ssebowa
1.0.0
Ssebowa ist eine Open-Source-Python-Bibliothek, die generative KI-Modelle bereitstellt, darunter:
ssebowa-llm: Ein großes Sprachmodell (LLM) zur Textgenerierung,ssebowa-vllm: Ein visuelles Sprachmodell (VLLM) für visuelles Verständnis,ssebowa-imagen: Ein Bildgenerierungs- und benutzerdefiniertes Feinabstimmungsmodell,Ssebowa-vigen: Ein Videogenerierungsmodell.Mit Ssebowa können Sie ganz einfach Texte generieren, Sprachen übersetzen, verschiedene Arten von kreativen Inhalten schreiben, personalisierte Bilder erstellen und Ihre Fragen auf informative Weise beantworten.
Ausführlichere Informationen zur Verwendung finden Sie in der technischen Dokumentation von Ssebowa
Stellen Sie vor der Ausführung des Skripts sicher, dass die erforderlichen Bibliotheken installiert sind. Sie können dies tun, indem Sie die folgenden Befehle ausführen:
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .Dann installieren Sie Ssebowa
pip install ssebowaWenn Sie diese Befehle in Colab oder Jupyter Notebook ausführen, verwenden Sie bitte Folgendes:
! git clone https://github.com/huggingface/diffusers
! cd diffusers
! pip install .
! pip install ssebowaJetzt können Sie auf die verschiedenen Modelle zugreifen, indem Sie sie aus der Bibliothek importieren:
Ssebowa-Imagen ist ein Open-Source-Bildsynthesemodell, das eine Kombination aus diffusion modeling und generative adversarial networks (GANs) nutzt, um hochwertige Bilder aus text descriptions zu generieren und es auch ermöglicht, Ihre wenigen Fotos in custom model umzuwandeln, das generiert werden kann atemberaubende Bilder Ihres chosen subject . Es nutzt einen 100 billion dataset von Bildern und Textbeschreibungen und ermöglicht so die genaue Erfassung der Nuancen realer Bilder und die effektive Übersetzung von Textbeschreibungen in überzeugende visuelle Darstellungen.
10-20 high-quality Solofotos (jpg or png) vor, z. B. von Ihnen, Freunden, Produkten oder Haustieren usw., und legen Sie sie in einem bestimmten Verzeichnis ab.16GB or more aus. (Wenn Sie SDXL feinabstimmen, benötigen Sie 24 GB VRAM.) from ssebowa.dataset import LocalDataset
from ssebowa.model import SdSsebowaModel
from ssebowa.trainer import LocalTrainer
from ssebowa.utils.image_helpers import display_images
from ssebowa.utils.prompt_helpers import make_promptDATA_DIR = " data " # The directory where you put your prepared photos
OUTPUT_DIR = " models " dataset = LocalDataset(DATA_DIR)
dataset = dataset.preprocess_images(detect_face=True)SUBJECT_NAME = " <YOUR-NAME> "
CLASS_NAME = " person " model = SdSsebowaModel(subject_name=SUBJECT_NAME, class_name=CLASS_NAME)
trainer = LocalTrainer(output_dir=OUTPUT_DIR)
predictor = trainer.fit(model, dataset)
# Use the prompt helper to create an awesome AI avatar!
prompt = next(make_prompt(SUBJECT_NAME, CLASS_NAME))
images = predictor.predict(
prompt, height=768, width=512, num_images_per_prompt=2,
)
display_images(images, fig_size=10)
from ssebowa import Ssebowa_imgen
model = Ssebowa_imgen ()Wie lasst uns „Eine Katze sitzt auf einem Bücherregal“ generieren
image = model.generate_image( " A cat sitting on a bookshelf " )image.save( " cat_on_bookshelf.jpg " )

Ssebowa-vllm ist ein Open-Source-Visual-Large-Language-Modell (VLLM), das von Ssebowa AI entwickelt wurde. Es ist ein leistungsstarkes Werkzeug, mit dem Bilder verstanden werden können. Ssebowa-vllm verfügt über 11 Milliarden visuelle Parameter und 7 Milliarden Sprachparameter und unterstützt das Bildverständnis bei einer Auflösung von 1120*1120.
from ssebowa import ssebowa_vllm
model = ssebowa_vllm ()
response = model.understand(image_path, prompt)
print(response)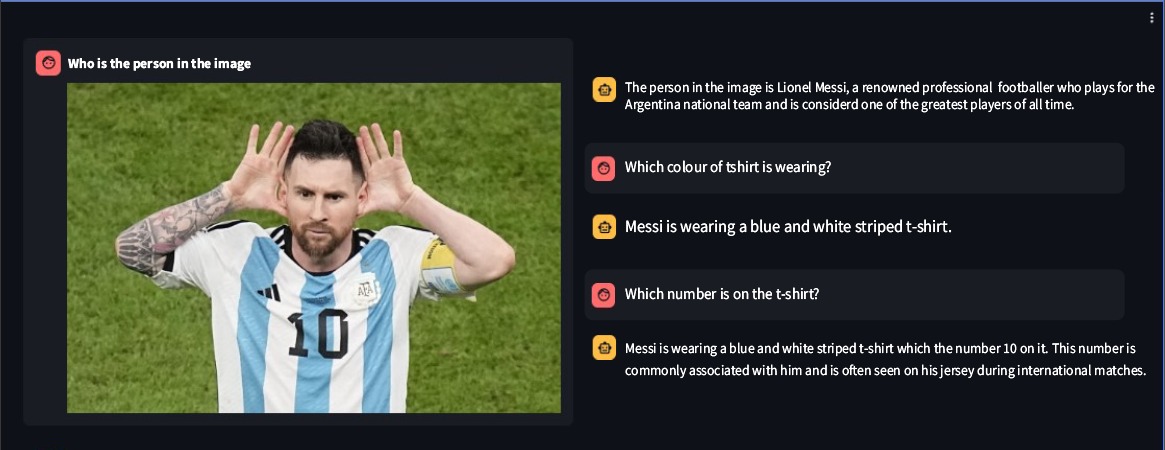
Ssebowa ist offen für Beiträge! Richtlinien in Bearbeitung.
Ssebowa wird unter der Apache-Lizenz 2.0 veröffentlicht.
Wenn Sie Fragen oder Anregungen haben, können Sie gerne ein Problem auf GitHub eröffnen oder uns unter [email protected] kontaktieren


