SDV
v1.17.2 - 2024-11-18
Dieses Repository ist Teil des Synthetic Data Vault Project, einem Projekt von DataCebo.



Der Synthetic Data Vault (SDV) ist eine Python-Bibliothek, die als zentrale Anlaufstelle für die Erstellung tabellarischer synthetischer Daten konzipiert ist. Der SDV nutzt eine Vielzahl von Algorithmen für maschinelles Lernen, um Muster aus Ihren realen Daten zu lernen und diese in synthetischen Daten zu emulieren.
? Erstellen Sie synthetische Daten mithilfe von maschinellem Lernen. Der SDV bietet mehrere Modelle, die von klassischen statistischen Methoden (GaussianCopula) bis hin zu Deep-Learning-Methoden (CTGAN) reichen. Generieren Sie Daten für einzelne Tabellen, mehrere verbundene Tabellen oder sequentielle Tabellen.
Daten auswerten und visualisieren. Vergleichen Sie die synthetischen Daten anhand verschiedener Maßnahmen mit den realen Daten. Diagnostizieren Sie Probleme und erstellen Sie einen Qualitätsbericht, um weitere Erkenntnisse zu gewinnen.
Vorverarbeiten, anonymisieren und Einschränkungen definieren. Steuern Sie die Datenverarbeitung, um die Qualität synthetischer Daten zu verbessern, wählen Sie aus verschiedenen Anonymisierungsarten und definieren Sie Geschäftsregeln in Form von logischen Einschränkungen.
| Wichtige Links | |
|---|---|
 Tutorials Tutorials | Sammeln Sie praktische Erfahrungen mit dem SDV. Starten Sie die Tutorial-Notebooks und führen Sie den Code selbst aus. |
| Dokumente | Erfahren Sie anhand von Benutzerhandbüchern und API-Referenzen, wie Sie die SDV-Bibliothek verwenden. |
| ? Blog | Erhalten Sie weitere Einblicke in die Verwendung des SDV, die Bereitstellung von Modellen und unsere Community für synthetische Daten. |
 Gemeinschaft Gemeinschaft | Treten Sie unserem Slack-Workspace für Ankündigungen und Diskussionen bei. |
| Webseite | Weitere Informationen zum Projekt finden Sie auf der SDV-Website. |
Der SDV ist unter der Business Source-Lizenz öffentlich verfügbar. Installieren Sie SDV mit Pip oder Conda. Wir empfehlen die Verwendung einer virtuellen Umgebung, um Konflikte mit anderer Software auf Ihrem Gerät zu vermeiden.
pip install sdvconda install -c pytorch -c conda-forge sdvLaden Sie einen Demodatensatz, um loszulegen. Bei diesem Datensatz handelt es sich um eine einzelne Tabelle, die Gäste beschreibt, die in einem fiktiven Hotel übernachten.
from sdv . datasets . demo import download_demo
real_data , metadata = download_demo (
modality = 'single_table' ,
dataset_name = 'fake_hotel_guests' )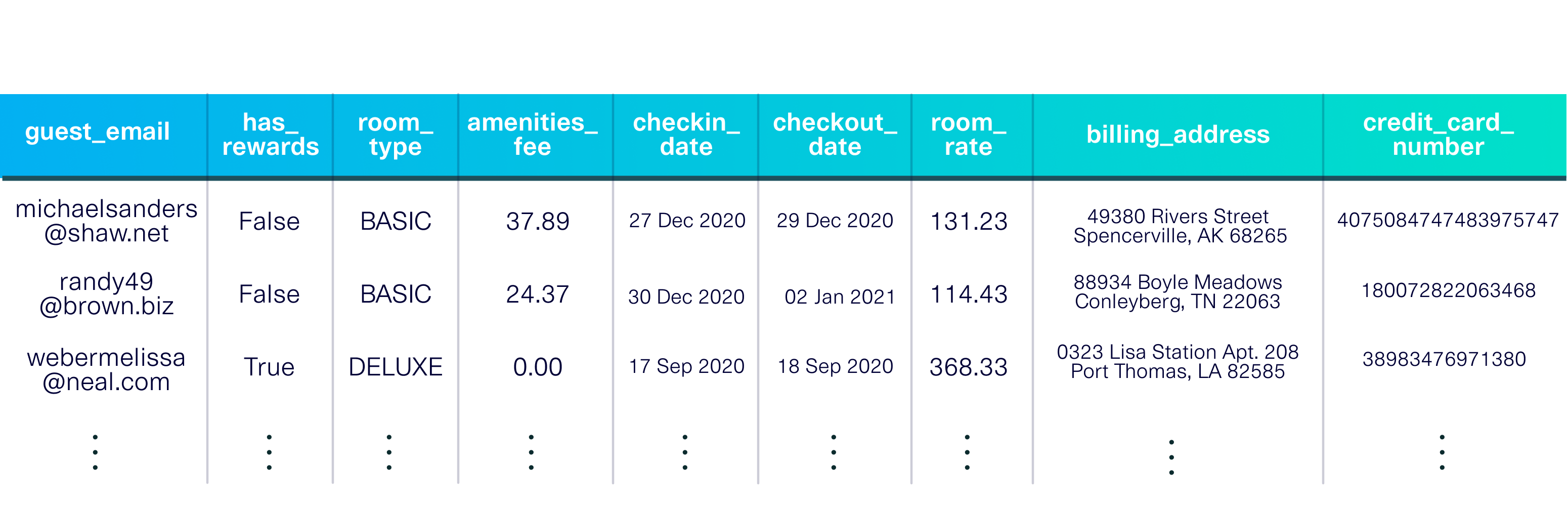
Die Demo enthält außerdem Metadaten , eine Beschreibung des Datensatzes, einschließlich der Datentypen in jeder Spalte und des Primärschlüssels ( guest_email ).
Als Nächstes können wir einen SDV-Synthesizer erstellen, ein Objekt, mit dem Sie synthetische Daten erstellen können. Es lernt Muster aus den realen Daten und repliziert sie, um synthetische Daten zu generieren. Lassen Sie uns den GaussianCopulaSynthesizer verwenden.
from sdv . single_table import GaussianCopulaSynthesizer
synthesizer = GaussianCopulaSynthesizer ( metadata )
synthesizer . fit ( data = real_data )Und jetzt ist der Synthesizer bereit, synthetische Daten zu erstellen!
synthetic_data = synthesizer . sample ( num_rows = 500 )Die synthetischen Daten haben die folgenden Eigenschaften:
Mit der SDV-Bibliothek können Sie die synthetischen Daten auswerten, indem Sie sie mit den realen Daten vergleichen. Beginnen Sie mit der Erstellung eines Qualitätsberichts.
from sdv . evaluation . single_table import evaluate_quality
quality_report = evaluate_quality (
real_data ,
synthetic_data ,
metadata ) Generating report ...
(1/2) Evaluating Column Shapes: |████████████████| 9/9 [00:00<00:00, 1133.09it/s]|
Column Shapes Score: 89.11%
(2/2) Evaluating Column Pair Trends: |██████████████████████████████████████████| 36/36 [00:00<00:00, 502.88it/s]|
Column Pair Trends Score: 88.3%
Overall Score (Average): 88.7%
Dieses Objekt berechnet eine Gesamtqualitätsbewertung auf einer Skala von 0 bis 100 % (100 ist die beste) sowie detaillierte Aufschlüsselungen. Für weitere Einblicke können Sie auch die synthetischen und realen Daten visualisieren.
from sdv . evaluation . single_table import get_column_plot
fig = get_column_plot (
real_data = real_data ,
synthetic_data = synthetic_data ,
column_name = 'amenities_fee' ,
metadata = metadata
)
fig . show ()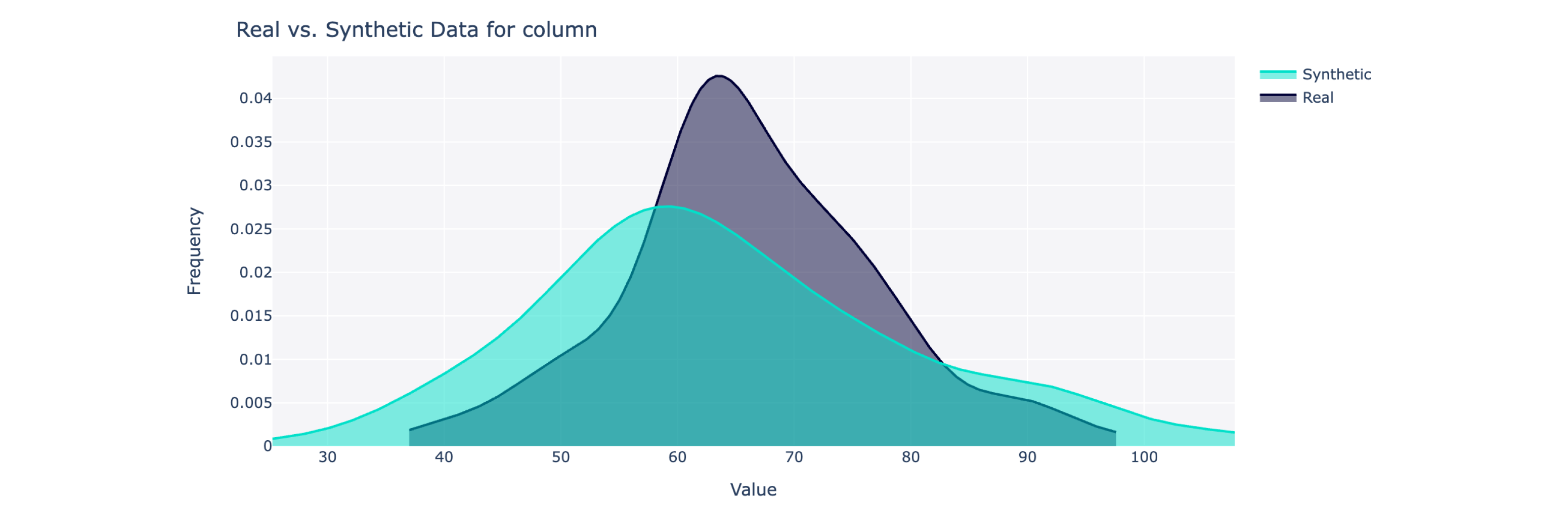
Mit der SDV-Bibliothek können Sie Einzeltabellen-, Mehrtabellen- und sequentielle Daten synthetisieren. Sie können auch den gesamten Workflow für synthetische Daten anpassen, einschließlich Vorverarbeitung, Anonymisierung und Hinzufügen von Einschränkungen.
Um mehr zu erfahren, besuchen Sie die SDV-Demoseite.
Vielen Dank an unser Team von Mitwirkenden, die im Laufe der Jahre das SDV-Ökosystem aufgebaut und gepflegt haben!
Mitwirkende anzeigen
Wenn Sie SDV für Ihre Forschung nutzen, zitieren Sie bitte das folgende Papier:
Neha Patki, Roy Wedge, Kalyan Veeramachaneni . Der synthetische Datentresor. IEEE DSAA 2016.
@inproceedings{
SDV,
title={The Synthetic data vault},
author={Patki, Neha and Wedge, Roy and Veeramachaneni, Kalyan},
booktitle={IEEE International Conference on Data Science and Advanced Analytics (DSAA)},
year={2016},
pages={399-410},
doi={10.1109/DSAA.2016.49},
month={Oct}
}
Das Synthetic Data Vault-Projekt wurde erstmals 2016 im Data to AI Lab des MIT ins Leben gerufen. Nach vier Jahren Forschung und Zusammenarbeit mit Unternehmen gründeten wir 2020 DataCebo mit dem Ziel, das Projekt auszubauen. Heute ist DataCebo stolzer Entwickler von SDV, dem größten Ökosystem für die Generierung und Auswertung synthetischer Daten. Es beherbergt mehrere Bibliotheken, die synthetische Daten unterstützen, darunter:
Beginnen Sie mit der Nutzung des SDV-Pakets – einer vollständig integrierten Lösung und Ihrem One-Stop-Shop für synthetische Daten. Oder nutzen Sie die eigenständigen Bibliotheken für spezifische Anforderungen.


