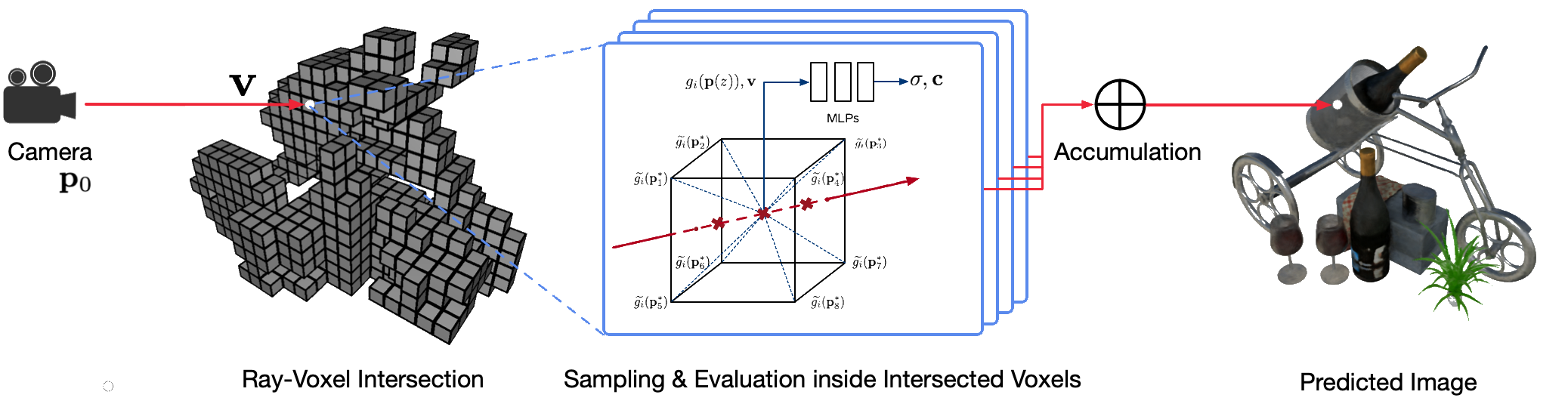
Die fotorealistische Darstellung realer Szenen aus freiem Blickwinkel mithilfe klassischer Computergrafiktechniken ist ein anspruchsvolles Problem, da hierfür der schwierige Schritt der Erfassung detaillierter Erscheinungsbild- und Geometriemodelle erforderlich ist. Neuronales Rendering ist ein aufstrebendes Feld, das tiefe neuronale Netze nutzt, um implizit Szenendarstellungen zu lernen, die sowohl Geometrie als auch Aussehen aus 2D-Beobachtungen mit oder ohne grobe Geometrie umfassen. Bestehende Ansätze in diesem Bereich zeigen jedoch häufig verschwommene Darstellungen oder leiden unter einem langsamen Darstellungsprozess. Wir schlagen Neural Sparse Voxel Fields (NSVF) vor, eine neue neuronale Szenendarstellung für schnelles und qualitativ hochwertiges Rendern aus freiem Blickwinkel.
Hier ist das offizielle Repo für das Papier:
Wir bieten auch unsere inoffizielle Implementierung für:
Dieser Code wird in PyTorch mithilfe des Fairseq-Frameworks implementiert.
Der Code wurde auf dem folgenden System getestet:
Es werden nur Lernen und Rendern auf GPUs unterstützt.
Klonen Sie zur Installation zunächst dieses Repo und installieren Sie alle Abhängigkeiten:
pip install -r requirements.txtDann lauf
pip install --editable ./Oder wenn Sie den Code lokal installieren möchten, führen Sie Folgendes aus:
python setup.py build_ext --inplaceSie können die in unserem Artikel verwendeten vorverarbeiteten synthetischen und realen Datensätze herunterladen. Bitte zitieren Sie auch die Originalarbeiten, wenn Sie diese in Ihrer Arbeit verwenden.
| Datensatz | Download-Link | Hinweise zur Datensatzaufteilung |
|---|---|---|
| Synthetischer NSVF | herunterladen (.zip) | 0_* (Training) 1_* (Validierung) 2_* (Testen) |
| Synthetisches NeRF | herunterladen (.zip) | 0_* (Training) 1_* (Validierung) 2_* (Testen) |
| BlendedMVS | herunterladen (.zip) | 0_* (Training) 1_* (Testen) |
| Panzer und Tempel | herunterladen (.zip) | 0_* (Training) 1_* (Testen) |
Um einen neuen Datensatz einer einzelnen Szene für Training und Tests vorzubereiten, befolgen Sie bitte die Datenstruktur:
< dataset_name >
| -- bbox.txt # bounding-box file
| -- intrinsics.txt # 4x4 camera intrinsics
| -- rgb
| -- 0.png # target image for each view
| -- 1.png
...
| -- pose
| -- 0.txt # camera pose for each view (4x4 matrices)
| -- 1.txt
...
[optional]
| -- test_traj.txt # camera pose for free-view rendering demonstration (4N x 4) Dabei enthält die Datei bbox.txt eine Zeile, die den anfänglichen Begrenzungsrahmen und die Voxelgröße beschreibt:
x_min y_min z_min x_max y_max z_max initial_voxel_size Beachten Sie, dass die Dateinamen der Zielbilder und der entsprechenden Kamera-Pose-Dateien nicht exakt identisch sein müssen. Allerdings müssen die Reihenfolgen dieser beiden Arten von Dateien (sortiert nach Zeichenfolge) übereinstimmen. Die Datensätze werden mit Ansichtsindizes aufgeteilt. Beispielsweise bedeuten „ train (0..100) , valid (100..200) und test (200..400) “ die ersten 100 Aufrufe für das Training, 100–199. Aufrufe für die Validierung und 200–399. Aufrufe für Tests .
Angesichts des Datensatzes einer einzelnen Szene ( {DATASET} ) verwenden wir den folgenden Befehl zum Trainieren eines NSVF-Modells, um neuartige Ansichten mit 800x800 Pixeln, mit einer Stapelgröße von 4 Bildern pro GPU und 2048 Strahlen pro Bild zu synthetisieren. Standardmäßig erkennt der Code automatisch alle verfügbaren GPUs.
Im folgenden Beispiel verwenden wir eine vordefinierte Architektur nsvf_base mit spezifischen Argumenten:
--no-sampling-at-reader tastet das Modell für das Training nur Pixel im projizierten Bildbereich dünn besetzter Voxel ab.1/8 (0.125) der Voxelgröße fest, die normalerweise in der Datei bbox.txt beschrieben wird.--use-octree zu aktivieren. Es wird ein dünn besetzter Voxel-Octree erstellt, um den Strahl-Voxel-Schnittpunkt zu beschleunigen, insbesondere wenn die Anzahl der Voxel größer als 10000 ist.--pruning-every-steps auf 2500 führt das Modell alle 2500 Schritte eine Selbstbereinigung durch.--half-voxel-size-at und --reduce-step-size-at auf 5000,25000,75000 werden die Voxelgröße und die Schrittgröße auf 5k , 25k bzw. 75k halbiert.Beachten Sie, dass die oben genannten Parametereinstellungen zwar für die meisten Experimente in der Arbeit verwendet werden, es jedoch möglich ist, diese Parameter anzupassen, um eine bessere Qualität zu erzielen. Neben den oben genannten Parametern können auch andere Parameter Standardeinstellungen verwenden.
Neben der Architektur nsvf_base können Sie in der Datei fairnr/models/nsvf.py auch andere Architekturen überprüfen oder Ihre eigenen Architekturen definieren.
python -u train.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--train-views " 0..100 " --view-resolution " 800x800 "
--max-sentences 1 --view-per-batch 4 --pixel-per-view 2048
--no-preload
--sampling-on-mask 1.0 --no-sampling-at-reader
--valid-views " 100..200 " --valid-view-resolution " 400x400 "
--valid-view-per-batch 1
--transparent-background " 1.0,1.0,1.0 " --background-stop-gradient
--arch nsvf_base
--initial-boundingbox ${DATASET} /bbox.txt
--use-octree
--raymarching-stepsize-ratio 0.125
--discrete-regularization
--color-weight 128.0 --alpha-weight 1.0
--optimizer " adam " --adam-betas " (0.9, 0.999) "
--lr 0.001 --lr-scheduler " polynomial_decay " --total-num-update 150000
--criterion " srn_loss " --clip-norm 0.0
--num-workers 0
--seed 2
--save-interval-updates 500 --max-update 150000
--virtual-epoch-steps 5000 --save-interval 1
--half-voxel-size-at " 5000,25000,75000 "
--reduce-step-size-at " 5000,25000,75000 "
--pruning-every-steps 2500
--keep-interval-updates 5 --keep-last-epochs 5
--log-format simple --log-interval 1
--save-dir ${SAVE}
--tensorboard-logdir ${SAVE} /tensorboard
| tee -a $SAVE /train.log Die Kontrollpunkte werden in {SAVE} gespeichert. Sie können Tensorboard starten, um den Trainingsfortschritt zu überprüfen:
tensorboard --logdir= ${SAVE} /tensorboard --port=10000Weitere Beispiele für Trainingsskripte zur Reproduktion der Ergebnisse unserer Arbeit finden Sie unter Beispiele.
Sobald das Modell trainiert ist, wird der folgende Befehl verwendet, um die Rendering-Qualität der Testansichten mit dem angegebenen {MODEL_PATH} zu bewerten.
python validate.py ${DATASET}
--user-dir fairnr
--valid-views " 200..400 "
--valid-view-resolution " 800x800 "
--no-preload
--task single_object_rendering
--max-sentences 1
--valid-view-per-batch 1
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01,"tensorboard_logdir":"","eval_lpips":True} ' Beachten Sie, dass wir raymarching_tolerance auf 0.01 überschreiben, um eine vorzeitige Beendigung zur Beschleunigung des Renderings zu ermöglichen.
Das Rendern aus freier Sicht kann erreicht werden, sobald ein Modell trainiert und eine Rendering-Trajektorie angegeben wird. Der folgende Befehl dient beispielsweise zum Rendern mit einer kreisförmigen Flugbahn (Winkelgeschwindigkeit 3 Grad/Frame, 15 Frames pro GPU). Dadurch werden pro Ansicht gerenderte Bilder ausgegeben und die Bilder wie folgt in einem .mp4 Video in ${SAVE}/output zusammengeführt:

Standardmäßig kann der Code alle verfügbaren GPUs erkennen.
python render.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01} '
--render-beam 1 --render-angular-speed 3 --render-num-frames 15
--render-save-fps 24
--render-resolution " 800x800 "
--render-path-style " circle "
--render-path-args " {'radius': 3, 'h': 2, 'axis': 'z', 't0': -2, 'r':-1} "
--render-output ${SAVE} /output
--render-output-types " color " " depth " " voxel " " normal " --render-combine-output
--log-format " simple " Unser Code unterstützt auch das Rendern für bestimmte Kameraposen. Der folgende Befehl dient beispielsweise zum Rendern mit den Kameraposen, die in den Dateien 200–399 im Ordner ${DATASET}/pose definiert sind:
python render.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01} '
--render-save-fps 24
--render-resolution " 800x800 "
--render-camera-poses ${DATASET} /pose
--render-views " 200..400 "
--render-output ${SAVE} /output
--render-output-types " color " " depth " " voxel " " normal " --render-combine-output
--log-format " simple " Der Code unterstützt auch das Rendern mit Kamerapositionen, die in einer .txt Datei definiert sind. Bitte beziehen Sie sich auf dieses Beispiel.
Wir unterstützen auch die Ausführung von Marschwürfeln, um die Isoflächen als Dreiecksnetze aus einem trainierten NSVF-Modell zu extrahieren und als {SAVE}/{NAME}.ply zu speichern.
python extract.py
--user-dir fairnr
--path ${MODEL_PATH}
--output ${SAVE}
--name ${NAME}
--format ' mc_mesh '
--mc-threshold 0.5
--mc-num-samples-per-halfvoxel 5 Es ist auch möglich, die gelernten Sparse-Voxel zu exportieren, indem Sie --format 'voxel_mesh' festlegen. Die ausgegebene .ply Datei kann mit jedem 3D-Viewer wie MeshLab geöffnet werden.

NSVF ist MIT-lizenziert. Die Lizenz gilt auch für die vorab trainierten Modelle.
Bitte zitieren als
@article { liu2020neural ,
title = { Neural Sparse Voxel Fields } ,
author = { Liu, Lingjie and Gu, Jiatao and Lin, Kyaw Zaw and Chua, Tat-Seng and Theobalt, Christian } ,
journal = { NeurIPS } ,
year = { 2020 }
}

