xTuring
0.1.8


xTuring ermöglicht eine schnelle, effiziente und einfache Feinabstimmung von Open-Source-LLMs wie Mistral, LLaMA, GPT-J und mehr. Durch die Bereitstellung einer benutzerfreundlichen Schnittstelle zur Feinabstimmung von LLMs an Ihre eigenen Daten und Anwendungen erleichtert xTuring das Erstellen, Ändern und Steuern von LLMs. Der gesamte Vorgang kann auf Ihrem Computer oder in Ihrer privaten Cloud durchgeführt werden, um Datenschutz und Sicherheit zu gewährleisten.
Mit xTuring können Sie,
pip install xturing from xturing . datasets import InstructionDataset
from xturing . models import BaseModel
# Load the dataset
instruction_dataset = InstructionDataset ( "./examples/models/llama/alpaca_data" )
# Initialize the model
model = BaseModel . create ( "llama_lora" )
# Finetune the model
model . finetune ( dataset = instruction_dataset )
# Perform inference
output = model . generate ( texts = [ "Why LLM models are becoming so important?" ])
print ( "Generated output by the model: {}" . format ( output ))Den Datenordner finden Sie hier.
Wir freuen uns, die neuesten Verbesserungen unserer xTuring -Bibliothek bekannt zu geben:
LLaMA 2 Integration – Sie können das LLaMA 2 Modell in verschiedenen Konfigurationen verwenden und optimieren: Standard , Standard mit INT8-Präzision , LoRA-Feinabstimmung , LoRA-Feinabstimmung mit INT8-Präzision und LoRA-Feinabstimmung. Optimierung mit INT4-Präzision mithilfe des GenericModel Wrappers und/oder Sie können die Llama2 Klasse von xturing.models verwenden, um das Modell zu testen und zu optimieren. from xturing . models import Llama2
model = Llama2 ()
## or
from xturing . models import BaseModel
model = BaseModel . create ( 'llama2' )Evaluation – Jetzt können Sie jedes Causal Language Model für jeden Datensatz auswerten. Die derzeit unterstützten Metriken sind perplexity . # Make the necessary imports
from xturing . datasets import InstructionDataset
from xturing . models import BaseModel
# Load the desired dataset
dataset = InstructionDataset ( '../llama/alpaca_data' )
# Load the desired model
model = BaseModel . create ( 'gpt2' )
# Run the Evaluation of the model on the dataset
result = model . evaluate ( dataset )
# Print the result
print ( f"Perplexity of the evalution: { result } " )INT4 Precision – Sie können jetzt jedes LLM mit INT4 Precision mithilfe von GenericLoraKbitModel verwenden und optimieren. # Make the necessary imports
from xturing . datasets import InstructionDataset
from xturing . models import GenericLoraKbitModel
# Load the desired dataset
dataset = InstructionDataset ( '../llama/alpaca_data' )
# Load the desired model for INT4 bit fine-tuning
model = GenericLoraKbitModel ( 'tiiuae/falcon-7b' )
# Run the fine-tuning
model . finetune ( dataset ) # Make the necessary imports
from xturing . models import BaseModel
# Initializes the model: quantize the model with weight-only algorithms
# and replace the linear with Itrex's qbits_linear kernel
model = BaseModel . create ( "llama2_int8" )
# Once the model has been quantized, do inferences directly
output = model . generate ( texts = [ "Why LLM models are becoming so important?" ])
print ( output ) # Make the necessary imports
from xturing . datasets import InstructionDataset
from xturing . models import GenericLoraKbitModel
# Load the desired dataset
dataset = InstructionDataset ( '../llama/alpaca_data' )
# Load the desired model for INT4 bit fine-tuning
model = GenericLoraKbitModel ( 'tiiuae/falcon-7b' )
# Generate outputs on desired prompts
outputs = model . generate ( dataset = dataset , batch_size = 10 )Zum Verständnis seiner Anwendung wird eine Untersuchung des Llama LoRA INT4-Arbeitsbeispiels empfohlen.
Um einen erweiterten Einblick zu erhalten, sollten Sie sich das im Repository verfügbare GenericModel-Arbeitsbeispiel ansehen.

$ xturing chat -m " <path-to-model-folder> "
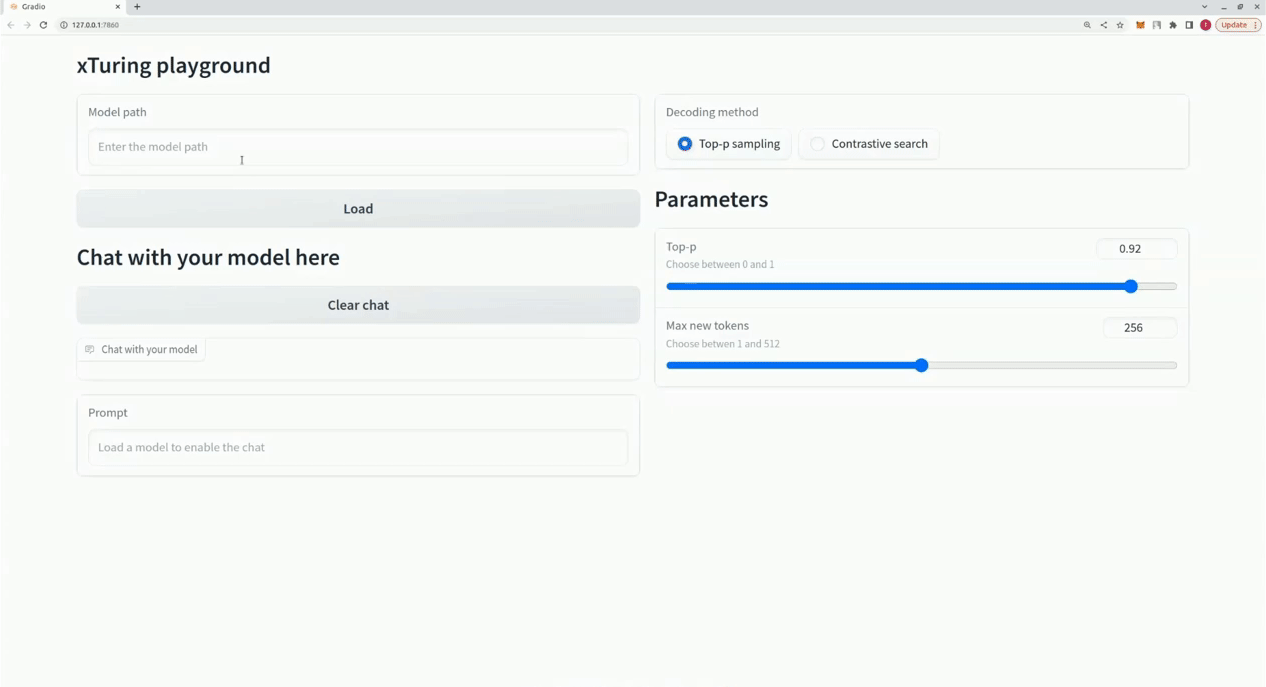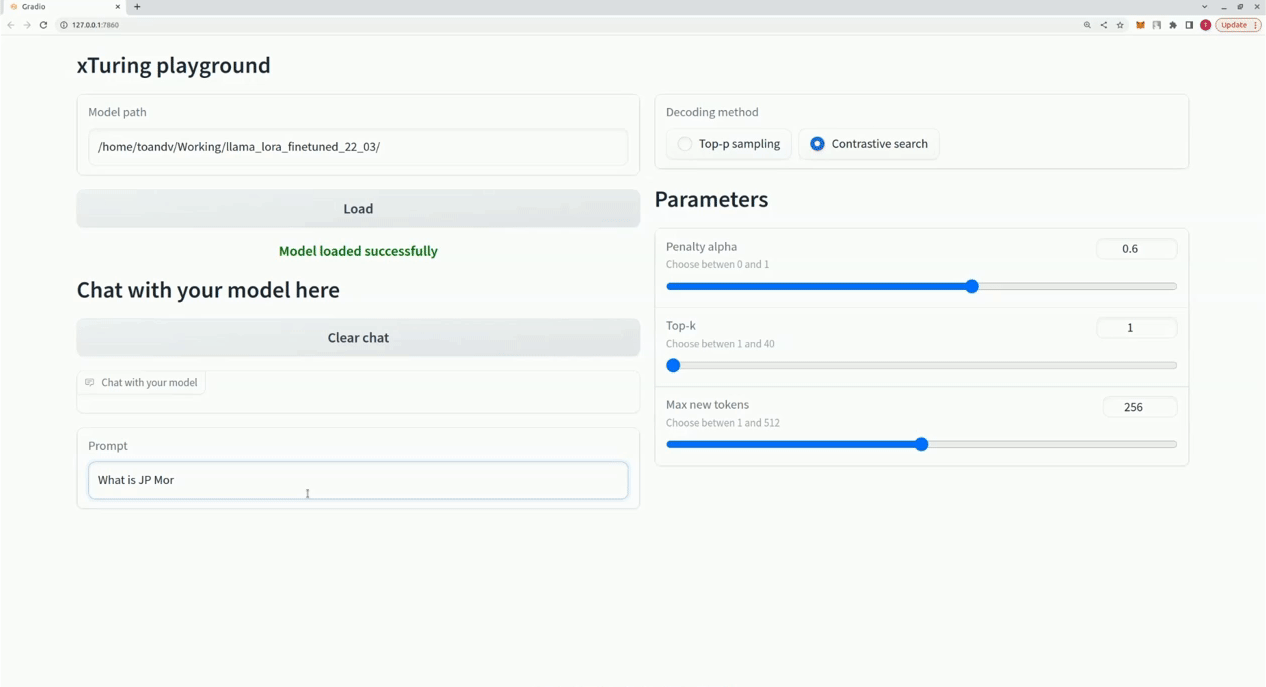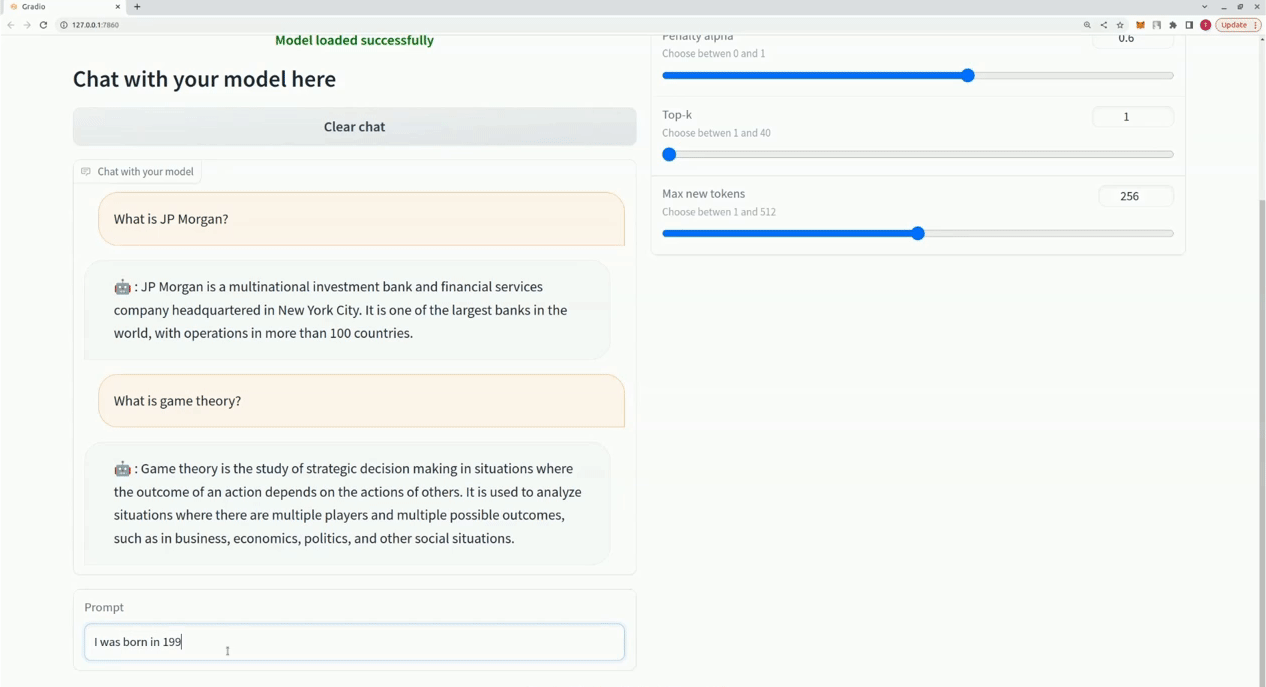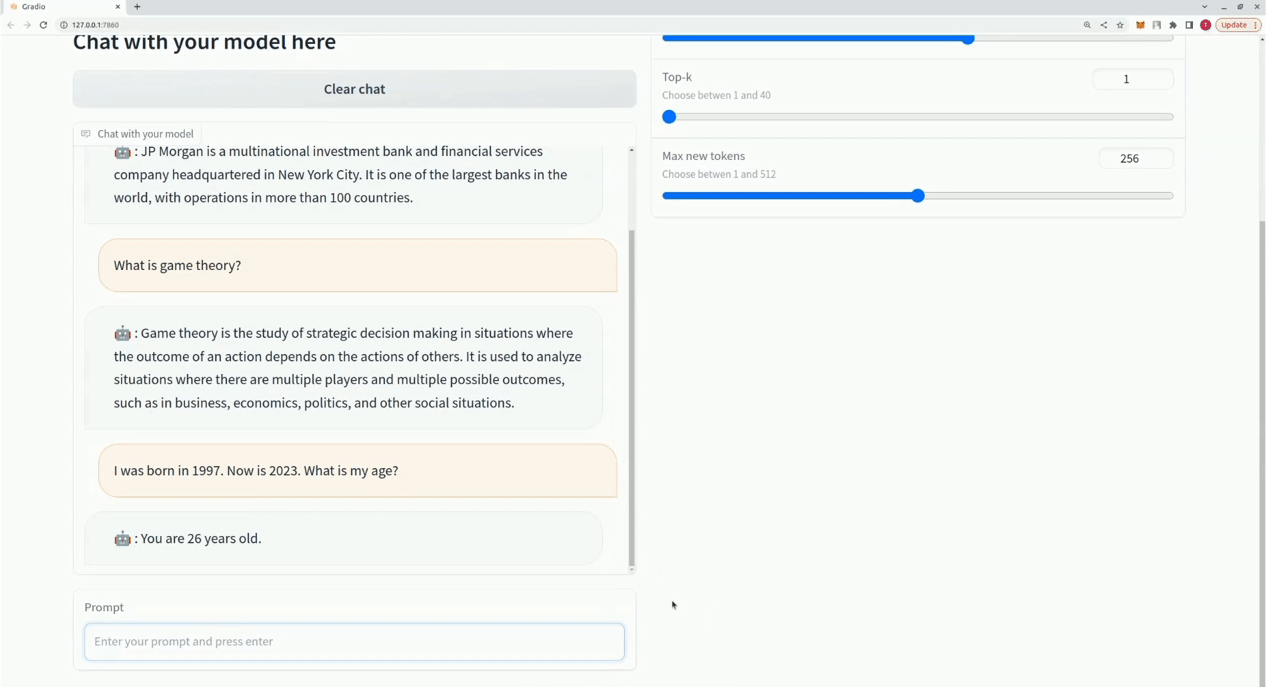
from xturing . datasets import InstructionDataset
from xturing . models import BaseModel
from xturing . ui import Playground
dataset = InstructionDataset ( "./alpaca_data" )
model = BaseModel . create ( "<model_name>" )
model . finetune ( dataset = dataset )
model . save ( "llama_lora_finetuned" )
Playground (). launch () ## launches localhost UI Hier ist ein Vergleich der Leistung verschiedener Feinabstimmungstechniken am LLaMA 7B-Modell. Zur Feinabstimmung nutzen wir den Alpaca-Datensatz. Der Datensatz enthält 52.000 Anweisungen.
Hardware:
4xA100 40 GB GPU, 335 GB CPU-RAM
Feinabstimmungsparameter:
{
'maximum sequence length' : 512 ,
'batch size' : 1 ,
}| LLaMA-7B | DeepSpeed + CPU-Offloading | LoRA + DeepSpeed | LoRA + DeepSpeed + CPU-Offloading |
|---|---|---|---|
| GPU | 33,5 GB | 23,7 GB | 21,9 GB |
| CPU | 190 GB | 10,2 GB | 14,9 GB |
| Zeit/Epoche | 21 Stunden | 20 Min | 20 Min |
Tragen Sie dazu bei, indem Sie Ihre Leistungsergebnisse auf anderen GPUs übermitteln, indem Sie ein Problem mit Ihren Hardwarespezifikationen, dem Speicherverbrauch und der Zeit pro Epoche verursachen.
Wir haben bereits einige Modelle verfeinert, die Sie als Basis verwenden oder mit denen Sie anfangen können zu spielen. So würden Sie sie laden:
from xturing . models import BaseModel
model = BaseModel . load ( "x/distilgpt2_lora_finetuned_alpaca" )| Modell | Datensatz | Weg |
|---|---|---|
| DistilGPT-2 LoRA | Alpaka | x/distilgpt2_lora_finetuned_alpaca |
| LLaMA LoRA | Alpaka | x/llama_lora_finetuned_alpaca |
Nachfolgend finden Sie eine Liste aller über die BaseModel Klasse von xTuring unterstützten Modelle und die entsprechenden Schlüssel zum Laden.
| Modell | Schlüssel |
|---|---|
| Blühen | blühen |
| Großhirn | Gehirne |
| DestillierenGPT-2 | destilgpt2 |
| Falcon-7B | Falke |
| Galactica | Galactica |
| GPT-J | gptj |
| GPT-2 | gpt2 |
| Lama | Lama |
| LlaMA2 | Lama2 |
| OPT-1.3B | opt |
Bei den oben genannten handelt es sich um die Basisvarianten der LLMs. Nachfolgend finden Sie die Vorlagen, um die Versionen LoRA , INT8 , INT8 + LoRA und INT4 + LoRA zu erhalten.
| Version | Vorlage |
|---|---|
| LoRA | <model_key>_lora |
| INT8 | <model_key>_int8 |
| INT8 + LoRA | <model_key>_lora_int8 |
** Um INT4+LoRA -Version eines beliebigen Modells zu laden, müssen Sie die Klasse GenericLoraKbitModel von xturing.models verwenden. Im Folgenden erfahren Sie, wie Sie es verwenden:
model = GenericLoraKbitModel ( '<model_path>' ) Der model_path kann durch Ihr lokales Verzeichnis oder ein beliebiges HuggingFace-Bibliotheksmodell wie facebook/opt-1.3b ersetzt werden.
LLaMA , GPT-J , GPT-2 , OPT , Cerebras-GPT , Galactica und Bloom Generic model Wrapper Falcon-7B Modell Wenn Sie Fragen haben, können Sie in diesem Repository ein Problem erstellen.
Sie können auch unserem Discord-Server beitreten und eine Diskussion im #xturing -Kanal starten.
Dieses Projekt ist unter der Apache-Lizenz 2.0 lizenziert – Einzelheiten finden Sie in der LIZENZ-Datei.
Als Open-Source-Projekt in einem sich schnell entwickelnden Bereich freuen wir uns über Beiträge aller Art, einschließlich neuer Funktionen und besserer Dokumentation. Bitte lesen Sie unseren Beitragsleitfaden, um zu erfahren, wie Sie sich beteiligen können.


