wikisearch
1.0.0
Streamlit-App für mehrsprachige semantische Suche in über 10 Millionen Wikipedia-Dokumenten, vektorisiert in Einbettungen von Weaviate. Diese Implementierung basiert auf Coheres Blog „Using LLMs for Search“ und dem dazugehörigen Notebook. Es ermöglicht den Vergleich der Leistung der Stichwortsuche , des Dense Retrieval und der Hybridsuche zur Abfrage des Wikipedia-Datensatzes. Darüber hinaus wird die Verwendung von Cohere Rerank zur Verbesserung der Genauigkeit der Ergebnisse und von Cohere Generate zur Bereitstellung einer Antwort auf der Grundlage der Rangfolgeergebnisse demonstriert.
Semantische Suche bezieht sich auf Suchalgorithmen, die bei der Generierung von Ergebnissen die Absicht und kontextuelle Bedeutung von Suchphrasen berücksichtigen, anstatt sich ausschließlich auf die Keyword-Übereinstimmung zu konzentrieren. Es liefert genauere und relevantere Ergebnisse, indem es die Semantik oder Bedeutung hinter der Abfrage versteht.
Eine Einbettung ist ein Vektor (eine Liste) von Gleitkommazahlen, die Daten wie Wörter, Sätze, Dokumente, Bilder oder Audio darstellen. Diese numerische Darstellung erfasst den Kontext, die Hierarchie und die Ähnlichkeit der Daten. Sie können für nachgelagerte Aufgaben wie Klassifizierung, Clustering, Ausreißererkennung und semantische Suche verwendet werden.
Vektordatenbanken wie Weaviate wurden speziell zur Optimierung der Speicher- und Abfragefunktionen für Einbettungen entwickelt. In der Praxis verwendet eine Vektordatenbank eine Kombination verschiedener Algorithmen, die alle an der Suche nach dem Approximate Nearest Neighbor (ANN) beteiligt sind. Diese Algorithmen optimieren die Suche durch Hashing, Quantisierung oder graphbasierte Suche.
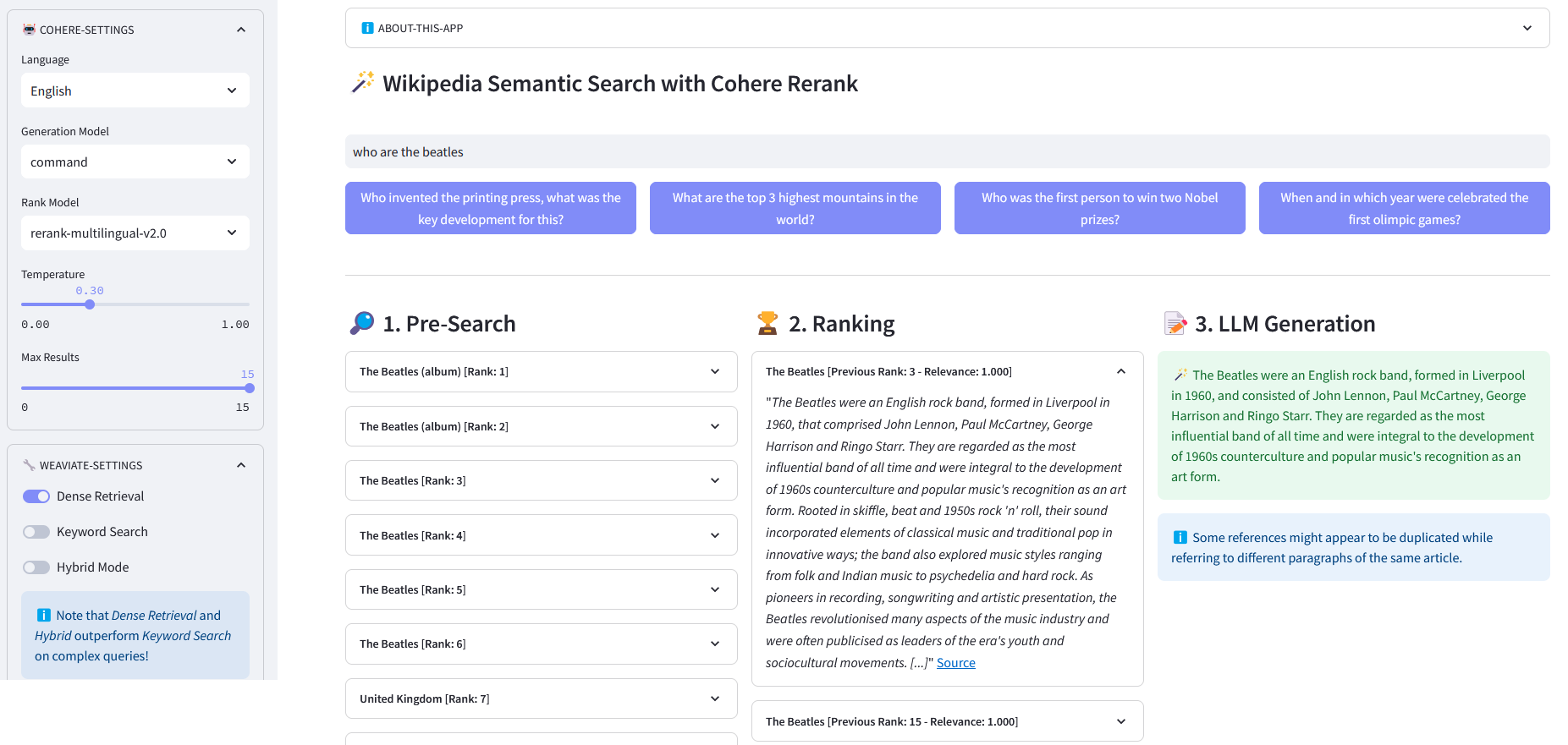
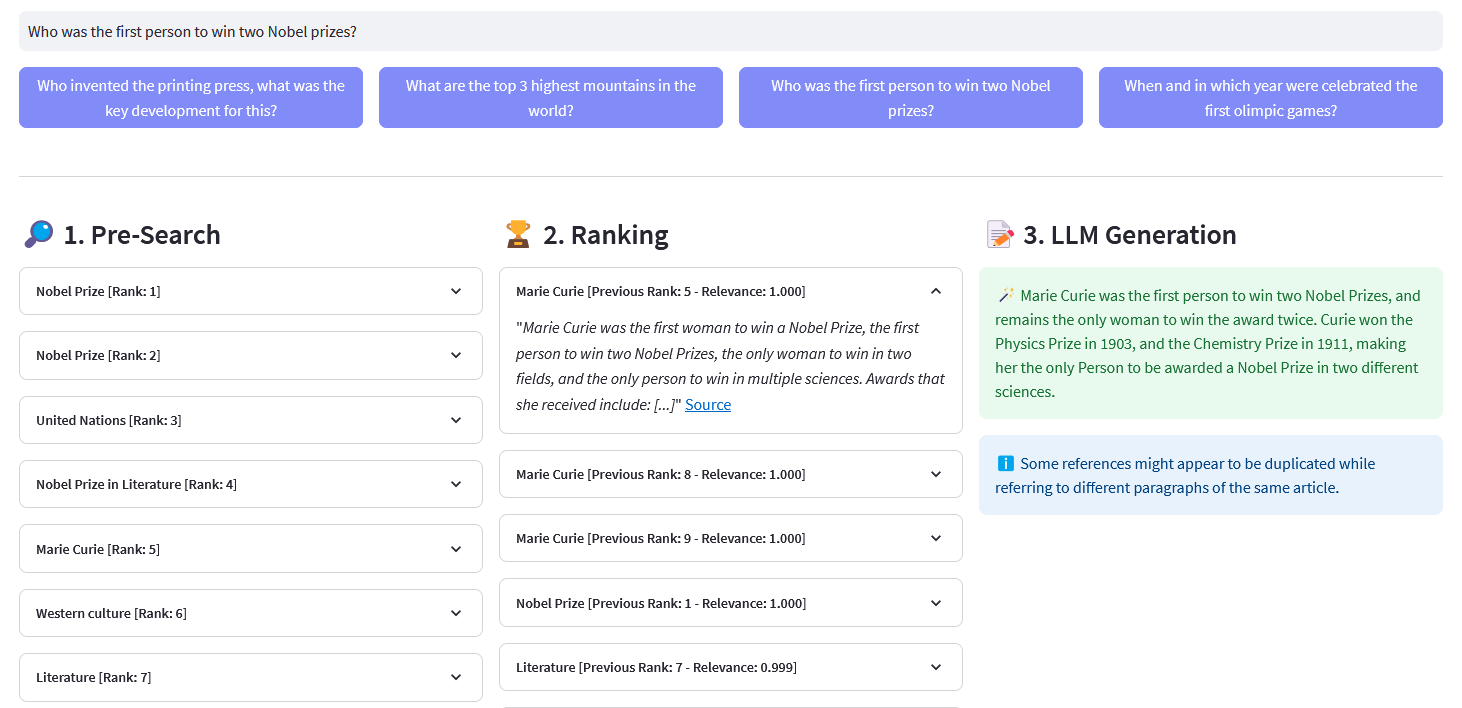
Vorsuche : Vorsuche auf Wikipedia-Einbettungen mit Keyword-Matching , Dense Retrieval oder Hybridsuche :
Keyword-Matching: Es wird nach Objekten gesucht, deren Eigenschaften die Suchbegriffe enthalten. Die Ergebnisse werden gemäß der BM25F-Funktion bewertet:
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_bm25(self, query, lang='en', top_n=10) -> list:""" Führt ein Schlüsselwort aus Suche (sparse retrieval) auf Wikipedia-Artikeln mit in Weaviate gespeicherten Einbettungen: - query (str): Die Suchabfrage - lang (str, optional): Die Sprache der Artikel ist „en“. – top_n (int, optional): Die Anzahl der zurückzugebenden Top-Ergebnisse ist: – list: Liste der Top-Artikel basierend auf der BM25F-Protokollierung .info("with_bm25()")where_filter = {"path": ["lang"],"operator": "Equal","valueString": lang}response = (self.weaviate.query.get("Articles", self.WIKIPEDIA_PROPERTIES)
.with_bm25(query=query)
.with_where(where_filter)
.with_limit(top_n)
.Tun()
)return Response["data"]["Get"]["Articles"]Dense Retrieval: Finden Sie Objekte, die einem rohen (nicht vektorisierten) Text am ähnlichsten sind:
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_neartext(self, query, lang='en', top_n=10) -> list:""" Führt eine Semantik durch Suche (dichter Abruf) auf Wikipedia-Artikeln mit in Weaviate gespeicherten Einbettungen: - query (str): Die Suchabfrage - lang (str, optional): Die Sprache der Artikel ist „en“. – top_n (int, optional): Die Anzahl der zurückzugebenden Top-Ergebnisse ist 10. Rückgabewerte: – Liste der Top-Artikel basierend auf semantischer Ähnlichkeit. ""logging.info("with_neartext()")nearText = {"concepts": [query]
}where_filter = {"path": ["lang"],"operator": "Equal", "valueString": lang}response = (self.weaviate.query.get("Articles", self.WIKIPEDIA_PROPERTIES)
.with_near_text(nearText)
.with_where(where_filter)
.with_limit(top_n)
.Tun()
)return Response['data']['Get']['Articles']Hybridsuche: Erstellt Ergebnisse basierend auf einer gewichteten Kombination von Ergebnissen aus einer Stichwortsuche (bm25) und einer Vektorsuche.
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_hybrid(self, query, lang='en', top_n=10) -> list:""" Führt einen Hybrid durch Suche nach Wikipedia-Artikeln mit in Weaviate gespeicherten Einbettungen: - query (str): Die Suchabfrage. - lang (str, optional): Die Sprache der Artikel 'en'. - top_n (int, optional): Die Anzahl der zurückzugebenden Top-Ergebnisse ist 10. Rückgabewerte: - list: Liste der Top-Artikel basierend auf der Hybridbewertung. )where_filter = {"path": ["lang"],"operator": "Equal", "valueString": lang}response = (self.weaviate.query.get("Articles", self.WIKIPEDIA_PROPERTIES)
.with_hybrid(query=query)
.with_where(where_filter)
.with_limit(top_n)
.Tun()
)return Response["data"]["Get"]["Articles"]ReRank : Cohere Rerank organisiert die Vorsuche neu, indem es jedem Vorsuchergebnis einer Benutzeranfrage einen Relevanzwert zuweist. Im Vergleich zur einbettungsbasierten semantischen Suche liefert sie bessere Suchergebnisse – insbesondere bei komplexen und domänenspezifischen Abfragen.
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def rerank(self, query, document, top_n=10, model='rerank-english-v2.0') -> dict:""" Ordnet eine Liste von Antworten mithilfe der Reranking-API von Cohere neu. Parameter: - query (str): Die Suchabfrage. - Dokumente (list): Liste der zu bearbeitenden Dokumente neu eingestuft werden. - top_n (int, optional): Die Anzahl der zurückgegebenen Top-Neubewertungsergebnisse ist 10. - Modell: Das für die Neubewertung verwendete Modell ist „rerank-english-v2.0“. : Dokumente aus der Cohere-API neu eingestuft.
Quelle: Cohere
Antwortgenerierung : Cohere Generate erstellt eine Antwort basierend auf den Ranglistenergebnissen.
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_llm(self, context, query, Temperature=0.2, model="command", lang="english") -> list:prompt = f""" Verwenden Sie die unten bereitgestellten Informationen, um die Fragen am Ende zu beantworten. / Fügen Sie einige interessante oder relevante Fakten hinzu, die aus dem Kontext extrahiert wurden. / Generieren Sie die Antwort in der Sprache der Anfrage. Wenn Sie können die Sprache der Abfrage nicht bestimmen. Verwenden Sie {lang}. Wenn die Antwort auf die Frage nicht in den bereitgestellten Informationen enthalten ist, generieren Sie „Die Antwort befindet sich nicht im Kontext: {context}“. - Frage: {query} """return self.cohere.generate(prompt=prompt,num_generations=1,max_tokens=1000,temperature=temperature,model=model,
)Klonen Sie das Repository:
[email protected]:dcarpintero/wikisearch.git
Erstellen und aktivieren Sie eine virtuelle Umgebung:
Windows: py -m venv .venv .venvscriptsactivate macOS/Linux python3 -m venv .venv source .venv/bin/activate
Abhängigkeiten installieren:
pip install -r requirements.txt
Webanwendung starten
streamlit run ./app.py
Demo-Web-App, bereitgestellt in Streamlit Cloud und verfügbar unter https://wikisearch.streamlit.app/
Kohärente Neubewertung
Streamlit-Wolke
Das Einbettungsarchiv: Millionen von Wikipedia-Artikeleinbettungen in vielen Sprachen
Verwendung von LLMs für die Suche mit Dense Retrieval und Reranking
Vektordatenbanken
Weaviate-Vektorsuche
Weaviate BM25-Suche
Weaviate Hybrid-Suche


