Adding Private Data to LLMs
1.0.0
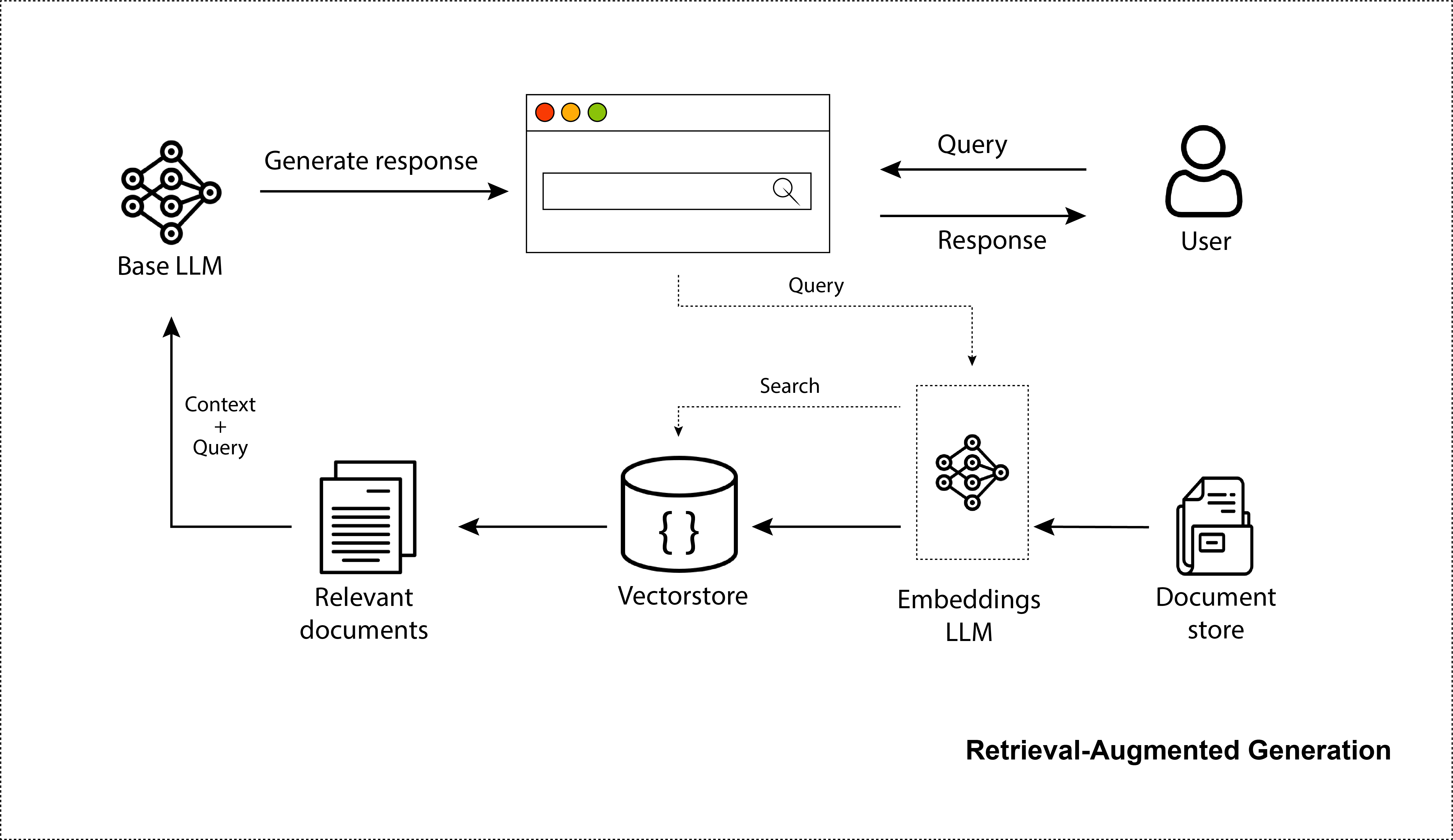
LLMs haben die Welt mit ihrer Fähigkeit verblüfft, realistische Bilder, Code und Dialoge zu erstellen. Zweifellos hat ChatGPT die Welt im Sturm erobert. Millionen nutzen es. Obwohl es sich hervorragend für allgemeines Wissen eignet, kennt es nur die Informationen, auf denen es trainiert wurde, also allgemein verfügbare Internetdaten aus der Zeit vor 2021. Es fehlt das Bewusstsein für Ihre privaten Daten und es bleiben keine Informationen über aktuelle Datenquellen. Um sie in dieser Hinsicht zu verbessern, können wir ihnen Informationen zur Verfügung stellen, die wir aus einem Suchschritt abgerufen haben. Dies macht sie sachlicher und bietet eine bessere Möglichkeit, das Modell mit aktuellen Informationen zu versorgen, ohne dass diese umfangreichen Modelle neu trainiert werden müssen. Genau das ist ein Retrieval-Augmented LLM- oder Retrieval-Augmented Generation (RAG)-System. Tatsächlich wird dieses Repository die Erstellung eines RAG-Systems genau beschreiben und die damit verbundenen Optimierungsschritte erläutern.
LAPPEN
Tech-Stack
Installation
Nützliche Links
Kontakt
LangChain
LamaIndex
Azure OpenAI
Gradio
Klonen Sie das Github-Repository
Git-Klon https://github.com/zekaouinoureddine/Adding-Private-Data-to-LLMs.git
Wechseln Sie mit der Anforderungs-CD in das Projektverzeichnis und stellen Sie sicher, dass Python 3 zusammen mit den erforderlichen Abhängigkeiten installiert ist.
cd Hinzufügen-privater-Daten-zu-LLMs pip install -r Anforderungen.txt
Führen Sie die Gradio-App aus
Python rag.py
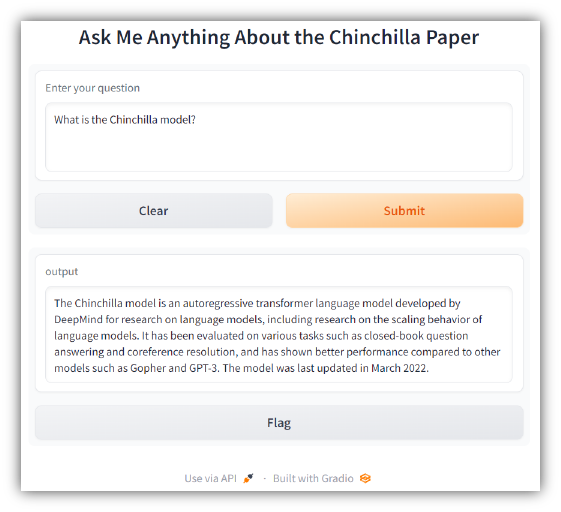
Besuchen Sie http://127.0.0.1:7860 auf Ihrem Computer, um die App zu testen. Sie sollten etwa Folgendes sehen:
| Blog | Plattformform | Sprache | Notizbuch |
|---|---|---|---|
| Fragen Sie Ihre eigenen Daten | Hiberus-Blog | ES | |
| Fragen Sie Ihre eigenen Daten | Medium | DE | |
| Fragen Sie Ihre Webseiten | Hiberus-Blog | ES | |
| Fragen Sie Ihre Webseiten | Medium | DE |
Wenn es dir gefällt, gib ihm ein , dann folge mir auf:
LinkedIn: Nour Eddine ZEKAOUI
Twitter: @NZekaoui
Zurück nach oben


