SynMeter
1.0.0

[24. November 2024] Wir fügen SynMeter einen neuen SOTA HP-Synthesizer REaLTabFormer hinzu! Probieren Sie es aus!
[18. September 2024] Wir fügen SynMeter einen neuen SOTA HP-Synthesizer TabSyn hinzu! Probieren Sie es aus!
Erstellen Sie eine neue Conda-Umgebung und richten Sie sie ein:
conda create -n synmeter python==3.9
conda activate synmeter
pip install -r requirements.txt # install dependencies
pip install -e . # package the library Ändern Sie das Basiswörterbuch in ./lib/info/ROOT_DIR :
ROOT_DIR = root_to_synmeter
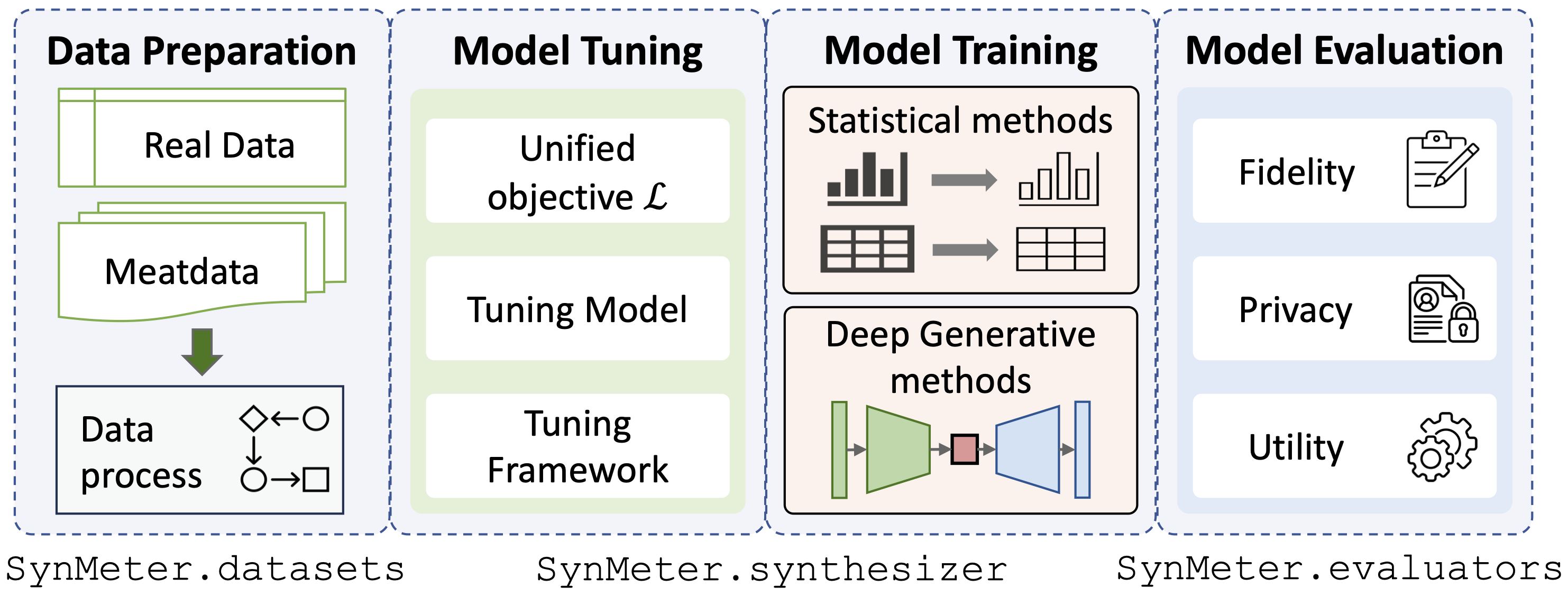
./dataset ablegen../exp/evaluators .python scripts/tune_evaluator.py -d [dataset] -c [cuda]Wir bieten ein einheitliches Tuning-Ziel für die Modelloptimierung, sodass alle Arten von Synthesizern mit nur einem einzigen Befehl abgestimmt werden können:
python scripts/tune_synthesizer.py -d [dataset] -m [synthesizer] -s [seed] -c [cuda] Nach dem Tuning sollte eine Konfiguration in /exp/dataset/synthesizer aufgezeichnet werden. SynMeter kann damit den Synthesizer trainieren und speichern:
python scripts/train_synthesizer.py -d [dataset] -m [synthesizer] -s [seed] -c [cuda]Beurteilung der Genauigkeit der synthetischen Daten:
python scripts/eval_fidelity.py -d [dataset] -m [synthesizer] -s [seed] -t [target] Beurteilung des Datenschutzes der synthetischen Daten:
python scripts/eval_privacy.py -d [dataset] -m [synthesizer] -s [seed]Bewertung des Nutzens der synthetischen Daten:
python scripts/eval_utility.py -d [dataset] -m [synthesizer] -s [seed] Die Ergebnisse der Auswertungen sollten unter dem entsprechenden Wörterbuch /exp/dataset/synthesizer gespeichert werden.
Ein Vorteil von SynMeter besteht darin, dass es die einfachste Möglichkeit zum Hinzufügen neuer Synthesealgorithmen bietet. Es sind drei Schritte erforderlich:
./synthesizer/my_synthesiszer./exp/base_config ../synthesizer eine aufrufende Python-Funktion, die drei Funktionen enthält: train , sample und tune .Dann steht es Ihnen frei, den neuen Synthesizer zu stimmen, zu betreiben und zu testen!
| Verfahren | Typ | Beschreibung | Referenz |
|---|---|---|---|
| MST | DP | Die Methode verwendet probabilistische grafische Modelle, um die Abhängigkeit niedrigdimensionaler Randzahlen für die Datensynthese zu lernen. | Papier, Code |
| PrivSyn | DP | Ein nichtparametrischer DP-Synthesizer, der den synthetischen Datensatz iterativ aktualisiert, damit er mit den Zielrauschgrenzen übereinstimmt. | Papier, Code |
| Verfahren | Typ | Beschreibung | Referenz |
|---|---|---|---|
| CTGAN | PS | Ein bedingtes generatives gegnerisches Netzwerk, das tabellarische Daten verarbeiten kann. | Papier, Code |
| PATE-GAN | DP | Die Methode nutzt das Private Aggregation of Teacher Ensembles (PATE)-Framework und wendet es auf GANs an. | Papier, Code |
| Verfahren | Typ | Beschreibung | Referenz |
|---|---|---|---|
| TVAE | PS | Ein bedingtes VAE-Netzwerk, das Tabellendaten verarbeiten kann. | Papier, Code |
| Verfahren | Typ | Beschreibung | Referenz |
|---|---|---|---|
| TabDDPM | PS | Verwenden Sie das Diffusionsmodell für die tabellarische Datensynthese | Papier, Code |
| TabSyn | PS | Verwenden Sie das latente Diffusionsmodell und VAE für die Synthese. | Papier, Code |
| TableDiffusion | DP | Generieren tabellarischer Datensätze unter differenzieller Privatsphäre. | Papier, Code |
| Verfahren | Typ | Beschreibung | Referenz |
|---|---|---|---|
| Großartig | PS | Verwenden Sie LLM zur Feinabstimmung eines tabellarischen Datensatzes. | Papier, Code |
| REaLTabFormer | PS | Verwenden Sie GPT-2, um die relationale Abhängigkeit von Tabellendaten zu lernen. | Papier, Code |
Treuemetriken : Wir betrachten die Wasserstein-Distanz als eine prinzipielle Treuemetrik, die aus allen ein- und zweiseitigen Randwerten berechnet wird.
Datenschutzmetriken : Wir entwickeln den Membership Disclosure Score (MDS), um die Datenschutzrisiken für Mitglieder von HP- und DP-Synthesizern zu messen.
Nutzenmetriken : Wir nutzen maschinelle Lernaffinität und Abfragefehler, um den Nutzen synthetischer Daten zu messen.
Einzelheiten und Verwendungsmöglichkeiten finden Sie in unserem Dokument.
In diesem Projekt werden viele hervorragende Synthesealgorithmen und Open-Source-Bibliotheken verwendet:


