LipGER
Initial Release
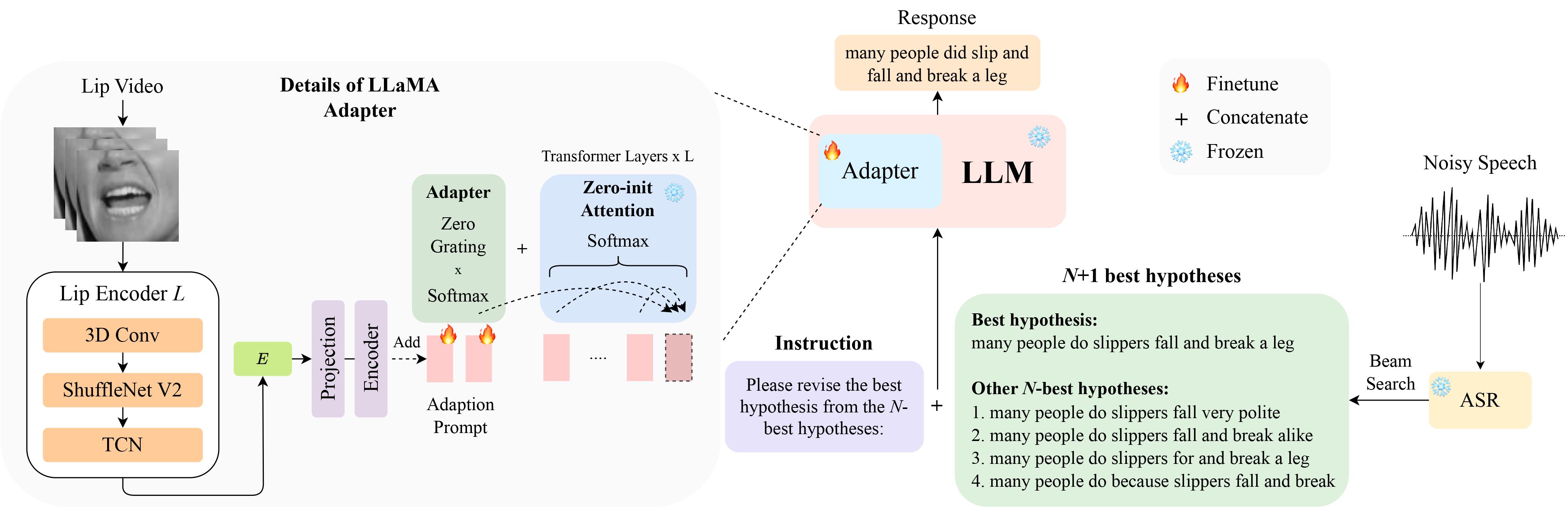
Dies ist die offizielle Implementierung für unseren Beitrag LipGER: Visually-Conditioned Generative Error Correction for Robust Automatic Speech Recognition auf der InterSpeech 2024, der für die mündliche Präsentation ausgewählt wurde.
Die LipHyp-Daten können Sie hier herunterladen!
pip install -r requirements.txt
Bereiten Sie zunächst die Kontrollpunkte vor, indem Sie Folgendes verwenden:
pip install huggingface_hub
python scripts/download.py --repo_id meta-llama/Llama-2-7b-chat-hf --token your_hf_token
python scripts/convert_hf_checkpoint.py --checkpoint_dir checkpoints/meta-llama/Llama-2-7b-chat-hfUm alle verfügbaren Prüfpunkte anzuzeigen, führen Sie Folgendes aus:
python scripts/download.py | grep Llama-2Für weitere Details können Sie auch auf diesen Link verweisen, wo Sie auch andere Kontrollpunkte für andere Modelle vorbereiten können. Konkret verwenden wir TinyLlama für unsere Experimente.
Der Kontrollpunkt ist hier verfügbar. Ändern Sie nach dem Download hier den Pfad des Checkpoints.
LipGER erwartet, dass alle Trainings-, Validierungs- und Testdateien das Format „sample_data.json“ haben. Eine Instanz in der Datei sieht folgendermaßen aus:
{
"Dataset": "dataset_name",
"Uid": "unique_id",
"Caption": "The ground truth transcription.",
"Noisy_Wav": "path_to_noisy_wav",
"Mouthroi": "path_to_mouth_roi_mp4",
"Video": "path_to_video_mp4",
"nhyps_base": [ list of N-best hypotheses ],
}
Sie müssen die Sprachdateien durch ein trainiertes ASR-Modell leiten, das in der Lage ist, N-beste Hypothesen zu generieren. Wir bieten in diesem Repo zwei Möglichkeiten, die Ihnen dabei helfen, dies zu erreichen. Fühlen Sie sich frei, andere Methoden zu verwenden.
pip install whisper installieren und dann nhyps.py aus dem data ausführen, sollte alles in Ordnung sein! Beachten Sie, dass bei beiden Methoden die erste in der Liste die beste Hypothese und die anderen die N-besten Hypothesen sind (sie werden als Listenfeld nhyps_base des JSON übergeben und zum Erstellen einer Eingabeaufforderung in den nächsten Schritten verwendet).
Darüber hinaus verwenden die bereitgestellten Methoden nur Sprache als Eingabe. Für die Erstellung audiovisueller N-Best-Hypothesen haben wir Auto-AVSR verwendet. Wenn Sie Hilfe mit dem Code benötigen, melden Sie bitte ein Problem!
Vorausgesetzt, Sie verfügen über entsprechende Videos für alle Ihre Sprachdateien, befolgen Sie diese Schritte, um den Mund-ROI aus den Videos zu beschneiden.
python crop_mouth_script.py
python covert_lip.py
Dadurch wird der MP4-ROI in HDF5 konvertiert. Der Code ändert den Pfad von MP4-ROI in HDF5-ROI in derselben JSON-Datei. Sie können zwischen den Detektoren „mediapipe“ und „retinaface“ wählen, indem Sie den „detector“ in default.yaml ändern
Nachdem Sie die N-besten Hypothesen haben, erstellen Sie die JSON-Datei im erforderlichen Format. Wir stellen für diesen Teil keinen spezifischen Code bereit, da die Datenvorbereitung für jeden unterschiedlich sein kann, aber der Code sollte einfach sein. Sprechen Sie noch einmal ein Problem an, wenn Sie irgendwelche Zweifel haben!
LipGER-Trainingsskripte nutzen JSON nicht für Training oder Evaluierung. Sie müssen sie in eine pt-Datei konvertieren. Sie können „convert_to_pt.py“ ausführen, um dies zu erreichen! Ändern Sie model_name nach Ihren Wünschen in Zeile 27 und fügen Sie in Zeile 58 den Pfad zu Ihrem JSON hinzu.
Um LipGER zu verfeinern, führen Sie einfach Folgendes aus:
sh finetune.sh
Hier müssen Sie die Werte für data (mit dem Namen des Datensatzes), --train_path und --val_path (mit absoluten Pfaden zum Trainieren und gültigen .pt-Dateien) manuell festlegen.
Als Schlussfolgerung ändern Sie zunächst die entsprechenden Pfade in lipger.py ( exp_path und checkpoint_dir ) und führen Sie dann aus (mit dem entsprechenden Testdatenpfadargument):
sh infer.sh
Der Code zum Beschneiden des Mund-ROI ist von Visual_Speech_Recognition_for_Multiple_Languages inspiriert.
Unser Code für LipGER ist von RobustGER inspiriert. Bitte zitieren Sie auch deren Artikel, wenn Sie unseren Artikel oder Kodex nützlich finden.
@inproceedings{ghosh23b_interspeech,
author={Sreyan Ghosh and Sonal Kumar and Ashish Seth and Purva Chiniya and Utkarsh Tyagi and Ramani Duraiswami and Dinesh Manocha},
title={{LipGER: Visually-Conditioned Generative Error Correction for Robust Automatic Speech Recognition}},
year=2024,
booktitle={Proc. INTERSPEECH 2024},
}


