributes
│ ├── preprocessor_config.json
│ ├── pytorch_model.bin
│ └── README.md
└── wav2vec2-base-960h
├── config.json
├── feature_extractor_config.json
├── model.safetensors
├── preprocessor_config.json
├── pytorch_model.bin
├── README.md
├── special_tokens_map.json
├── tf_model.h5
├── tokenizer_config.json
└── vocab.jsonNotiz
Der Ordner TencentGameMate:chinese-hubert-base in Windows sollte in chinese-hubert-base umbenannt werden.
Tier:
python inference.py -r asset/examples/imgs/joyvasa_001.png -a asset/examples/audios/joyvasa_001.wav --animation_mode animal --cfg_scale 2.0
Menschlich:
python inference.py -r asset/examples/imgs/joyvasa_003.png -a asset/examples/audios/joyvasa_003.wav --animation_mode human --cfg_scale 2.0
Sie können cfg_scale ändern, um Ergebnisse mit unterschiedlichen Ausdrücken und Posen zu erhalten.
Notiz
Wenn der Animationsmodus und das Referenzbild nicht übereinstimmen, kann dies zu falschen Ergebnissen führen.
Verwenden Sie den folgenden Befehl, um die Webdemo zu starten:
Python app.py
Die Demo wird unter http://127.0.0.1:7862 erstellt.
Wenn Sie unsere Arbeit hilfreich finden, denken Sie bitte darüber nach, uns zu zitieren:
@misc{cao2024joyvasaportraitanimalimage,
title={JoyVASA: Portrait and Animal Image Animation with Diffusion-Based Audio-Driven Facial Dynamics and Head Motion Generation},
author={Xuyang Cao and Guoxin Wang and Sheng Shi and Jun Zhao and Yang Yao and Jintao Fei and Minyu Gao},
year={2024},
eprint={2411.09209},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2411.09209},
}Wir möchten den Mitwirkenden der Repositories LivePortrait, Open Facevid2vid, InsightFace, X-Pose, DiffPoseTalk, Hallo, wav2vec 2.0, Chinese Speech Pretrain, Q-Align, Syncnet und VBench für ihre offene Forschung und außergewöhnliche Arbeit danken.


